 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFREST: Feature RESToration for Semantic Segmentation under Multiple Adverse Conditions
Jul 18, 2024Robust semantic segmentation under adverse conditions is crucial in real-world applications. To address this challenging task in practical scenarios where labeled normal condition images are not accessible in training, we propose FREST, a novel feature restoration framework for source-free domain adaptation (SFDA) of semantic segmentation to adverse conditions. FREST alternates two steps: (1) learning the condition embedding space that only separates the condition information from the features and (2) restoring features of adverse condition images on the learned condition embedding space. By alternating these two steps, FREST gradually restores features where the effect of adverse conditions is reduced. FREST achieved a state of the art on two public benchmarks (i.e., ACDC and RobotCar) for SFDA to adverse conditions. Moreover, it shows superior generalization ability on unseen datasets.
Shatter and Gather: Learning Referring Image Segmentation with Text Supervision
Aug 29, 2023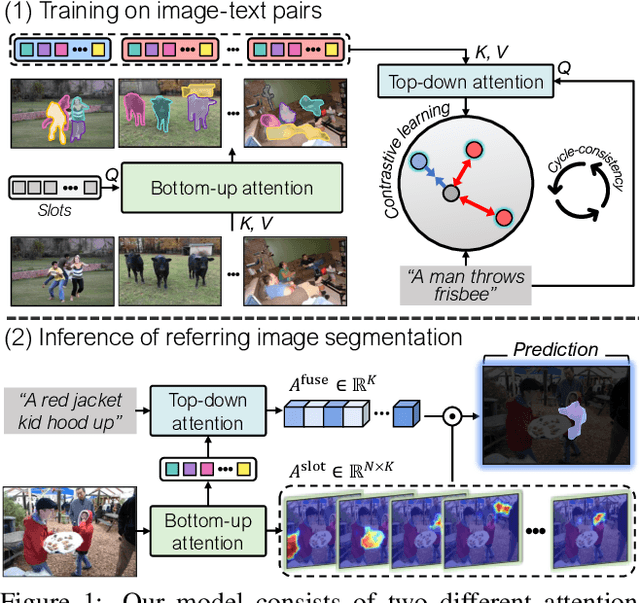
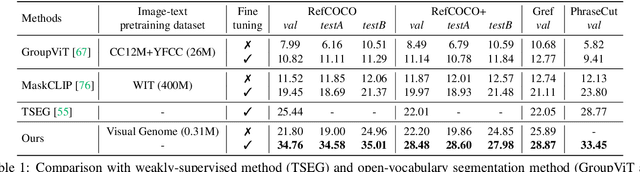
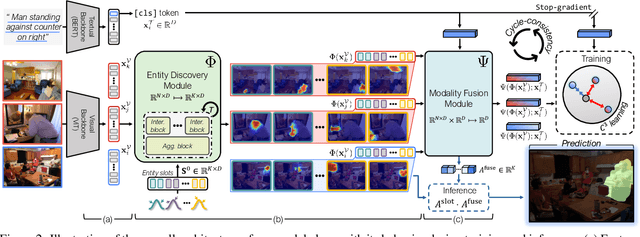

Referring image segmentation, the task of segmenting any arbitrary entities described in free-form texts, opens up a variety of vision applications. However, manual labeling of training data for this task is prohibitively costly, leading to lack of labeled data for training. We address this issue by a weakly supervised learning approach using text descriptions of training images as the only source of supervision. To this end, we first present a new model that discovers semantic entities in input image and then combines such entities relevant to text query to predict the mask of the referent. We also present a new loss function that allows the model to be trained without any further supervision. Our method was evaluated on four public benchmarks for referring image segmentation, where it clearly outperformed the existing method for the same task and recent open-vocabulary segmentation models on all the benchmarks.
Learning to Detect Semantic Boundaries with Image-level Class Labels
Dec 15, 2022This paper presents the first attempt to learn semantic boundary detection using image-level class labels as supervision. Our method starts by estimating coarse areas of object classes through attentions drawn by an image classification network. Since boundaries will locate somewhere between such areas of different classes, our task is formulated as a multiple instance learning (MIL) problem, where pixels on a line segment connecting areas of two different classes are regarded as a bag of boundary candidates. Moreover, we design a new neural network architecture that can learn to estimate semantic boundaries reliably even with uncertain supervision given by the MIL strategy. Our network is used to generate pseudo semantic boundary labels of training images, which are in turn used to train fully supervised models. The final model trained with our pseudo labels achieves an outstanding performance on the SBD dataset, where it is as competitive as some of previous arts trained with stronger supervision.
