 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Audio-guided Video Representation with Gated Attention for Video-Text Retrieval
Apr 03, 2025Video-text retrieval, the task of retrieving videos based on a textual query or vice versa, is of paramount importance for video understanding and multimodal information retrieval. Recent methods in this area rely primarily on visual and textual features and often ignore audio, although it helps enhance overall comprehension of video content. Moreover, traditional models that incorporate audio blindly utilize the audio input regardless of whether it is useful or not, resulting in suboptimal video representation. To address these limitations, we propose a novel video-text retrieval framework, Audio-guided VIdeo representation learning with GATEd attention (AVIGATE), that effectively leverages audio cues through a gated attention mechanism that selectively filters out uninformative audio signals. In addition, we propose an adaptive margin-based contrastive loss to deal with the inherently unclear positive-negative relationship between video and text, which facilitates learning better video-text alignment. Our extensive experiments demonstrate that AVIGATE achieves state-of-the-art performance on all the public benchmarks.
GENIUS: A Generative Framework for Universal Multimodal Search
Mar 25, 2025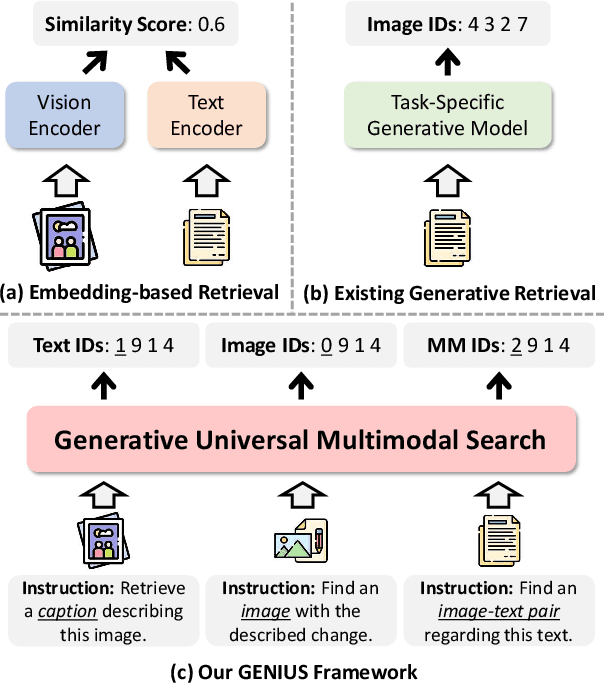
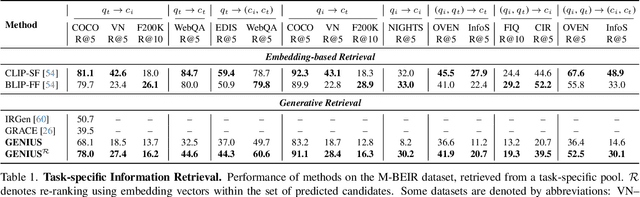
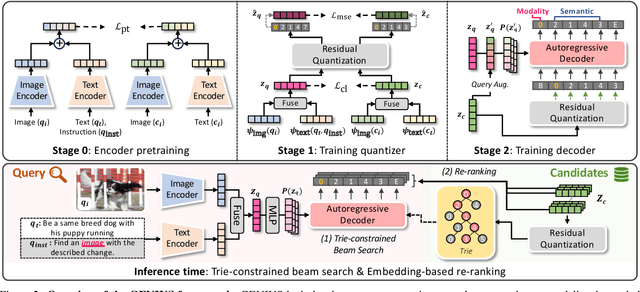
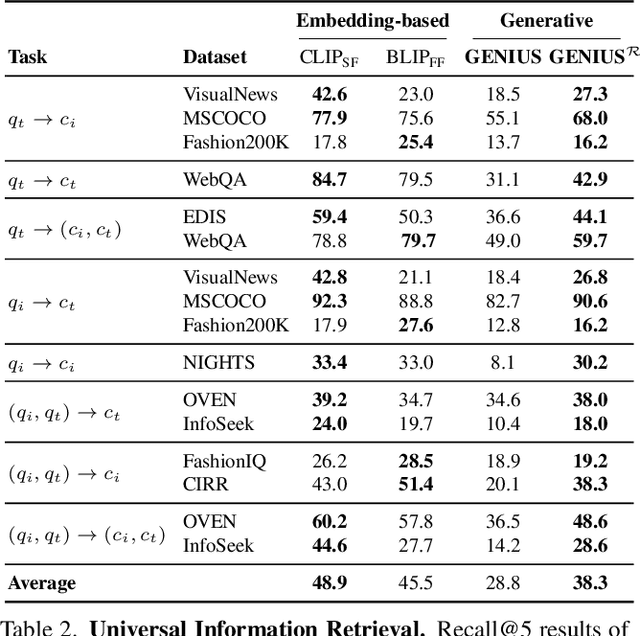
Generative retrieval is an emerging approach in information retrieval that generates identifiers (IDs) of target data based on a query, providing an efficient alternative to traditional embedding-based retrieval methods. However, existing models are task-specific and fall short of embedding-based retrieval in performance. This paper proposes GENIUS, a universal generative retrieval framework supporting diverse tasks across multiple modalities and domains. At its core, GENIUS introduces modality-decoupled semantic quantization, transforming multimodal data into discrete IDs encoding both modality and semantics. Moreover, to enhance generalization, we propose a query augmentation that interpolates between a query and its target, allowing GENIUS to adapt to varied query forms. Evaluated on the M-BEIR benchmark, it surpasses prior generative methods by a clear margin. Unlike embedding-based retrieval, GENIUS consistently maintains high retrieval speed across database size, with competitive performance across multiple benchmarks. With additional re-ranking, GENIUS often achieves results close to those of embedding-based methods while preserving efficiency.
