 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Models Unmergeable via Scaling-Sensitive Loss Landscape
Jan 29, 2026The rise of model hubs has made it easier to access reusable model components, making model merging a practical tool for combining capabilities. Yet, this modularity also creates a \emph{governance gap}: downstream users can recompose released weights into unauthorized mixtures that bypass safety alignment or licensing terms. Because existing defenses are largely post-hoc and architecture-specific, they provide inconsistent protection across diverse architectures and release formats in practice. To close this gap, we propose \textsc{Trap}$^{2}$, an architecture-agnostic protection framework that encodes protection into the update during fine-tuning, regardless of whether they are released as adapters or full models. Instead of relying on architecture-dependent approaches, \textsc{Trap}$^{2}$ uses weight re-scaling as a simple proxy for the merging process. It keeps released weights effective in standalone use, but degrades them under re-scaling that often arises in merging, undermining unauthorized merging.
Janus Metasurface Breaking Polarization Symmetry: Surface-Modulated Electromagnetic Wave Radiation with Coexistent Linear and Circular Polarization
Dec 17, 2025



In this work, a Janus metasurface based tensor impedance holographic antenna (JHA) is proposed that simultaneously radiates linearly polarized (LP) and circularly polarized (CP) beams from a single aperture excited by a single feed. The proposed design introduces modified tensor impedance equations to significantly reduce cross-polarization at higher radiation angles. It demonstrates broadband operation bandwidth of 0.5 GHz while maintaining high circular polarization purity. The design methodology is verified using aperture field integration theory, ensuring that the impedance distribution produces the desired far-field radiation patterns. Prototypes of three variations of the holographic antenna are fabricated, validating its performance. The radiation characteristics of the proposed antenna make it an attractive choice for advanced broadband communication applications.
Enhancing Cost Efficiency in Active Learning with Candidate Set Query
Feb 10, 2025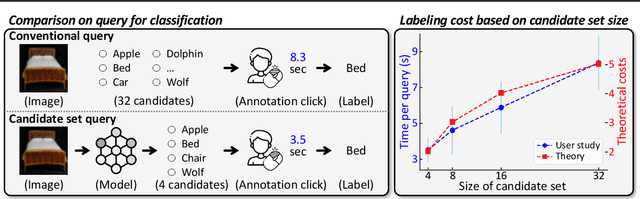

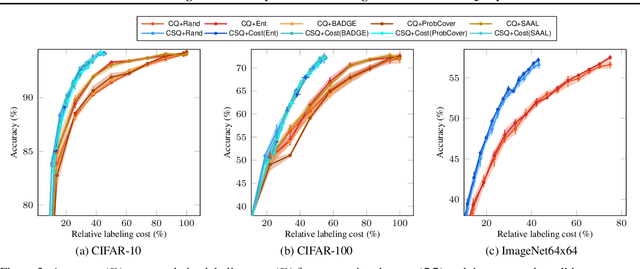
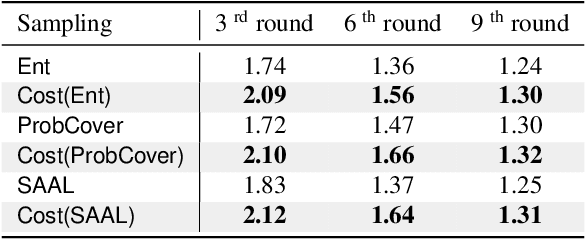
This paper introduces a cost-efficient active learning (AL) framework for classification, featuring a novel query design called candidate set query. Unlike traditional AL queries requiring the oracle to examine all possible classes, our method narrows down the set of candidate classes likely to include the ground-truth class, significantly reducing the search space and labeling cost. Moreover, we leverage conformal prediction to dynamically generate small yet reliable candidate sets, adapting to model enhancement over successive AL rounds. To this end, we introduce an acquisition function designed to prioritize data points that offer high information gain at lower cost. Empirical evaluations on CIFAR-10, CIFAR-100, and ImageNet64x64 demonstrate the effectiveness and scalability of our framework. Notably, it reduces labeling cost by 42% on ImageNet64x64.
Context-Aware Input Orchestration for Video Inpainting
Nov 25, 2024

