 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured State-Space Regularization for Compact and Generation-Friendly Image Tokenization
Apr 13, 2026Image tokenizers are central to modern vision models as they often operate in latent spaces. An ideal latent space must be simultaneously compact and generation-friendly: it should capture image's essential content compactly while remaining easy to model with generative approaches. In this work, we introduce a novel regularizer to align latent spaces with these two objectives. The key idea is to guide tokenizers to mimic the hidden state dynamics of state-space models (SSMs), thereby transferring their critical property, frequency awareness, to latent features. Grounded in a theoretical analysis of SSMs, our regularizer enforces encoding of fine spatial structures and frequency-domain cues into compact latent features; leading to more effective use of representation capacity and improved generative modelability. Experiments demonstrate that our method improves generation quality in diffusion models while incurring only minimal loss in reconstruction fidelity.
MIMO Channel Prediction via Deep Learning-based Conformal Bayes Filter
Mar 05, 2026Channel prediction has emerged as an effective solution for acquiring accurate channel state information (CSI) in the presense of channel aging. Existing methods have inherent limitations, with conventional Kalman filter (KF)-based approach being vulnerable to model mismatch and deep learning (DL)-based approaches producing overconfident predictions. To address these issues, we propose a DL-based conformal Bayes filter (DCBF) that integrates DL-based prediction, conformal quantile regression (CQR), and Bayesian filtering. The proposed framework enables principled fusion of calibrated priors and observations, yielding reliable channel predictions with the calibrated uncertainty. Simulation results demonstrate that DCBF significantly improves DL-based prediction and outperforms the KF-based method.
Planning in 8 Tokens: A Compact Discrete Tokenizer for Latent World Model
Mar 05, 2026World models provide a powerful framework for simulating environment dynamics conditioned on actions or instructions, enabling downstream tasks such as action planning or policy learning. Recent approaches leverage world models as learned simulators, but its application to decision-time planning remains computationally prohibitive for real-time control. A key bottleneck lies in latent representations: conventional tokenizers encode each observation into hundreds of tokens, making planning both slow and resource-intensive. To address this, we propose CompACT, a discrete tokenizer that compresses each observation into as few as 8 tokens, drastically reducing computational cost while preserving essential information for planning. An action-conditioned world model that occupies CompACT tokenizer achieves competitive planning performance with orders-of-magnitude faster planning, offering a practical step toward real-world deployment of world models.
Automating High Energy Physics Data Analysis with LLM-Powered Agents
Dec 08, 2025

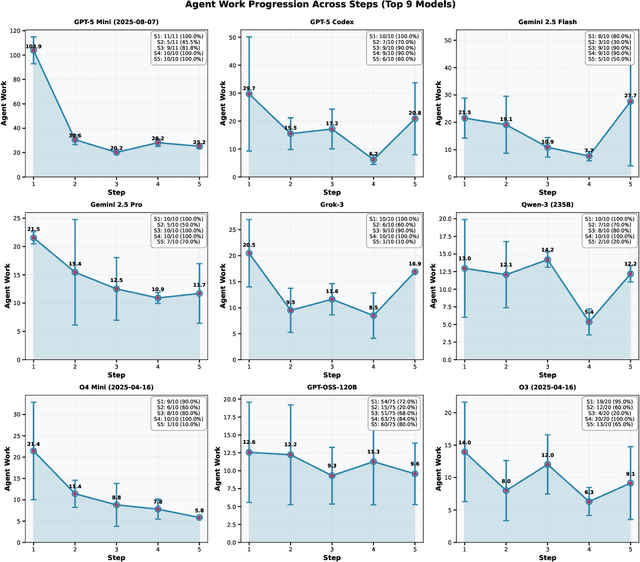

We present a proof-of-principle study demonstrating the use of large language model (LLM) agents to automate a representative high energy physics (HEP) analysis. Using the Higgs boson diphoton cross-section measurement as a case study with ATLAS Open Data, we design a hybrid system that combines an LLM-based supervisor-coder agent with the Snakemake workflow manager. In this architecture, the workflow manager enforces reproducibility and determinism, while the agent autonomously generates, executes, and iteratively corrects analysis code in response to user instructions. We define quantitative evaluation metrics including success rate, error distribution, costs per specific task, and average number of API calls, to assess agent performance across multi-stage workflows. To characterize variability across architectures, we benchmark a representative selection of state-of-the-art LLMs spanning the Gemini and GPT-5 series, the Claude family, and leading open-weight models. While the workflow manager ensures deterministic execution of all analysis steps, the final outputs still show stochastic variation. Although we set the temperature to zero, other sampling parameters (e.g., top-p, top-k) remained at their defaults, and some reasoning-oriented models internally adjust these settings. Consequently, the models do not produce fully deterministic results. This study establishes the first LLM-agent-driven automated data-analysis framework in HEP, enabling systematic benchmarking of model capabilities, stability, and limitations in real-world scientific computing environments. The baseline code used in this work is available at https://huggingface.co/HWresearch/LLM4HEP. This work was accepted as a poster at the Machine Learning and the Physical Sciences (ML4PS) workshop at NeurIPS 2025. The initial submission was made on August 30, 2025.