Efficient and Versatile Robust Fine-Tuning of Zero-shot Models
Aug 11, 2024



Large-scale image-text pre-trained models enable zero-shot classification and provide consistent accuracy across various data distributions. Nonetheless, optimizing these models in downstream tasks typically requires fine-tuning, which reduces generalization to out-of-distribution (OOD) data and demands extensive computational resources. We introduce Robust Adapter (R-Adapter), a novel method for fine-tuning zero-shot models to downstream tasks while simultaneously addressing both these issues. Our method integrates lightweight modules into the pre-trained model and employs novel self-ensemble techniques to boost OOD robustness and reduce storage expenses substantially. Furthermore, we propose MPM-NCE loss designed for fine-tuning on vision-language downstream tasks. It ensures precise alignment of multiple image-text pairs and discriminative feature learning. By extending the benchmark for robust fine-tuning beyond classification to include diverse tasks such as cross-modal retrieval and open vocabulary segmentation, we demonstrate the broad applicability of R-Adapter. Our extensive experiments demonstrate that R-Adapter achieves state-of-the-art performance across a diverse set of tasks, tuning only 13% of the parameters of the CLIP encoders.
FREST: Feature RESToration for Semantic Segmentation under Multiple Adverse Conditions
Jul 18, 2024Robust semantic segmentation under adverse conditions is crucial in real-world applications. To address this challenging task in practical scenarios where labeled normal condition images are not accessible in training, we propose FREST, a novel feature restoration framework for source-free domain adaptation (SFDA) of semantic segmentation to adverse conditions. FREST alternates two steps: (1) learning the condition embedding space that only separates the condition information from the features and (2) restoring features of adverse condition images on the learned condition embedding space. By alternating these two steps, FREST gradually restores features where the effect of adverse conditions is reduced. FREST achieved a state of the art on two public benchmarks (i.e., ACDC and RobotCar) for SFDA to adverse conditions. Moreover, it shows superior generalization ability on unseen datasets.