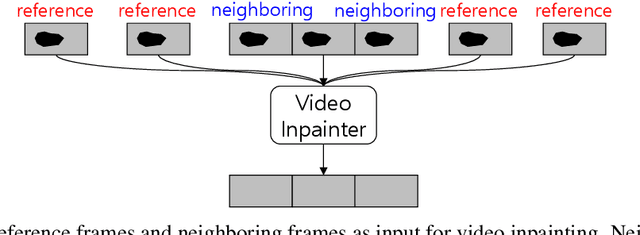

Traditional neural network-driven inpainting methods struggle to deliver high-quality results within the constraints of mobile device processing power and memory. Our research introduces an innovative approach to optimize memory usage by altering the composition of input data. Typically, video inpainting relies on a predetermined set of input frames, such as neighboring and reference frames, often limited to five-frame sets. Our focus is to examine how varying the proportion of these input frames impacts the quality of the inpainted video. By dynamically adjusting the input frame composition based on optical flow and changes of the mask, we have observed an improvement in various contents including rapid visual context changes.
Active Prompt Learning with Vision-Language Model Priors
Nov 23, 2024



Vision-language models (VLMs) have demonstrated remarkable zero-shot performance across various classification tasks. Nonetheless, their reliance on hand-crafted text prompts for each task hinders efficient adaptation to new tasks. While prompt learning offers a promising solution, most studies focus on maximizing the utilization of given few-shot labeled datasets, often overlooking the potential of careful data selection strategies, which enable higher accuracy with fewer labeled data. This motivates us to study a budget-efficient active prompt learning framework. Specifically, we introduce a class-guided clustering that leverages the pre-trained image and text encoders of VLMs, thereby enabling our cluster-balanced acquisition function from the initial round of active learning. Furthermore, considering the substantial class-wise variance in confidence exhibited by VLMs, we propose a budget-saving selective querying based on adaptive class-wise thresholds. Extensive experiments in active learning scenarios across nine datasets demonstrate that our method outperforms existing baselines.
ZNorm: Z-Score Gradient Normalization for Accelerating Neural Network Training
Aug 02, 2024



The rapid advancements in deep learning necessitate efficient training methods for deep neural networks (DNNs). As models grow in complexity, vanishing and exploding gradients impede convergence and performance. We propose Z-Score Normalization for Gradient Descent (ZNorm), an innovative technique that adjusts only the gradients to enhance training efficiency and improve model performance. ZNorm normalizes the overall gradients, providing consistent gradient scaling across layers, thereby reducing the risks of vanishing and exploding gradients. Our extensive experiments on CIFAR-10 and medical datasets demonstrate that ZNorm not only accelerates convergence but also enhances performance metrics. ZNorm consistently outperforms existing methods, achieving superior results using the same computational settings. In medical imaging applications, ZNorm improves tumor prediction and segmentation performances, underscoring its practical utility. These findings highlight ZNorm's potential as a robust and versatile tool for improving the efficiency and effectiveness of deep neural network training across a wide range of architectures and applications.
Active Label Correction for Semantic Segmentation with Foundation Models
Mar 16, 2024



