 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Rarities: Can Rare Skin Diseases Be Reliably Diagnosed via Diagnostic Reasoning?
Mar 19, 2026Large vision-language models (LVLMs) demonstrate strong performance in dermatology; however, evaluating diagnostic reasoning for rare conditions remains largely unexplored. Existing benchmarks focus on common diseases and assess only final accuracy, overlooking the clinical reasoning process, which is critical for complex cases. We address this gap by constructing DermCase, a long-context benchmark derived from peer-reviewed case reports. Our dataset contains 26,030 multi-modal image-text pairs and 6,354 clinically challenging cases, each annotated with comprehensive clinical information and step-by-step reasoning chains. To enable reliable evaluation, we establish DermLIP-based similarity metrics that achieve stronger alignment with dermatologists for assessing differential diagnosis quality. Benchmarking 22 leading LVLMs exposes significant deficiencies across diagnosis accuracy, differential diagnosis, and clinical reasoning. Fine-tuning experiments demonstrate that instruction tuning substantially improves performance while Direct Preference Optimization (DPO) yields minimal gains. Systematic error analysis further reveals critical limitations in current models' reasoning capabilities.
Transductive Generalization via Optimal Transport and Its Application to Graph Node Classification
Mar 10, 2026Many existing transductive bounds rely on classical complexity measures that are computationally intractable and often misaligned with empirical behavior. In this work, we establish new representation-based generalization bounds in a distribution-free transductive setting, where learned representations are dependent, and test features are accessible during training. We derive global and class-wise bounds via optimal transport, expressed in terms of Wasserstein distances between encoded feature distributions. We demonstrate that our bounds are efficiently computable and strongly correlate with empirical generalization in graph node classification, improving upon classical complexity measures. Additionally, our analysis reveals how the GNN aggregation process transforms the representation distributions, inducing a trade-off between intra-class concentration and inter-class separation. This yields depth-dependent characterizations that capture the non-monotonic relationship between depth and generalization error observed in practice. The code is available at https://github.com/ml-postech/Transductive-OT-Gen-Bound.
Training-free Composition of Pre-trained GFlowNets for Multi-Objective Generation
Feb 25, 2026Generative Flow Networks (GFlowNets) learn to sample diverse candidates in proportion to a reward function, making them well-suited for scientific discovery, where exploring multiple promising solutions is crucial. Further extending GFlowNets to multi-objective settings has attracted growing interest since real-world applications often involve multiple, conflicting objectives. However, existing approaches require additional training for each set of objectives, limiting their applicability and incurring substantial computational overhead. We propose a training-free mixing policy that composes pre-trained GFlowNets at inference time, enabling rapid adaptation without finetuning or retraining. Importantly, our framework is flexible, capable of handling diverse reward combinations ranging from linear scalarization to complex non-linear logical operators, which are often handled separately in previous literature. We prove that our method exactly recovers the target distribution for linear scalarization and quantify the approximation quality for nonlinear operators through a distortion factor. Experiments on a synthetic 2D grid and real-world molecule-generation tasks demonstrate that our approach achieves performance comparable to baselines that require additional training.
In-Place Feedback: A New Paradigm for Guiding LLMs in Multi-Turn Reasoning
Oct 01, 2025Large language models (LLMs) are increasingly studied in the context of multi-turn reasoning, where models iteratively refine their outputs based on user-provided feedback. Such settings are crucial for tasks that require complex reasoning, yet existing feedback paradigms often rely on issuing new messages. LLMs struggle to integrate these reliably, leading to inconsistent improvements. In this work, we introduce in-place feedback, a novel interaction paradigm in which users directly edit an LLM's previous response, and the model conditions on this modified response to generate its revision. Empirical evaluations on diverse reasoning-intensive benchmarks reveal that in-place feedback achieves better performance than conventional multi-turn feedback while using $79.1\%$ fewer tokens. Complementary analyses on controlled environments further demonstrate that in-place feedback resolves a core limitation of multi-turn feedback: models often fail to apply feedback precisely to erroneous parts of the response, leaving errors uncorrected and sometimes introducing new mistakes into previously correct content. These findings suggest that in-place feedback offers a more natural and effective mechanism for guiding LLMs in reasoning-intensive tasks.