Universal Metric Learning with Parameter-Efficient Transfer Learning
Sep 16, 2023A common practice in metric learning is to train and test an embedding model for each dataset. This dataset-specific approach fails to simulate real-world scenarios that involve multiple heterogeneous distributions of data. In this regard, we introduce a novel metric learning paradigm, called Universal Metric Learning (UML), which learns a unified distance metric capable of capturing relations across multiple data distributions. UML presents new challenges, such as imbalanced data distribution and bias towards dominant distributions. To address these challenges, we propose Parameter-efficient Universal Metric leArning (PUMA), which consists of a pre-trained frozen model and two additional modules, stochastic adapter and prompt pool. These modules enable to capture dataset-specific knowledge while avoiding bias towards dominant distributions. Additionally, we compile a new universal metric learning benchmark with a total of 8 different datasets. PUMA outperformed the state-of-the-art dataset-specific models while using about 69 times fewer trainable parameters.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Aug 15, 2023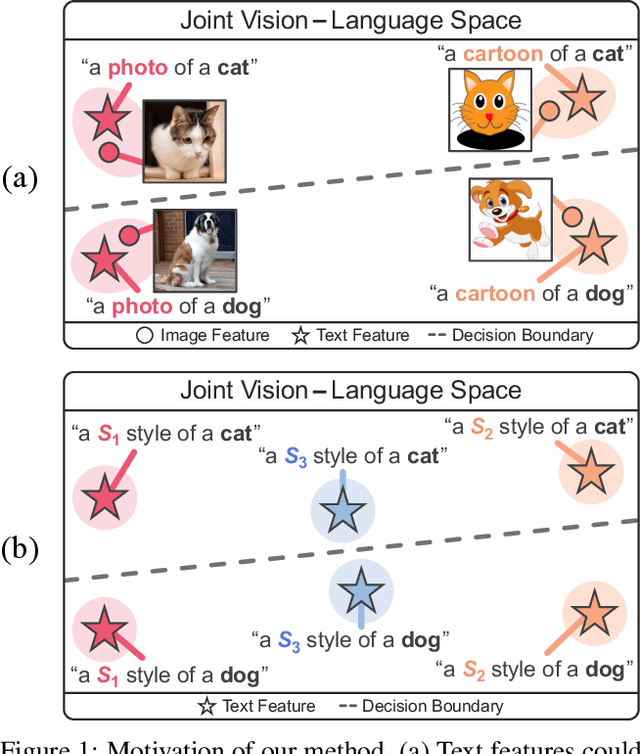
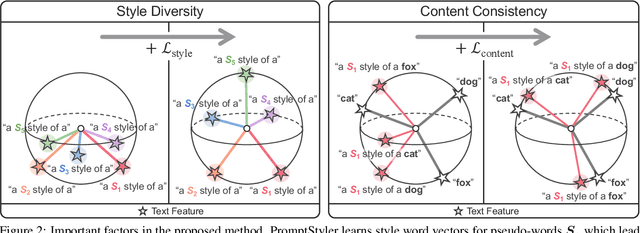
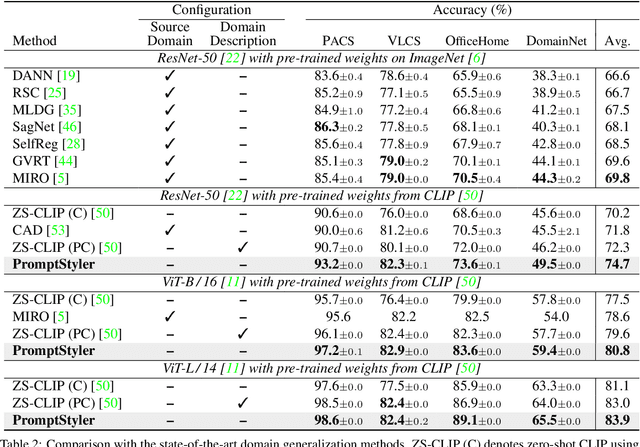
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Also, a recent study has demonstrated the cross-modal transferability phenomenon of this joint space. From these observations, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. The proposed method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, even though it does not require any images for training.
