 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable LLM-Based Edge-Cloud-Expert Cascades for Telecom Knowledge Systems
Dec 23, 2025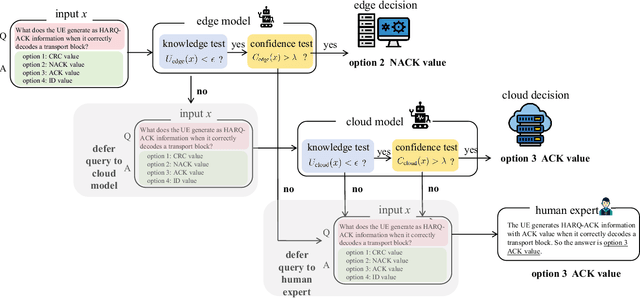
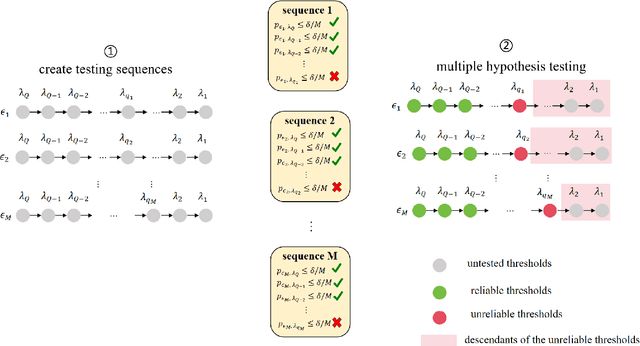
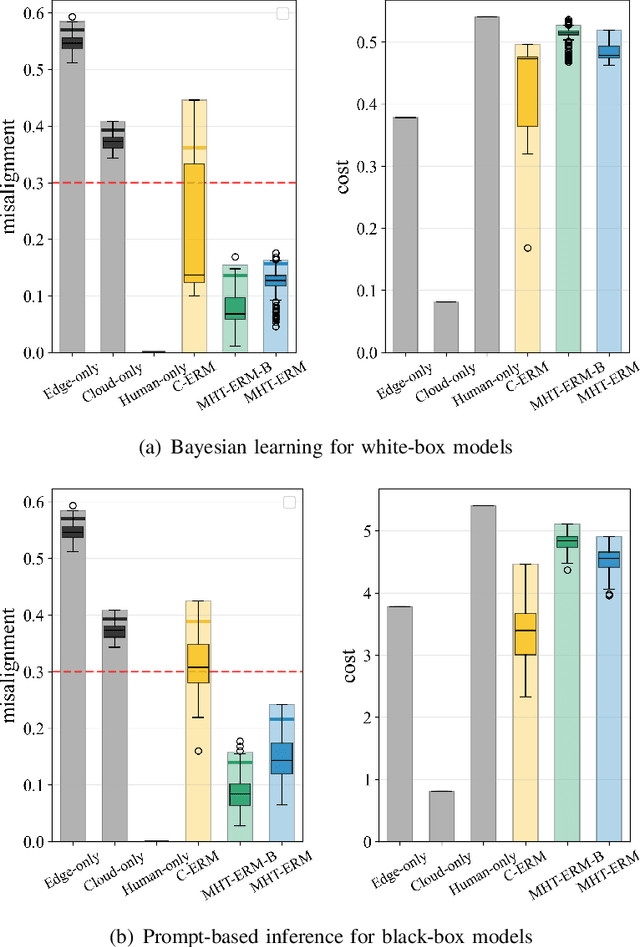
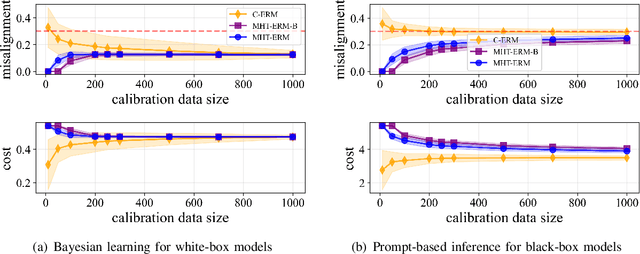
Large language models (LLMs) are emerging as key enablers of automation in domains such as telecommunications, assisting with tasks including troubleshooting, standards interpretation, and network optimization. However, their deployment in practice must balance inference cost, latency, and reliability. In this work, we study an edge-cloud-expert cascaded LLM-based knowledge system that supports decision-making through a question-and-answer pipeline. In it, an efficient edge model handles routine queries, a more capable cloud model addresses complex cases, and human experts are involved only when necessary. We define a misalignment-cost constrained optimization problem, aiming to minimize average processing cost, while guaranteeing alignment of automated answers with expert judgments. We propose a statistically rigorous threshold selection method based on multiple hypothesis testing (MHT) for a query processing mechanism based on knowledge and confidence tests. The approach provides finite-sample guarantees on misalignment risk. Experiments on the TeleQnA dataset -- a telecom-specific benchmark -- demonstrate that the proposed method achieves superior cost-efficiency compared to conventional cascaded baselines, while ensuring reliability at prescribed confidence levels.