Democratizing Text-to-Image Masked Generative Models with Compact Text-Aware One-Dimensional Tokens
Jan 13, 2025



Image tokenizers form the foundation of modern text-to-image generative models but are notoriously difficult to train. Furthermore, most existing text-to-image models rely on large-scale, high-quality private datasets, making them challenging to replicate. In this work, we introduce Text-Aware Transformer-based 1-Dimensional Tokenizer (TA-TiTok), an efficient and powerful image tokenizer that can utilize either discrete or continuous 1-dimensional tokens. TA-TiTok uniquely integrates textual information during the tokenizer decoding stage (i.e., de-tokenization), accelerating convergence and enhancing performance. TA-TiTok also benefits from a simplified, yet effective, one-stage training process, eliminating the need for the complex two-stage distillation used in previous 1-dimensional tokenizers. This design allows for seamless scalability to large datasets. Building on this, we introduce a family of text-to-image Masked Generative Models (MaskGen), trained exclusively on open data while achieving comparable performance to models trained on private data. We aim to release both the efficient, strong TA-TiTok tokenizers and the open-data, open-weight MaskGen models to promote broader access and democratize the field of text-to-image masked generative models.
Improving Text-based Person Search via Part-level Cross-modal Correspondence
Dec 31, 2024



Text-based person search is the task of finding person images that are the most relevant to the natural language text description given as query. The main challenge of this task is a large gap between the target images and text queries, which makes it difficult to establish correspondence and distinguish subtle differences across people. To address this challenge, we introduce an efficient encoder-decoder model that extracts coarse-to-fine embedding vectors which are semantically aligned across the two modalities without supervision for the alignment. There is another challenge of learning to capture fine-grained information with only person IDs as supervision, where similar body parts of different individuals are considered different due to the lack of part-level supervision. To tackle this, we propose a novel ranking loss, dubbed commonality-based margin ranking loss, which quantifies the degree of commonality of each body part and reflects it during the learning of fine-grained body part details. As a consequence, it enables our method to achieve the best records on three public benchmarks.
1.58-bit FLUX
Dec 24, 2024We present 1.58-bit FLUX, the first successful approach to quantizing the state-of-the-art text-to-image generation model, FLUX.1-dev, using 1.58-bit weights (i.e., values in {-1, 0, +1}) while maintaining comparable performance for generating 1024 x 1024 images. Notably, our quantization method operates without access to image data, relying solely on self-supervision from the FLUX.1-dev model. Additionally, we develop a custom kernel optimized for 1.58-bit operations, achieving a 7.7x reduction in model storage, a 5.1x reduction in inference memory, and improved inference latency. Extensive evaluations on the GenEval and T2I Compbench benchmarks demonstrate the effectiveness of 1.58-bit FLUX in maintaining generation quality while significantly enhancing computational efficiency.
