 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Data Diversity Shape the Weight Landscape of Neural Networks?
Oct 18, 2024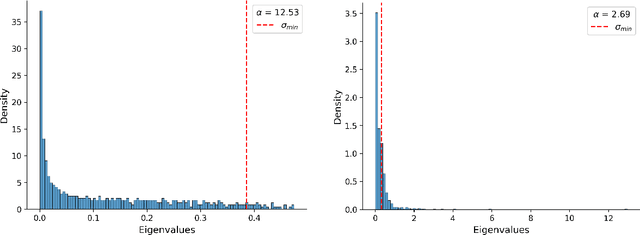
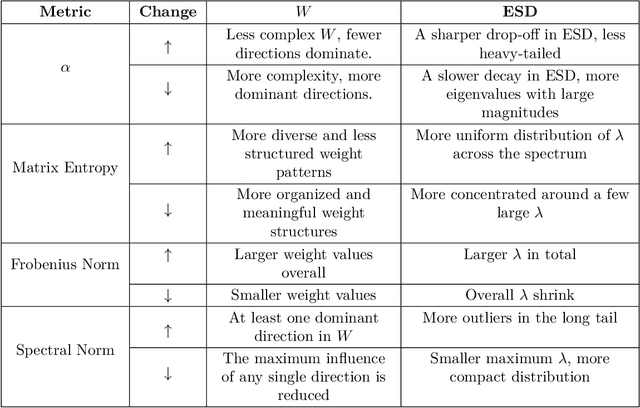
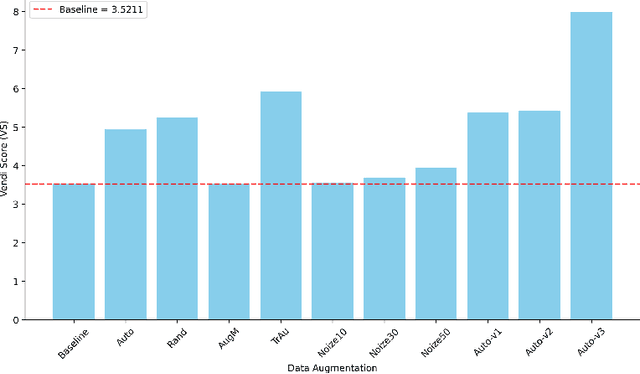
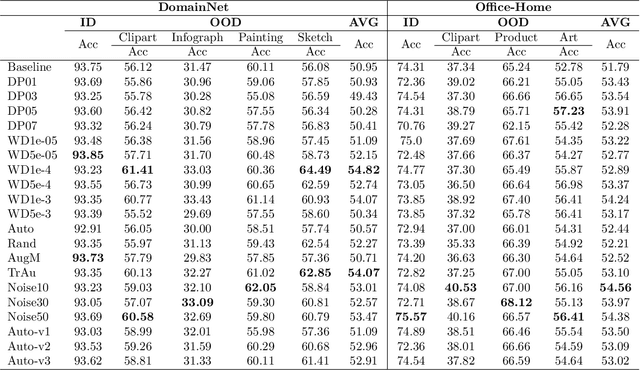
To enhance the generalization of machine learning models to unseen data, techniques such as dropout, weight decay ($L_2$ regularization), and noise augmentation are commonly employed. While regularization methods (i.e., dropout and weight decay) are geared toward adjusting model parameters to prevent overfitting, data augmentation increases the diversity of the input training set, a method purported to improve accuracy and calibration error. In this paper, we investigate the impact of each of these techniques on the parameter space of neural networks, with the goal of understanding how they alter the weight landscape in transfer learning scenarios. To accomplish this, we employ Random Matrix Theory to analyze the eigenvalue distributions of pre-trained models, fine-tuned using these techniques but using different levels of data diversity, for the same downstream tasks. We observe that diverse data influences the weight landscape in a similar fashion as dropout. Additionally, we compare commonly used data augmentation methods with synthetic data created by generative models. We conclude that synthetic data can bring more diversity into real input data, resulting in a better performance on out-of-distribution test instances.