Distributed Associative Memory via Online Convex Optimization
Sep 26, 2025An associative memory (AM) enables cue-response recall, and associative memorization has recently been noted to underlie the operation of modern neural architectures such as Transformers. This work addresses a distributed setting where agents maintain a local AM to recall their own associations as well as selective information from others. Specifically, we introduce a distributed online gradient descent method that optimizes local AMs at different agents through communication over routing trees. Our theoretical analysis establishes sublinear regret guarantees, and experiments demonstrate that the proposed protocol consistently outperforms existing online optimization baselines.
Synthetic Counterfactual Labels for Efficient Conformal Counterfactual Inference
Sep 04, 2025This work addresses the problem of constructing reliable prediction intervals for individual counterfactual outcomes. Existing conformal counterfactual inference (CCI) methods provide marginal coverage guarantees but often produce overly conservative intervals, particularly under treatment imbalance when counterfactual samples are scarce. We introduce synthetic data-powered CCI (SP-CCI), a new framework that augments the calibration set with synthetic counterfactual labels generated by a pre-trained counterfactual model. To ensure validity, SP-CCI incorporates synthetic samples into a conformal calibration procedure based on risk-controlling prediction sets (RCPS) with a debiasing step informed by prediction-powered inference (PPI). We prove that SP-CCI achieves tighter prediction intervals while preserving marginal coverage, with theoretical guarantees under both exact and approximate importance weighting. Empirical results on different datasets confirm that SP-CCI consistently reduces interval width compared to standard CCI across all settings.
In-Context Learning for Gradient-Free Receiver Adaptation: Principles, Applications, and Theory
Jun 18, 2025In recent years, deep learning has facilitated the creation of wireless receivers capable of functioning effectively in conditions that challenge traditional model-based designs. Leveraging programmable hardware architectures, deep learning-based receivers offer the potential to dynamically adapt to varying channel environments. However, current adaptation strategies, including joint training, hypernetwork-based methods, and meta-learning, either demonstrate limited flexibility or necessitate explicit optimization through gradient descent. This paper presents gradient-free adaptation techniques rooted in the emerging paradigm of in-context learning (ICL). We review architectural frameworks for ICL based on Transformer models and structured state-space models (SSMs), alongside theoretical insights into how sequence models effectively learn adaptation from contextual information. Further, we explore the application of ICL to cell-free massive MIMO networks, providing both theoretical analyses and empirical evidence. Our findings indicate that ICL represents a principled and efficient approach to real-time receiver adaptation using pilot signals and auxiliary contextual information-without requiring online retraining.