Improving Cross-Modal Retrieval with Set of Diverse Embeddings
Nov 30, 2022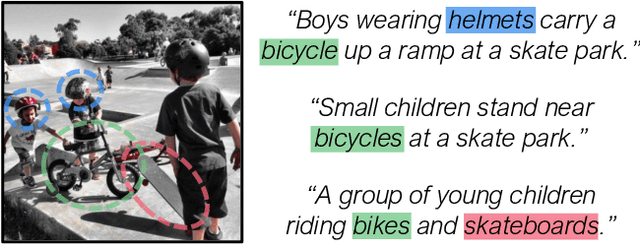
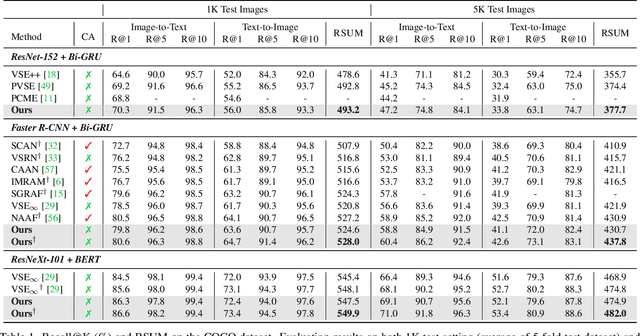
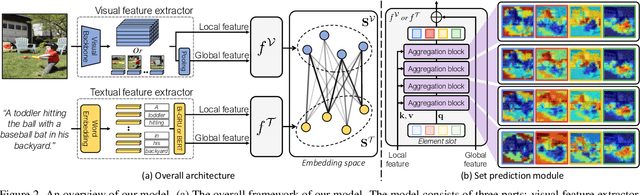
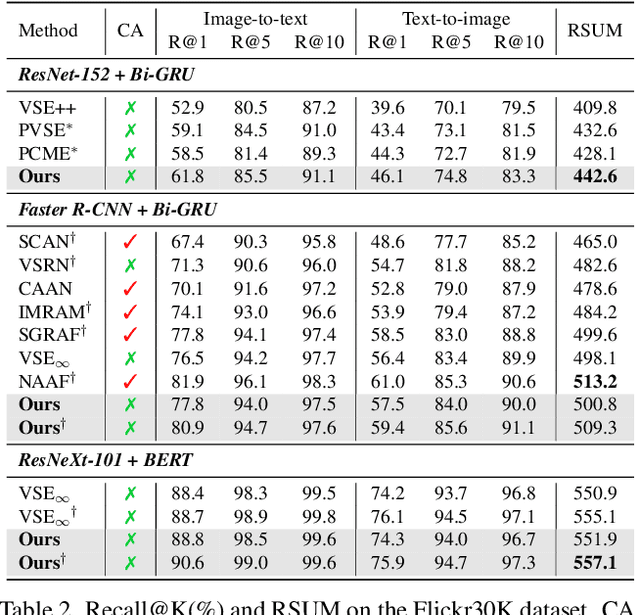
Cross-modal retrieval across image and text modalities is a challenging task due to its inherent ambiguity: An image often exhibits various situations, and a caption can be coupled with diverse images. Set-based embedding has been studied as a solution to this problem. It seeks to encode a sample into a set of different embedding vectors that capture different semantics of the sample. In this paper, we present a novel set-based embedding method, which is distinct from previous work in two aspects. First, we present a new similarity function called smooth-Chamfer similarity, which is designed to alleviate the side effects of existing similarity functions for set-based embedding. Second, we propose a novel set prediction module to produce a set of embedding vectors that effectively captures diverse semantics of input by the slot attention mechanism. Our method is evaluated on the COCO and Flickr30K datasets across different visual backbones, where it outperforms existing methods including ones that demand substantially larger computation at inference.