Robust Bayesian Optimization via Localized Online Conformal Prediction
Nov 26, 2024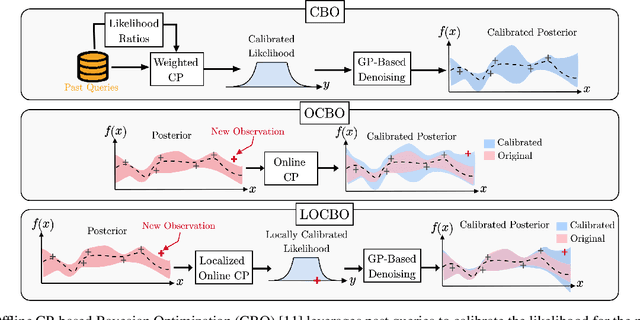
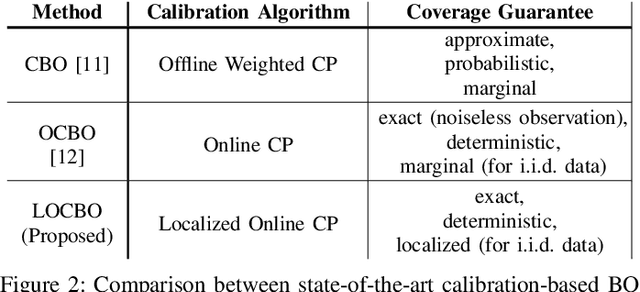
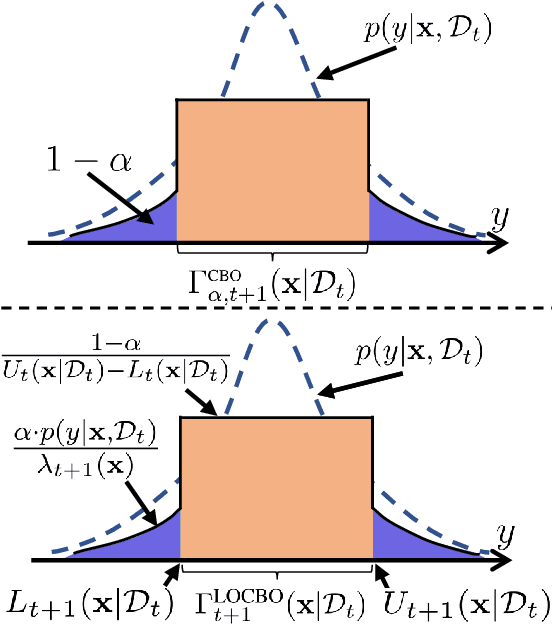
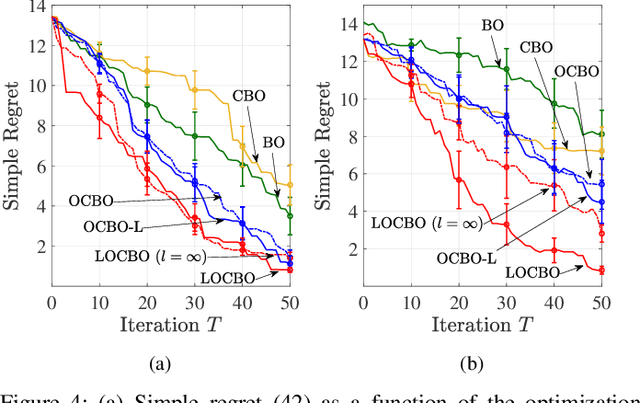
Bayesian optimization (BO) is a sequential approach for optimizing black-box objective functions using zeroth-order noisy observations. In BO, Gaussian processes (GPs) are employed as probabilistic surrogate models to estimate the objective function based on past observations, guiding the selection of future queries to maximize utility. However, the performance of BO heavily relies on the quality of these probabilistic estimates, which can deteriorate significantly under model misspecification. To address this issue, we introduce localized online conformal prediction-based Bayesian optimization (LOCBO), a BO algorithm that calibrates the GP model through localized online conformal prediction (CP). LOCBO corrects the GP likelihood based on predictive sets produced by LOCBO, and the corrected GP likelihood is then denoised to obtain a calibrated posterior distribution on the objective function. The likelihood calibration step leverages an input-dependent calibration threshold to tailor coverage guarantees to different regions of the input space. Under minimal noise assumptions, we provide theoretical performance guarantees for LOCBO's iterates that hold for the unobserved objective function. These theoretical findings are validated through experiments on synthetic and real-world optimization tasks, demonstrating that LOCBO consistently outperforms state-of-the-art BO algorithms in the presence of model misspecification.