Adaptive Prediction-Powered AutoEval with Reliability and Efficiency Guarantees
May 24, 2025Selecting artificial intelligence (AI) models, such as large language models (LLMs), from multiple candidates requires accurate performance estimation. This is ideally achieved through empirical evaluations involving abundant real-world data. However, such evaluations are costly and impractical at scale. To address this challenge, autoevaluation methods leverage synthetic data produced by automated evaluators, such as LLMs-as-judges, reducing variance but potentially introducing bias. Recent approaches have employed semi-supervised prediction-powered inference (\texttt{PPI}) to correct for the bias of autoevaluators. However, the use of autoevaluators may lead in practice to a degradation in sample efficiency compared to conventional methods using only real-world data. In this paper, we propose \texttt{R-AutoEval+}, a novel framework that provides finite-sample reliability guarantees on the model evaluation, while also ensuring an enhanced (or at least no worse) sample efficiency compared to conventional methods. The key innovation of \texttt{R-AutoEval+} is an adaptive construction of the model evaluation variable, which dynamically tunes its reliance on synthetic data, reverting to conventional methods when the autoevaluator is insufficiently accurate. Experiments on the use of LLMs-as-judges for the optimization of quantization settings for the weights of an LLM, and for prompt design in LLMs confirm the reliability and efficiency of \texttt{R-AutoEval+}.
Turbo-ICL: In-Context Learning-Based Turbo Equalization
May 09, 2025This paper introduces a novel in-context learning (ICL) framework, inspired by large language models (LLMs), for soft-input soft-output channel equalization in coded multiple-input multiple-output (MIMO) systems. The proposed approach learns to infer posterior symbol distributions directly from a prompt of pilot signals and decoder feedback. A key innovation is the use of prompt augmentation to incorporate extrinsic information from the decoder output as additional context, enabling the ICL model to refine its symbol estimates iteratively across turbo decoding iterations. Two model variants, based on Transformer and state-space architectures, are developed and evaluated. Extensive simulations demonstrate that, when traditional linear assumptions break down, e.g., in the presence of low-resolution quantization, ICL equalizers consistently outperform conventional model-based baselines, even when the latter are provided with perfect channel state information. Results also highlight the advantage of Transformer-based models under limited training diversity, as well as the efficiency of state-space models in resource-constrained scenarios.
Conformal Calibration: Ensuring the Reliability of Black-Box AI in Wireless Systems
Apr 16, 2025AI is poised to revolutionize telecommunication networks by boosting efficiency, automation, and decision-making. However, the black-box nature of most AI models introduces substantial risk, possibly deterring adoption by network operators. These risks are not addressed by the current prevailing deployment strategy, which typically follows a best-effort train-and-deploy paradigm. This paper reviews conformal calibration, a general framework that moves beyond the state of the art by adopting computationally lightweight, advanced statistical tools that offer formal reliability guarantees without requiring further training or fine-tuning. Conformal calibration encompasses pre-deployment calibration via uncertainty quantification or hyperparameter selection; online monitoring to detect and mitigate failures in real time; and counterfactual post-deployment performance analysis to address "what if" diagnostic questions after deployment. By weaving conformal calibration into the AI model lifecycle, network operators can establish confidence in black-box AI models as a dependable enabling technology for wireless systems.