Delving into Instance-Dependent Label Noise in Graph Data: A Comprehensive Study and Benchmark
Jun 14, 2025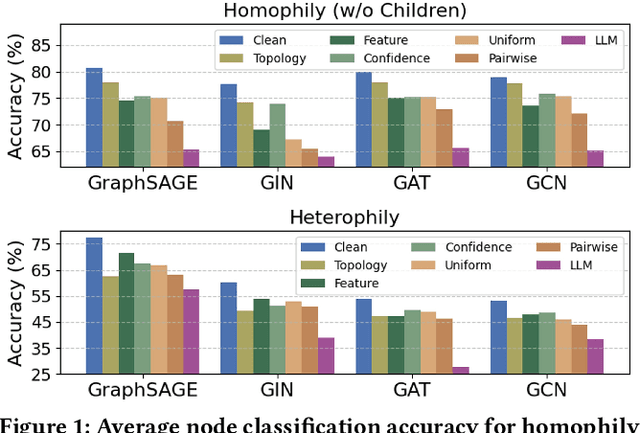
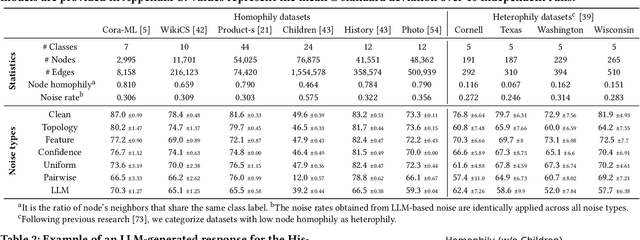
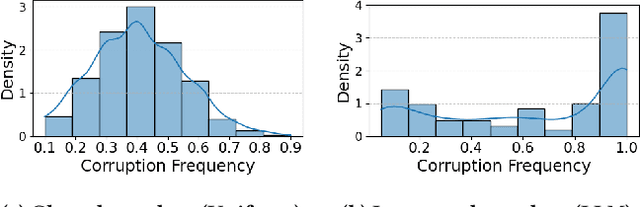
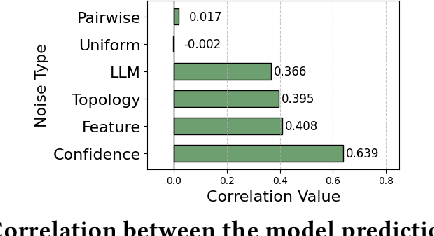
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in node classification tasks but struggle with label noise in real-world data. Existing studies on graph learning with label noise commonly rely on class-dependent label noise, overlooking the complexities of instance-dependent noise and falling short of capturing real-world corruption patterns. We introduce BeGIN (Benchmarking for Graphs with Instance-dependent Noise), a new benchmark that provides realistic graph datasets with various noise types and comprehensively evaluates noise-handling strategies across GNN architectures, noisy label detection, and noise-robust learning. To simulate instance-dependent corruptions, BeGIN introduces algorithmic methods and LLM-based simulations. Our experiments reveal the challenges of instance-dependent noise, particularly LLM-based corruption, and underscore the importance of node-specific parameterization to enhance GNN robustness. By comprehensively evaluating noise-handling strategies, BeGIN provides insights into their effectiveness, efficiency, and key performance factors. We expect that BeGIN will serve as a valuable resource for advancing research on label noise in graphs and fostering the development of robust GNN training methods. The code is available at https://github.com/kimsu55/BeGIN.
* 17 pages
The Oversmoothing Fallacy: A Misguided Narrative in GNN Research
Jun 05, 2025Oversmoothing has been recognized as a main obstacle to building deep Graph Neural Networks (GNNs), limiting the performance. This position paper argues that the influence of oversmoothing has been overstated and advocates for a further exploration of deep GNN architectures. Given the three core operations of GNNs, aggregation, linear transformation, and non-linear activation, we show that prior studies have mistakenly confused oversmoothing with the vanishing gradient, caused by transformation and activation rather than aggregation. Our finding challenges prior beliefs about oversmoothing being unique to GNNs. Furthermore, we demonstrate that classical solutions such as skip connections and normalization enable the successful stacking of deep GNN layers without performance degradation. Our results clarify misconceptions about oversmoothing and shed new light on the potential of deep GNNs.
Influence Functions for Edge Edits in Non-Convex Graph Neural Networks
Jun 05, 2025Understanding how individual edges influence the behavior of graph neural networks (GNNs) is essential for improving their interpretability and robustness. Graph influence functions have emerged as promising tools to efficiently estimate the effects of edge deletions without retraining. However, existing influence prediction methods rely on strict convexity assumptions, exclusively consider the influence of edge deletions while disregarding edge insertions, and fail to capture changes in message propagation caused by these modifications. In this work, we propose a proximal Bregman response function specifically tailored for GNNs, relaxing the convexity requirement and enabling accurate influence prediction for standard neural network architectures. Furthermore, our method explicitly accounts for message propagation effects and extends influence prediction to both edge deletions and insertions in a principled way. Experiments with real-world datasets demonstrate accurate influence predictions for different characteristics of GNNs. We further demonstrate that the influence function is versatile in applications such as graph rewiring and adversarial attacks.
