 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned split-spectrum metalens for obstruction-free broadband imaging in the visible
Jan 27, 2026Obstructions such as raindrops, fences, or dust degrade captured images, especially when mechanical cleaning is infeasible. Conventional solutions to obstructions rely on a bulky compound optics array or computational inpainting, which compromise compactness or fidelity. Metalenses composed of subwavelength meta-atoms promise compact imaging, but simultaneous achievement of broadband and obstruction-free imaging remains a challenge, since a metalens that images distant scenes across a broadband spectrum cannot properly defocus near-depth occlusions. Here, we introduce a learned split-spectrum metalens that enables broadband obstruction-free imaging. Our approach divides the spectrum of each RGB channel into pass and stop bands with multi-band spectral filtering and learns the metalens to focus light from far objects through pass bands, while filtering focused near-depth light through stop bands. This optical signal is further enhanced using a neural network. Our learned split-spectrum metalens achieves broadband and obstruction-free imaging with relative PSNR gains of 32.29% and improves object detection and semantic segmentation accuracies with absolute gains of +13.54% mAP, +48.45% IoU, and +20.35% mIoU over a conventional hyperbolic design. This promises robust obstruction-free sensing and vision for space-constrained systems, such as mobile robots, drones, and endoscopes.
DiCoTTA: Domain-invariant Learning for Continual Test-time Adaptation
Apr 07, 2025



This paper studies continual test-time adaptation (CTTA), the task of adapting a model to constantly changing unseen domains in testing while preserving previously learned knowledge. Existing CTTA methods mostly focus on adaptation to the current test domain only, overlooking generalization to arbitrary test domains a model may face in the future. To tackle this limitation, we present a novel online domain-invariant learning framework for CTTA, dubbed DiCoTTA. DiCoTTA aims to learn feature representation to be invariant to both current and previous test domains on the fly during testing. To this end, we propose a new model architecture and a test-time adaptation strategy dedicated to learning domain-invariant features without corrupting semantic contents, along with a new data structure and optimization algorithm for effectively managing information from previous test domains. DiCoTTA achieved state-of-the-art performance on four public CTTA benchmarks. Moreover, it showed superior generalization to unseen test domains.
FREST: Feature RESToration for Semantic Segmentation under Multiple Adverse Conditions
Jul 18, 2024Robust semantic segmentation under adverse conditions is crucial in real-world applications. To address this challenging task in practical scenarios where labeled normal condition images are not accessible in training, we propose FREST, a novel feature restoration framework for source-free domain adaptation (SFDA) of semantic segmentation to adverse conditions. FREST alternates two steps: (1) learning the condition embedding space that only separates the condition information from the features and (2) restoring features of adverse condition images on the learned condition embedding space. By alternating these two steps, FREST gradually restores features where the effect of adverse conditions is reduced. FREST achieved a state of the art on two public benchmarks (i.e., ACDC and RobotCar) for SFDA to adverse conditions. Moreover, it shows superior generalization ability on unseen datasets.
Active Learning for Semantic Segmentation with Multi-class Label Query
Sep 17, 2023This paper proposes a new active learning method for semantic segmentation. The core of our method lies in a new annotation query design. It samples informative local image regions (e.g., superpixels), and for each of such regions, asks an oracle for a multi-hot vector indicating all classes existing in the region. This multi-class labeling strategy is substantially more efficient than existing ones like segmentation, polygon, and even dominant class labeling in terms of annotation time per click. However, it introduces the class ambiguity issue in training since it assigns partial labels (i.e., a set of candidate classes) to individual pixels. We thus propose a new algorithm for learning semantic segmentation while disambiguating the partial labels in two stages. In the first stage, it trains a segmentation model directly with the partial labels through two new loss functions motivated by partial label learning and multiple instance learning. In the second stage, it disambiguates the partial labels by generating pixel-wise pseudo labels, which are used for supervised learning of the model. Equipped with a new acquisition function dedicated to the multi-class labeling, our method outperformed previous work on Cityscapes and PASCAL VOC 2012 while spending less annotation cost.
Human Pose Estimation in Extremely Low-Light Conditions
Mar 27, 2023We study human pose estimation in extremely low-light images. This task is challenging due to the difficulty of collecting real low-light images with accurate labels, and severely corrupted inputs that degrade prediction quality significantly. To address the first issue, we develop a dedicated camera system and build a new dataset of real low-light images with accurate pose labels. Thanks to our camera system, each low-light image in our dataset is coupled with an aligned well-lit image, which enables accurate pose labeling and is used as privileged information during training. We also propose a new model and a new training strategy that fully exploit the privileged information to learn representation insensitive to lighting conditions. Our method demonstrates outstanding performance on real extremely low light images, and extensive analyses validate that both of our model and dataset contribute to the success.