ReSTR: Convolution-free Referring Image Segmentation Using Transformers
Mar 31, 2022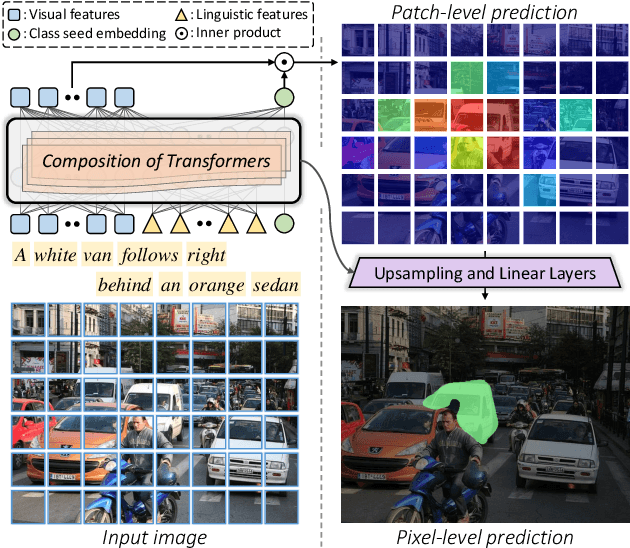
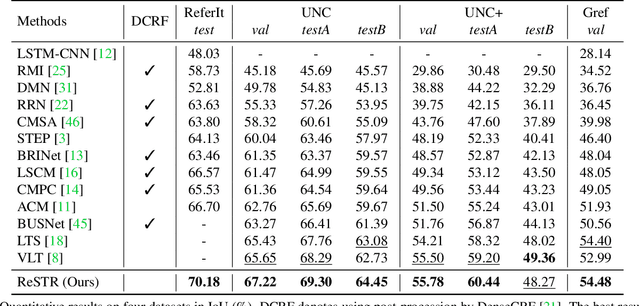
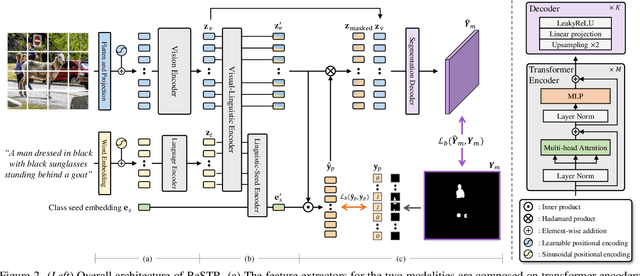
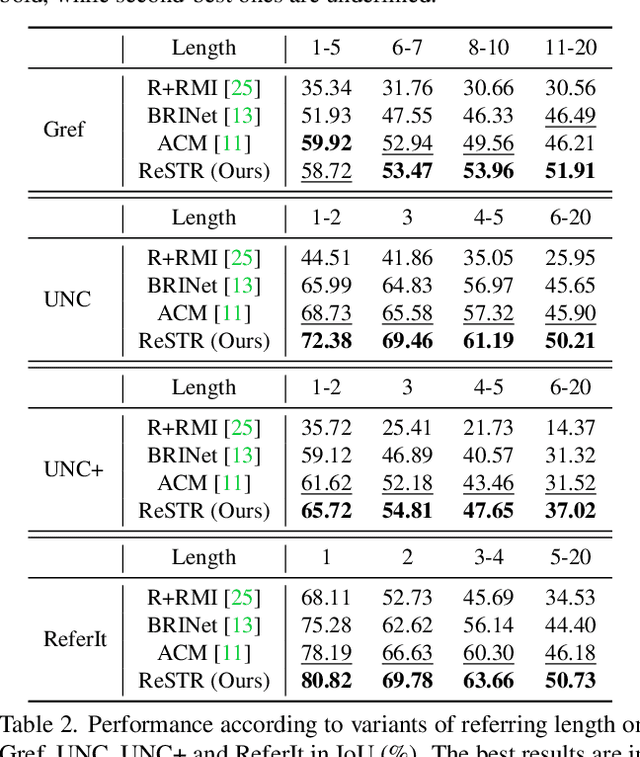
Referring image segmentation is an advanced semantic segmentation task where target is not a predefined class but is described in natural language. Most of existing methods for this task rely heavily on convolutional neural networks, which however have trouble capturing long-range dependencies between entities in the language expression and are not flexible enough for modeling interactions between the two different modalities. To address these issues, we present the first convolution-free model for referring image segmentation using transformers, dubbed ReSTR. Since it extracts features of both modalities through transformer encoders, it can capture long-range dependencies between entities within each modality. Also, ReSTR fuses features of the two modalities by a self-attention encoder, which enables flexible and adaptive interactions between the two modalities in the fusion process. The fused features are fed to a segmentation module, which works adaptively according to the image and language expression in hand. ReSTR is evaluated and compared with previous work on all public benchmarks, where it outperforms all existing models.