Bootstrapping Top-down Information for Self-modulating Slot Attention
Nov 04, 2024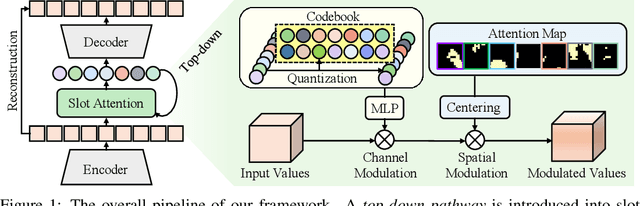


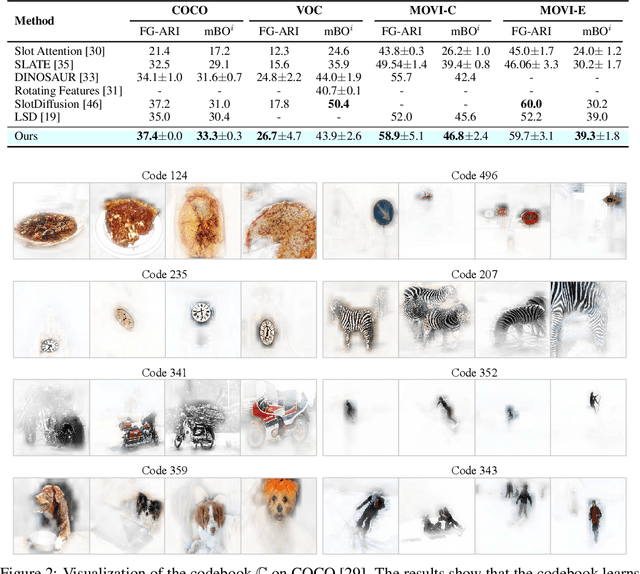
Object-centric learning (OCL) aims to learn representations of individual objects within visual scenes without manual supervision, facilitating efficient and effective visual reasoning. Traditional OCL methods primarily employ bottom-up approaches that aggregate homogeneous visual features to represent objects. However, in complex visual environments, these methods often fall short due to the heterogeneous nature of visual features within an object. To address this, we propose a novel OCL framework incorporating a top-down pathway. This pathway first bootstraps the semantics of individual objects and then modulates the model to prioritize features relevant to these semantics. By dynamically modulating the model based on its own output, our top-down pathway enhances the representational quality of objects. Our framework achieves state-of-the-art performance across multiple synthetic and real-world object-discovery benchmarks.
Shatter and Gather: Learning Referring Image Segmentation with Text Supervision
Aug 29, 2023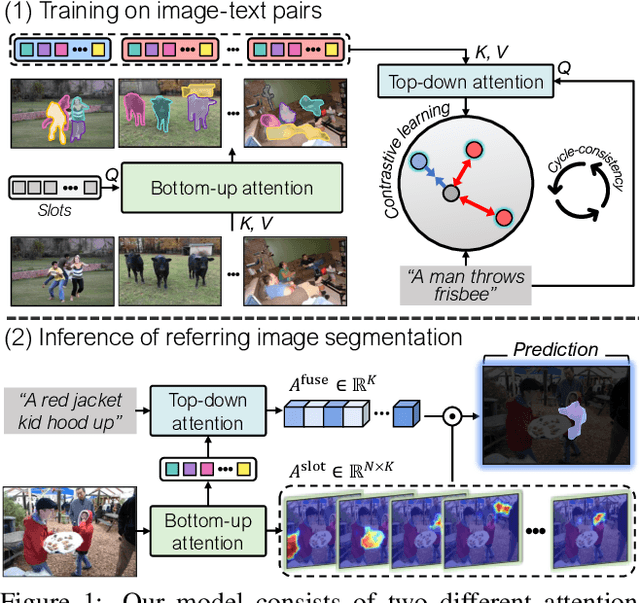
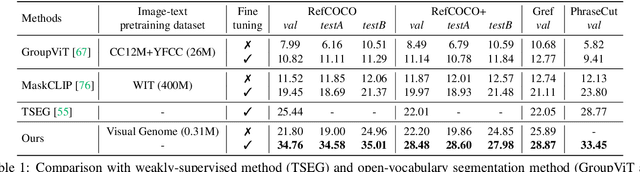
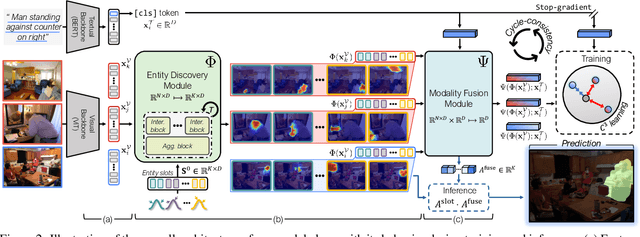

Referring image segmentation, the task of segmenting any arbitrary entities described in free-form texts, opens up a variety of vision applications. However, manual labeling of training data for this task is prohibitively costly, leading to lack of labeled data for training. We address this issue by a weakly supervised learning approach using text descriptions of training images as the only source of supervision. To this end, we first present a new model that discovers semantic entities in input image and then combines such entities relevant to text query to predict the mask of the referent. We also present a new loss function that allows the model to be trained without any further supervision. Our method was evaluated on four public benchmarks for referring image segmentation, where it clearly outperformed the existing method for the same task and recent open-vocabulary segmentation models on all the benchmarks.