HIER: Metric Learning Beyond Class Labels via Hierarchical Regularization
Dec 29, 2022Supervision for metric learning has long been given in the form of equivalence between human-labeled classes. Although this type of supervision has been a basis of metric learning for decades, we argue that it hinders further advances of the field. In this regard, we propose a new regularization method, dubbed HIER, to discover the latent semantic hierarchy of training data, and to deploy the hierarchy to provide richer and more fine-grained supervision than inter-class separability induced by common metric learning losses. HIER achieved this goal with no annotation for the semantic hierarchy but by learning hierarchical proxies in hyperbolic spaces. The hierarchical proxies are learnable parameters, and each of them is trained to serve as an ancestor of a group of data or other proxies to approximate the semantic hierarchy among them. HIER deals with the proxies along with data in hyperbolic space since geometric properties of the space are well-suited to represent their hierarchical structure. The efficacy of HIER was evaluated on four standard benchmarks, where it consistently improved performance of conventional methods when integrated with them, and consequently achieved the best records, surpassing even the existing hyperbolic metric learning technique, in almost all settings.
Cross-Domain Ensemble Distillation for Domain Generalization
Nov 25, 2022Domain generalization is the task of learning models that generalize to unseen target domains. We propose a simple yet effective method for domain generalization, named cross-domain ensemble distillation (XDED), that learns domain-invariant features while encouraging the model to converge to flat minima, which recently turned out to be a sufficient condition for domain generalization. To this end, our method generates an ensemble of the output logits from training data with the same label but from different domains and then penalizes each output for the mismatch with the ensemble. Also, we present a de-stylization technique that standardizes features to encourage the model to produce style-consistent predictions even in an arbitrary target domain. Our method greatly improves generalization capability in public benchmarks for cross-domain image classification, cross-dataset person re-ID, and cross-dataset semantic segmentation. Moreover, we show that models learned by our method are robust against adversarial attacks and image corruptions.
Combating Label Distribution Shift for Active Domain Adaptation
Aug 13, 2022
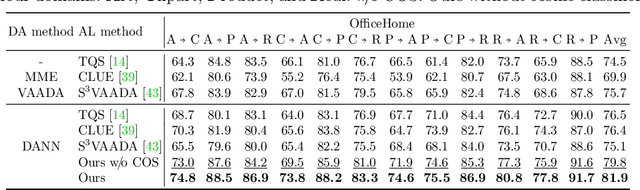
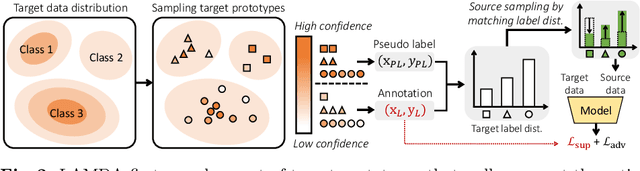
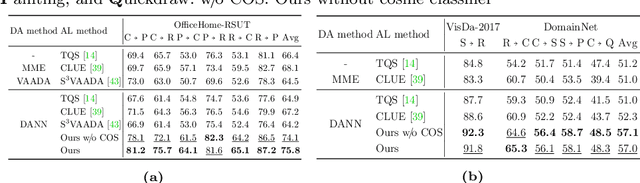
We consider the problem of active domain adaptation (ADA) to unlabeled target data, of which subset is actively selected and labeled given a budget constraint. Inspired by recent analysis on a critical issue from label distribution mismatch between source and target in domain adaptation, we devise a method that addresses the issue for the first time in ADA. At its heart lies a novel sampling strategy, which seeks target data that best approximate the entire target distribution as well as being representative, diverse, and uncertain. The sampled target data are then used not only for supervised learning but also for matching label distributions of source and target domains, leading to remarkable performance improvement. On four public benchmarks, our method substantially outperforms existing methods in every adaptation scenario.