Online Conformal Probabilistic Numerics via Adaptive Edge-Cloud Offloading
Mar 18, 2025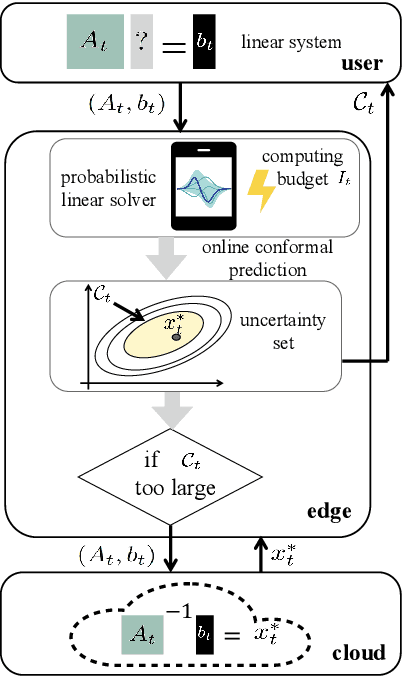
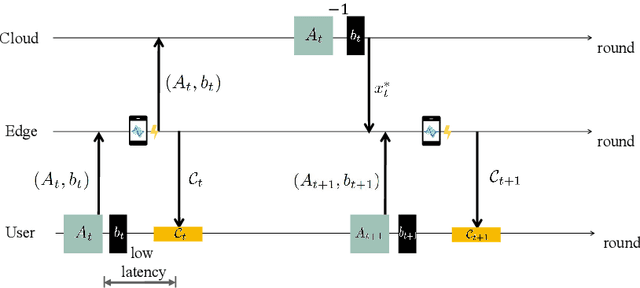
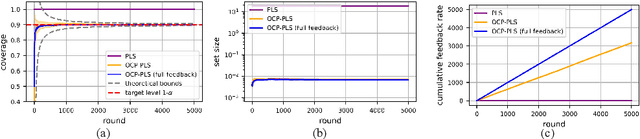
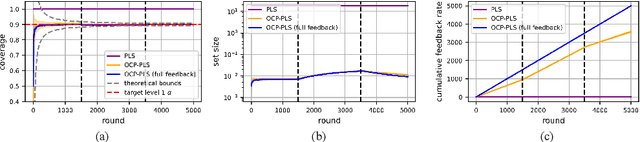
Consider an edge computing setting in which a user submits queries for the solution of a linear system to an edge processor, which is subject to time-varying computing availability. The edge processor applies a probabilistic linear solver (PLS) so as to be able to respond to the user's query within the allotted time and computing budget. Feedback to the user is in the form of an uncertainty set. Due to model misspecification, the uncertainty set obtained via a direct application of PLS does not come with coverage guarantees with respect to the true solution of the linear system. This work introduces a new method to calibrate the uncertainty sets produced by PLS with the aim of guaranteeing long-term coverage requirements. The proposed method, referred to as online conformal prediction-PLS (OCP-PLS), assumes sporadic feedback from cloud to edge. This enables the online calibration of uncertainty thresholds via online conformal prediction (OCP), an online optimization method previously studied in the context of prediction models. The validity of OCP-PLS is verified via experiments that bring insights into trade-offs between coverage, prediction set size, and cloud usage.
Mirror Online Conformal Prediction with Intermittent Feedback
Mar 13, 2025Online conformal prediction enables the runtime calibration of a pre-trained artificial intelligence model using feedback on its performance. Calibration is achieved through set predictions that are updated via online rules so as to ensure long-term coverage guarantees. While recent research has demonstrated the benefits of incorporating prior knowledge into the calibration process, this has come at the cost of replacing coverage guarantees with less tangible regret guarantees based on the quantile loss. This work introduces intermittent mirror online conformal prediction (IM-OCP), a novel runtime calibration framework that integrates prior knowledge, while maintaining long-term coverage and achieving sub-linear regret. IM-OCP features closed-form updates with minimal memory complexity, and is designed to operate under potentially intermittent feedback.
Online Conformal Compression for Zero-Delay Communication with Distortion Guarantees
Mar 11, 2025We investigate a lossy source compression problem in which both the encoder and decoder are equipped with a pre-trained sequence predictor. We propose an online lossy compression scheme that, under a 0-1 loss distortion function, ensures a deterministic, per-sequence upper bound on the distortion (outage) level for any time instant. The outage guarantees apply irrespective of any assumption on the distribution of the sequences to be encoded or on the quality of the predictor at the encoder and decoder. The proposed method, referred to as online conformal compression (OCC), is built upon online conformal prediction--a novel method for constructing confidence intervals for arbitrary predictors. Numerical results show that OCC achieves a compression rate comparable to that of an idealized scheme in which the encoder, with hindsight, selects the optimal subset of symbols to describe to the decoder, while satisfying the overall outage constraint.