 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEX-Mouse: A Low-cost Portable and Universal Interface with Force Feedback for Data Collection of Dexterous Robotic Hands
Apr 16, 2026Data-driven dexterous hand manipulation requires large-scale, physically consistent demonstration data. Simulation and video-based methods suffer from sim-to-real gaps and retargeting problems, while MoCap glove-based teleoperation systems require per-operator calibration and lack portability, as the robot hand is typically fixed to a stationary arm. Portable alternatives improve mobility but lack cross-platform and cross-operator compatibility. We present DEX-Mouse, a portable, calibration-free hand-held teleoperation interface with integrated kinesthetic force feedback, built from commercial off-the-shelf components under USD 150. The operator-agnostic design requires no calibration or structural modification, enabling immediate deployment across diverse environments and platforms. The interface supports a configuration in which the target robot hand is mounted directly on the forearm of an operator, producing robot-aligned data. In a comparative user study across various dexterous manipulation tasks, operators using the proposed system achieved an 86.67% task completion rate under the attached configuration. Also, we found that the attached configuration reduced the perceived workload of the operators compared to spatially separated teleoperation setups across all compared interfaces. The complete hardware and software stack, including bill of materials, CAD models, and firmware, is open-sourced at https://dex-mouse.github.io/ to facilitate replication and adoption.
High-order Equivariant Flow Matching for Density Functional Theory Hamiltonian Prediction
May 24, 2025Density functional theory (DFT) is a fundamental method for simulating quantum chemical properties, but it remains expensive due to the iterative self-consistent field (SCF) process required to solve the Kohn-Sham equations. Recently, deep learning methods are gaining attention as a way to bypass this step by directly predicting the Hamiltonian. However, they rely on deterministic regression and do not consider the highly structured nature of Hamiltonians. In this work, we propose QHFlow, a high-order equivariant flow matching framework that generates Hamiltonian matrices conditioned on molecular geometry. Flow matching models continuous-time trajectories between simple priors and complex targets, learning the structured distributions over Hamiltonians instead of direct regression. To further incorporate symmetry, we use a neural architecture that predicts SE(3)-equivariant vector fields, improving accuracy and generalization across diverse geometries. To further enhance physical fidelity, we additionally introduce a fine-tuning scheme to align predicted orbital energies with the target. QHFlow achieves state-of-the-art performance, reducing Hamiltonian error by 71% on MD17 and 53% on QH9. Moreover, we further show that QHFlow accelerates the DFT process without trading off the solution quality when initializing SCF iterations with the predicted Hamiltonian, significantly reducing the number of iterations and runtime.
Flexible MOF Generation with Torsion-Aware Flow Matching
May 23, 2025Designing metal-organic frameworks (MOFs) with novel chemistries is a long-standing challenge due to their large combinatorial space and the complex 3D arrangements of building blocks. While recent deep generative models have enabled scalable MOF generation, they assume (1) a fixed set of building blocks and (2) known ground-truth local block-wise 3D coordinates. However, this limits their ability to (1) design novel MOFs and (2) generate the structure using novel building blocks. We propose a two-stage de novo MOF generation framework that overcomes these limitations by modeling both chemical and geometric degrees of freedom. First, we train a SMILES-based autoregressive model to generate novel metal and organic building blocks, paired with cheminformatics for 3D structure initialization. Second, we introduce a flow-matching model that predicts translations, rotations, and torsional angles to assemble flexible blocks into valid 3D frameworks. Our experiments demonstrate improved reconstruction accuracy, the generation of valid, novel, and unique MOFs, and the ability of our model to create novel building blocks.
Automatically Evaluating the Paper Reviewing Capability of Large Language Models
Feb 24, 2025Peer review is essential for scientific progress, but it faces challenges such as reviewer shortages and growing workloads. Although Large Language Models (LLMs) show potential for providing assistance, research has reported significant limitations in the reviews they generate. While the insights are valuable, conducting the analysis is challenging due to the considerable time and effort required, especially given the rapid pace of LLM developments. To address the challenge, we developed an automatic evaluation pipeline to assess the LLMs' paper review capability by comparing them with expert-generated reviews. By constructing a dataset consisting of 676 OpenReview papers, we examined the agreement between LLMs and experts in their strength and weakness identifications. The results showed that LLMs lack balanced perspectives, significantly overlook novelty assessment when criticizing, and produce poor acceptance decisions. Our automated pipeline enables a scalable evaluation of LLMs' paper review capability over time.