Training and validating models for semantic segmentation require datasets with pixel-wise annotations, which are notoriously labor-intensive. Although useful priors such as foundation models or crowdsourced datasets are available, they are error-prone. We hence propose an effective framework of active label correction (ALC) based on a design of correction query to rectify pseudo labels of pixels, which in turn is more annotator-friendly than the standard one inquiring to classify a pixel directly according to our theoretical analysis and user study. Specifically, leveraging foundation models providing useful zero-shot predictions on pseudo labels and superpixels, our method comprises two key techniques: (i) an annotator-friendly design of correction query with the pseudo labels, and (ii) an acquisition function looking ahead label expansions based on the superpixels. Experimental results on PASCAL, Cityscapes, and Kvasir-SEG datasets demonstrate the effectiveness of our ALC framework, outperforming prior methods for active semantic segmentation and label correction. Notably, utilizing our method, we obtained a revised dataset of PASCAL by rectifying errors in 2.6 million pixels in PASCAL dataset.
Active Learning for Semantic Segmentation with Multi-class Label Query
Sep 17, 2023This paper proposes a new active learning method for semantic segmentation. The core of our method lies in a new annotation query design. It samples informative local image regions (e.g., superpixels), and for each of such regions, asks an oracle for a multi-hot vector indicating all classes existing in the region. This multi-class labeling strategy is substantially more efficient than existing ones like segmentation, polygon, and even dominant class labeling in terms of annotation time per click. However, it introduces the class ambiguity issue in training since it assigns partial labels (i.e., a set of candidate classes) to individual pixels. We thus propose a new algorithm for learning semantic segmentation while disambiguating the partial labels in two stages. In the first stage, it trains a segmentation model directly with the partial labels through two new loss functions motivated by partial label learning and multiple instance learning. In the second stage, it disambiguates the partial labels by generating pixel-wise pseudo labels, which are used for supervised learning of the model. Equipped with a new acquisition function dedicated to the multi-class labeling, our method outperformed previous work on Cityscapes and PASCAL VOC 2012 while spending less annotation cost.
Adaptive Superpixel for Active Learning in Semantic Segmentation
Mar 29, 2023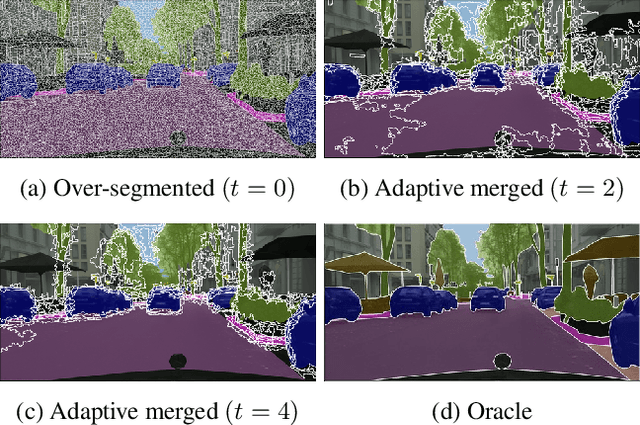
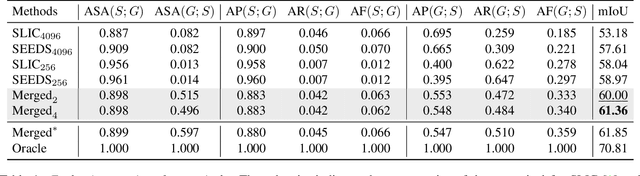
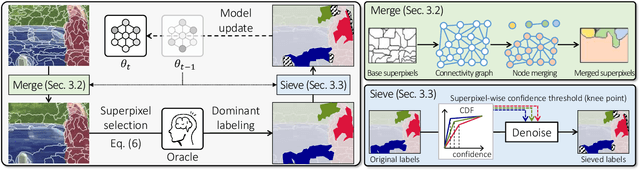
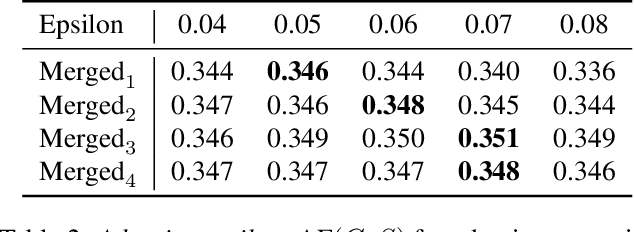
Learning semantic segmentation requires pixel-wise annotations, which can be time-consuming and expensive. To reduce the annotation cost, we propose a superpixel-based active learning (AL) framework, which collects a dominant label per superpixel instead. To be specific, it consists of adaptive superpixel and sieving mechanisms, fully dedicated to AL. At each round of AL, we adaptively merge neighboring pixels of similar learned features into superpixels. We then query a selected subset of these superpixels using an acquisition function assuming no uniform superpixel size. This approach is more efficient than existing methods, which rely only on innate features such as RGB color and assume uniform superpixel sizes. Obtaining a dominant label per superpixel drastically reduces annotators' burden as it requires fewer clicks. However, it inevitably introduces noisy annotations due to mismatches between superpixel and ground truth segmentation. To address this issue, we further devise a sieving mechanism that identifies and excludes potentially noisy annotations from learning. Our experiments on both Cityscapes and PASCAL VOC datasets demonstrate the efficacy of adaptive superpixel and sieving mechanisms.
Robust Deep Learning from Crowds with Belief Propagation
Nov 01, 2021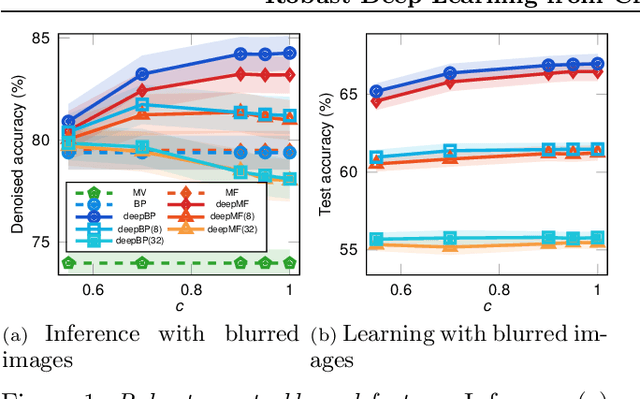