Combating Label Distribution Shift for Active Domain Adaptation
Aug 13, 2022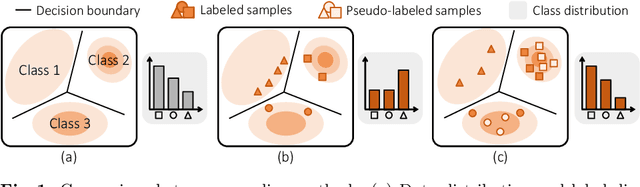
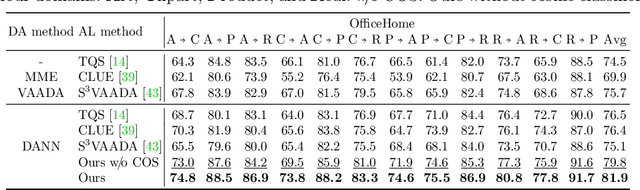
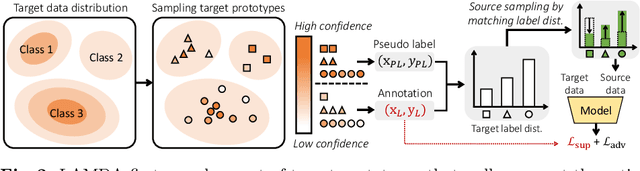
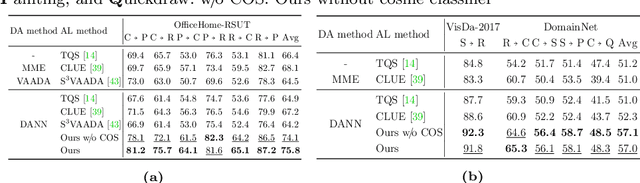
We consider the problem of active domain adaptation (ADA) to unlabeled target data, of which subset is actively selected and labeled given a budget constraint. Inspired by recent analysis on a critical issue from label distribution mismatch between source and target in domain adaptation, we devise a method that addresses the issue for the first time in ADA. At its heart lies a novel sampling strategy, which seeks target data that best approximate the entire target distribution as well as being representative, diverse, and uncertain. The sampled target data are then used not only for supervised learning but also for matching label distributions of source and target domains, leading to remarkable performance improvement. On four public benchmarks, our method substantially outperforms existing methods in every adaptation scenario.
FIFO: Learning Fog-invariant Features for Foggy Scene Segmentation
Apr 04, 2022
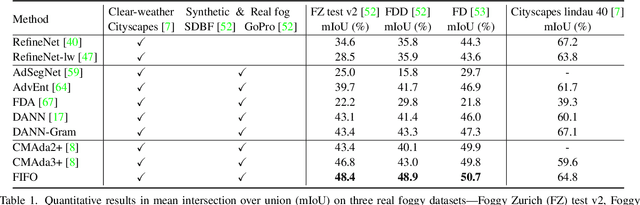
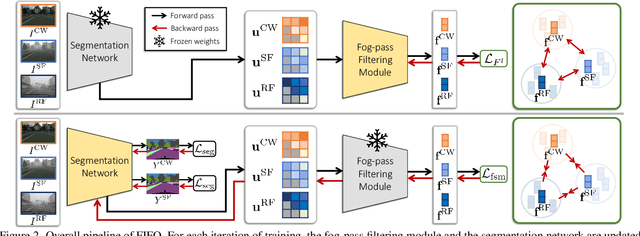
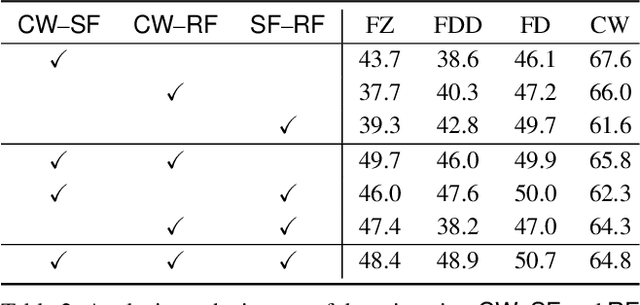
Robust visual recognition under adverse weather conditions is of great importance in real-world applications. In this context, we propose a new method for learning semantic segmentation models robust against fog. Its key idea is to consider the fog condition of an image as its style and close the gap between images with different fog conditions in neural style spaces of a segmentation model. In particular, since the neural style of an image is in general affected by other factors as well as fog, we introduce a fog-pass filter module that learns to extract a fog-relevant factor from the style. Optimizing the fog-pass filter and the segmentation model alternately gradually closes the style gap between different fog conditions and allows to learn fog-invariant features in consequence. Our method substantially outperforms previous work on three real foggy image datasets. Moreover, it improves performance on both foggy and clear weather images, while existing methods often degrade performance on clear scenes.