Fill In The Gaps: Model Calibration and Generalization with Synthetic Data
Oct 07, 2024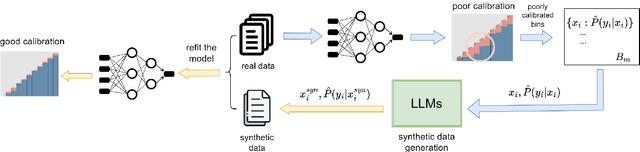
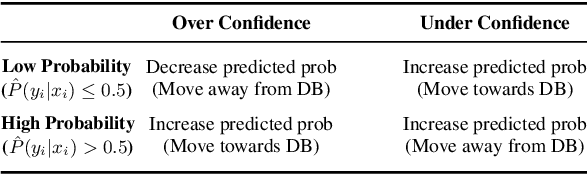
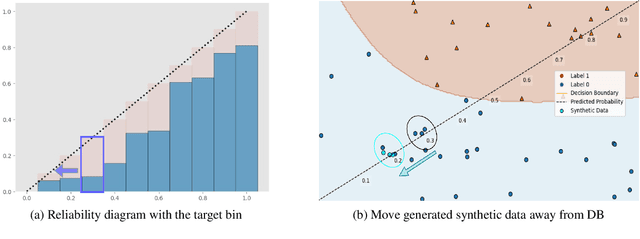
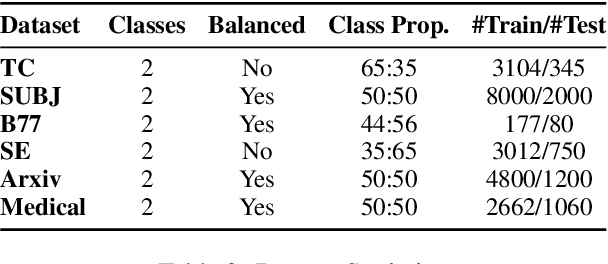
As machine learning models continue to swiftly advance, calibrating their performance has become a major concern prior to practical and widespread implementation. Most existing calibration methods often negatively impact model accuracy due to the lack of diversity of validation data, resulting in reduced generalizability. To address this, we propose a calibration method that incorporates synthetic data without compromising accuracy. We derive the expected calibration error (ECE) bound using the Probably Approximately Correct (PAC) learning framework. Large language models (LLMs), known for their ability to mimic real data and generate text with mixed class labels, are utilized as a synthetic data generation strategy to lower the ECE bound and improve model accuracy on real test data. Additionally, we propose data generation mechanisms for efficient calibration. Testing our method on four different natural language processing tasks, we observed an average up to 34\% increase in accuracy and 33\% decrease in ECE.
STANCE-C3: Domain-adaptive Cross-target Stance Detection via Contrastive Learning and Counterfactual Generation
Sep 26, 2023Stance detection is the process of inferring a person's position or standpoint on a specific issue to deduce prevailing perceptions toward topics of general or controversial interest, such as health policies during the COVID-19 pandemic. Existing models for stance detection are trained to perform well for a single domain (e.g., COVID-19) and a specific target topic (e.g., masking protocols), but are generally ineffectual in other domains or targets due to distributional shifts in the data. However, constructing high-performing, domain-specific stance detection models requires an extensive corpus of labeled data relevant to the targeted domain, yet such datasets are not readily available. This poses a challenge as the process of annotating data is costly and time-consuming. To address these challenges, we introduce a novel stance detection model coined domain-adaptive Cross-target STANCE detection via Contrastive learning and Counterfactual generation (STANCE-C3) that uses counterfactual data augmentation to enhance domain-adaptive training by enriching the target domain dataset during the training process and requiring significantly less information from the new domain. We also propose a modified self-supervised contrastive learning as a component of STANCE-C3 to prevent overfitting for the existing domain and target and enable cross-target stance detection. Through experiments on various datasets, we show that STANCE-C3 shows performance improvement over existing state-of-the-art methods.