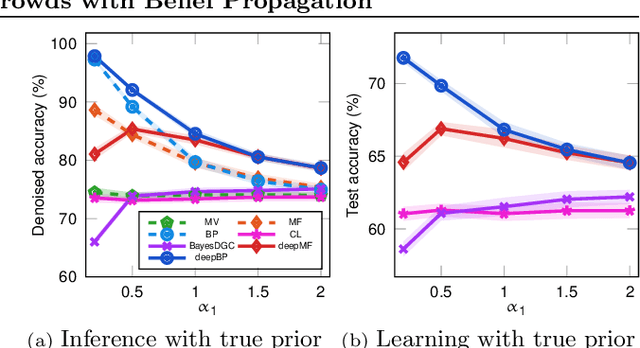
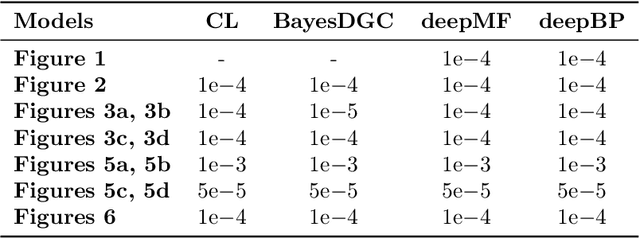
Crowdsourcing systems enable us to collect noisy labels from crowd workers. A graphical model representing local dependencies between workers and tasks provides a principled way of reasoning over the true labels from the noisy answers. However, one needs a predictive model working on unseen data directly from crowdsourced datasets instead of the true labels in many cases. To infer true labels and learn a predictive model simultaneously, we propose a new data-generating process, where a neural network generates the true labels from task features. We devise an EM framework alternating variational inference and deep learning to infer the true labels and to update the neural network, respectively. Experimental results with synthetic and real datasets show a belief-propagation-based EM algorithm is robust to i) corruption in task features, ii) multi-modal or mismatched worker prior, and iii) few spammers submitting noises to many tasks.