WEDGE: Web-Image Assisted Domain Generalization for Semantic Segmentation
Sep 29, 2021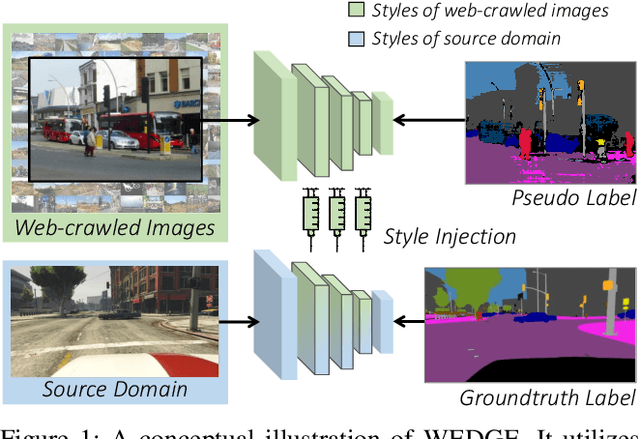
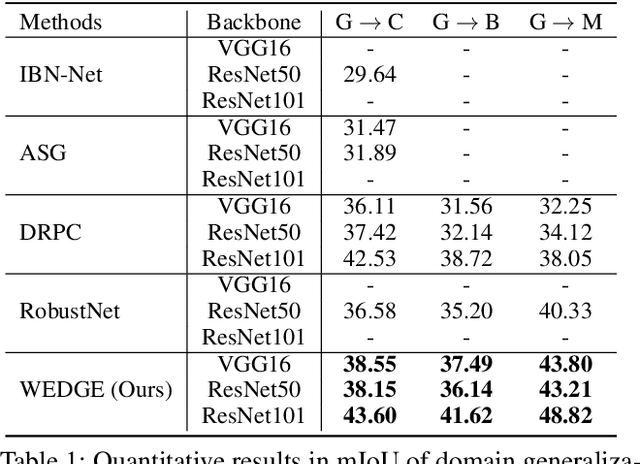
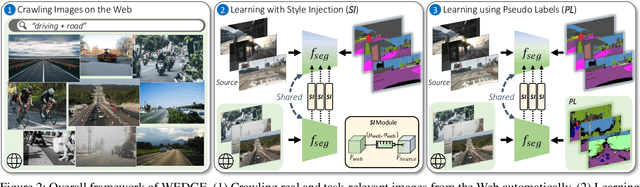
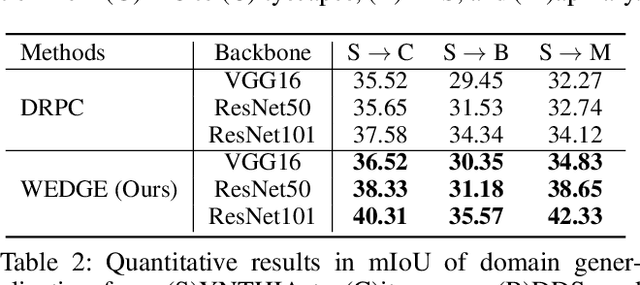
Domain generalization for semantic segmentation is highly demanded in real applications, where a trained model is expected to work well in previously unseen domains. One challenge lies in the lack of data which could cover the diverse distributions of the possible unseen domains for training. In this paper, we propose a WEb-image assisted Domain GEneralization (WEDGE) scheme, which is the first to exploit the diversity of web-crawled images for generalizable semantic segmentation. To explore and exploit the real-world data distributions, we collect a web-crawled dataset which presents large diversity in terms of weather conditions, sites, lighting, camera styles, etc. We also present a method which injects the style representation of the web-crawled data into the source domain on-the-fly during training, which enables the network to experience images of diverse styles with reliable labels for effective training. Moreover, we use the web-crawled dataset with predicted pseudo labels for training to further enhance the capability of the network. Extensive experiments demonstrate that our method clearly outperforms existing domain generalization techniques.
URIE: Universal Image Enhancement for Visual Recognition in the Wild
Jul 24, 2020



Despite the great advances in visual recognition, it has been witnessed that recognition models trained on clean images of common datasets are not robust against distorted images in the real world. To tackle this issue, we present a Universal and Recognition-friendly Image Enhancement network, dubbed URIE, which is attached in front of existing recognition models and enhances distorted input to improve their performance without retraining them. URIE is universal in that it aims to handle various factors of image degradation and to be incorporated with any arbitrary recognition models. Also, it is recognition-friendly since it is optimized to improve the robustness of following recognition models, instead of perceptual quality of output image. Our experiments demonstrate that URIE can handle various and latent image distortions and improve the performance of existing models for five diverse recognition tasks when input images are degraded.