High-order Equivariant Flow Matching for Density Functional Theory Hamiltonian Prediction
May 24, 2025Density functional theory (DFT) is a fundamental method for simulating quantum chemical properties, but it remains expensive due to the iterative self-consistent field (SCF) process required to solve the Kohn-Sham equations. Recently, deep learning methods are gaining attention as a way to bypass this step by directly predicting the Hamiltonian. However, they rely on deterministic regression and do not consider the highly structured nature of Hamiltonians. In this work, we propose QHFlow, a high-order equivariant flow matching framework that generates Hamiltonian matrices conditioned on molecular geometry. Flow matching models continuous-time trajectories between simple priors and complex targets, learning the structured distributions over Hamiltonians instead of direct regression. To further incorporate symmetry, we use a neural architecture that predicts SE(3)-equivariant vector fields, improving accuracy and generalization across diverse geometries. To further enhance physical fidelity, we additionally introduce a fine-tuning scheme to align predicted orbital energies with the target. QHFlow achieves state-of-the-art performance, reducing Hamiltonian error by 71% on MD17 and 53% on QH9. Moreover, we further show that QHFlow accelerates the DFT process without trading off the solution quality when initializing SCF iterations with the predicted Hamiltonian, significantly reducing the number of iterations and runtime.
Plane Geometry Problem Solving with Multi-modal Reasoning: A Survey
May 20, 2025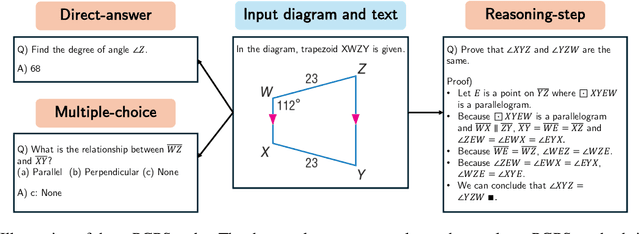
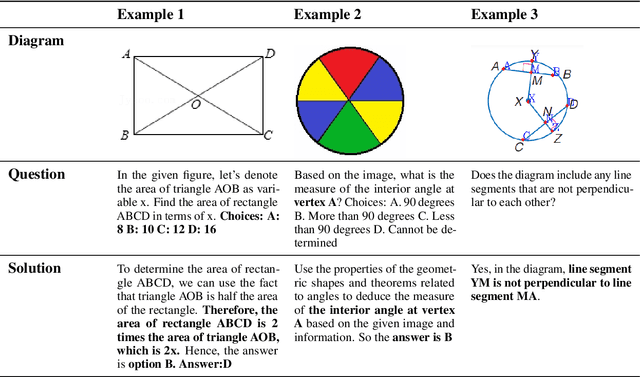
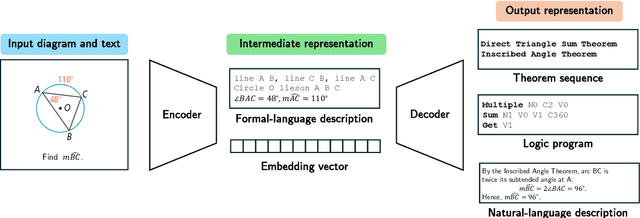
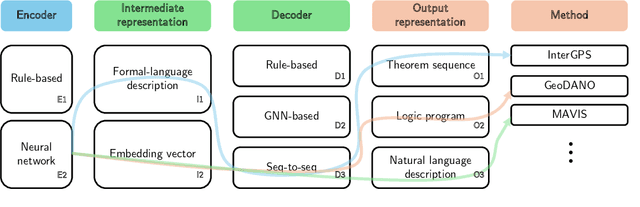
Plane geometry problem solving (PGPS) has recently gained significant attention as a benchmark to assess the multi-modal reasoning capabilities of large vision-language models. Despite the growing interest in PGPS, the research community still lacks a comprehensive overview that systematically synthesizes recent work in PGPS. To fill this gap, we present a survey of existing PGPS studies. We first categorize PGPS methods into an encoder-decoder framework and summarize the corresponding output formats used by their encoders and decoders. Subsequently, we classify and analyze these encoders and decoders according to their architectural designs. Finally, we outline major challenges and promising directions for future research. In particular, we discuss the hallucination issues arising during the encoding phase within encoder-decoder architectures, as well as the problem of data leakage in current PGPS benchmarks.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.