Anfinsen Goes Neural: a Graphical Model for Conditional Antibody Design
Feb 08, 2024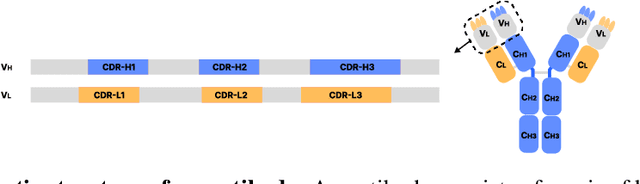
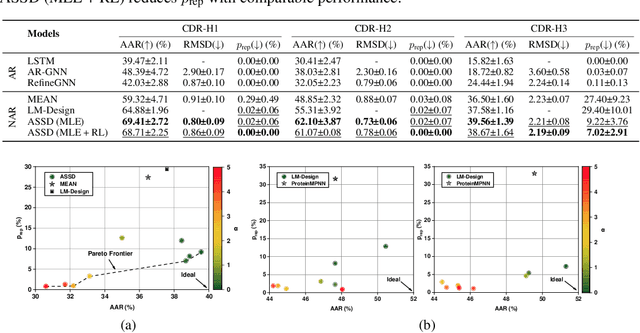

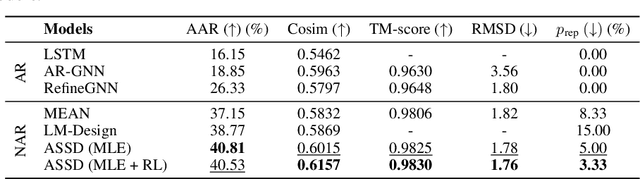
Antibody design plays a pivotal role in advancing therapeutics. Although deep learning has made rapid progress in this field, existing methods make limited use of general protein knowledge and assume a graphical model (GM) that violates empirical findings on proteins. To address these limitations, we present Anfinsen Goes Neural (AGN), a graphical model that uses a pre-trained protein language model (pLM) and encodes a seminal finding on proteins called Anfinsen's dogma. Our framework follows a two-step process of sequence generation with pLM and structure prediction with graph neural network (GNN). Experiments show that our approach outperforms state-of-the-art results on benchmark experiments. We also address a critical limitation of non-autoregressive models -- namely, that they tend to generate unrealistic sequences with overly repeating tokens. To resolve this, we introduce a composition-based regularization term to the cross-entropy objective that allows an efficient trade-off between high performance and low token repetition. We demonstrate that our approach establishes a Pareto frontier over the current state-of-the-art. Our code is available at https://github.com/lkny123/AGN.
STANCE-C3: Domain-adaptive Cross-target Stance Detection via Contrastive Learning and Counterfactual Generation
Sep 26, 2023Stance detection is the process of inferring a person's position or standpoint on a specific issue to deduce prevailing perceptions toward topics of general or controversial interest, such as health policies during the COVID-19 pandemic. Existing models for stance detection are trained to perform well for a single domain (e.g., COVID-19) and a specific target topic (e.g., masking protocols), but are generally ineffectual in other domains or targets due to distributional shifts in the data. However, constructing high-performing, domain-specific stance detection models requires an extensive corpus of labeled data relevant to the targeted domain, yet such datasets are not readily available. This poses a challenge as the process of annotating data is costly and time-consuming. To address these challenges, we introduce a novel stance detection model coined domain-adaptive Cross-target STANCE detection via Contrastive learning and Counterfactual generation (STANCE-C3) that uses counterfactual data augmentation to enhance domain-adaptive training by enriching the target domain dataset during the training process and requiring significantly less information from the new domain. We also propose a modified self-supervised contrastive learning as a component of STANCE-C3 to prevent overfitting for the existing domain and target and enable cross-target stance detection. Through experiments on various datasets, we show that STANCE-C3 shows performance improvement over existing state-of-the-art methods.
Debiasing Word Embeddings with Nonlinear Geometry
Aug 29, 2022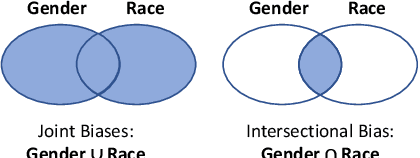
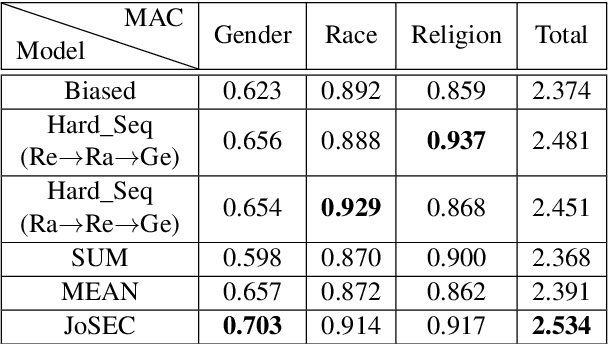
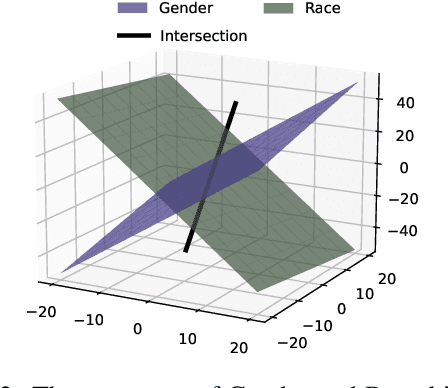

Debiasing word embeddings has been largely limited to individual and independent social categories. However, real-world corpora typically present multiple social categories that possibly correlate or intersect with each other. For instance, "hair weaves" is stereotypically associated with African American females, but neither African American nor females alone. Therefore, this work studies biases associated with multiple social categories: joint biases induced by the union of different categories and intersectional biases that do not overlap with the biases of the constituent categories. We first empirically observe that individual biases intersect non-trivially (i.e., over a one-dimensional subspace). Drawing from the intersectional theory in social science and the linguistic theory, we then construct an intersectional subspace to debias for multiple social categories using the nonlinear geometry of individual biases. Empirical evaluations corroborate the efficacy of our approach. Data and implementation code can be downloaded at https://github.com/GitHubLuCheng/Implementation-of-JoSEC-COLING-22.