Self-Taught Metric Learning without Labels
May 04, 2022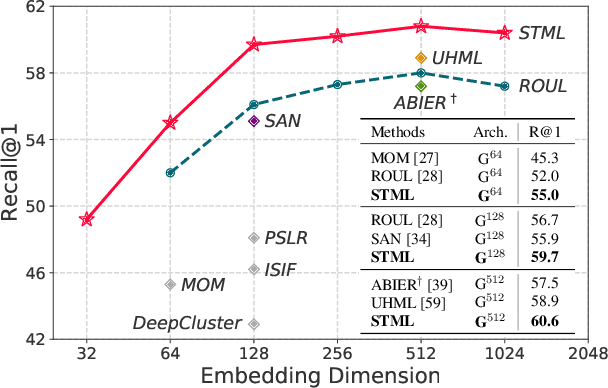
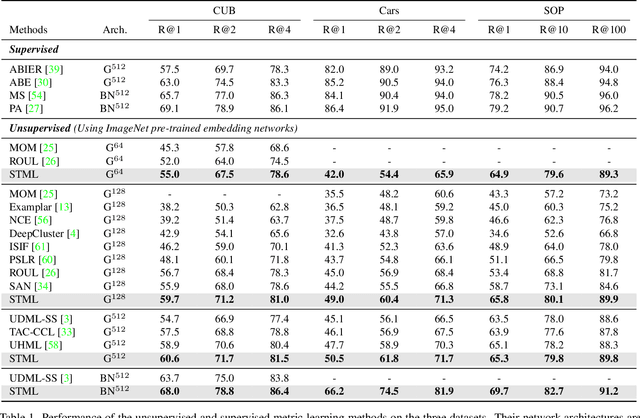
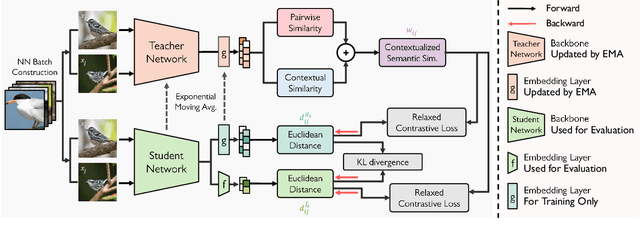
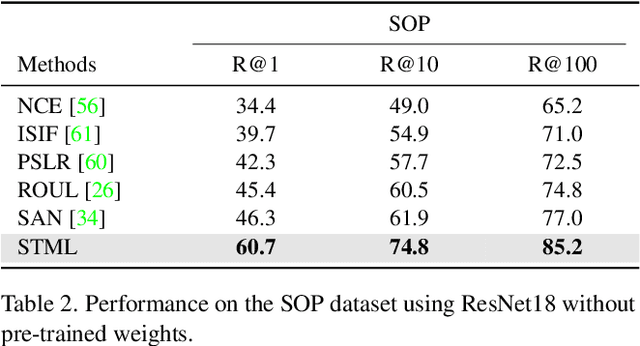
We present a novel self-taught framework for unsupervised metric learning, which alternates between predicting class-equivalence relations between data through a moving average of an embedding model and learning the model with the predicted relations as pseudo labels. At the heart of our framework lies an algorithm that investigates contexts of data on the embedding space to predict their class-equivalence relations as pseudo labels. The algorithm enables efficient end-to-end training since it demands no off-the-shelf module for pseudo labeling. Also, the class-equivalence relations provide rich supervisory signals for learning an embedding space. On standard benchmarks for metric learning, it clearly outperforms existing unsupervised learning methods and sometimes even beats supervised learning models using the same backbone network. It is also applied to semi-supervised metric learning as a way of exploiting additional unlabeled data, and achieves the state of the art by boosting performance of supervised learning substantially.