Domain Adaptive Fake News Detection via Reinforcement Learning
Feb 16, 2022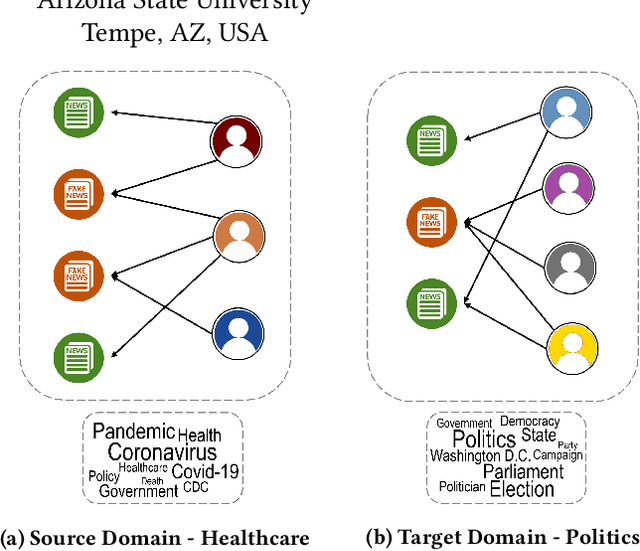
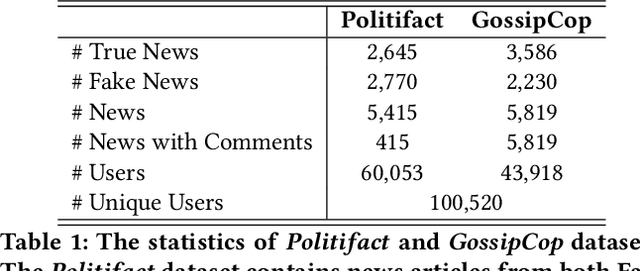
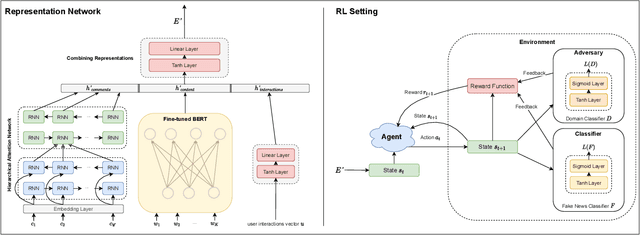
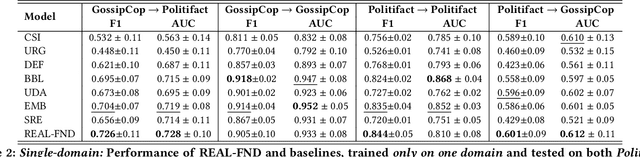
With social media being a major force in information consumption, accelerated propagation of fake news has presented new challenges for platforms to distinguish between legitimate and fake news. Effective fake news detection is a non-trivial task due to the diverse nature of news domains and expensive annotation costs. In this work, we address the limitations of existing automated fake news detection models by incorporating auxiliary information (e.g., user comments and user-news interactions) into a novel reinforcement learning-based model called \textbf{RE}inforced \textbf{A}daptive \textbf{L}earning \textbf{F}ake \textbf{N}ews \textbf{D}etection (REAL-FND). REAL-FND exploits cross-domain and within-domain knowledge that makes it robust in a target domain, despite being trained in a different source domain. Extensive experiments on real-world datasets illustrate the effectiveness of the proposed model, especially when limited labeled data is available in the target domain.
Toward Privacy and Utility Preserving Image Representation
Oct 17, 2020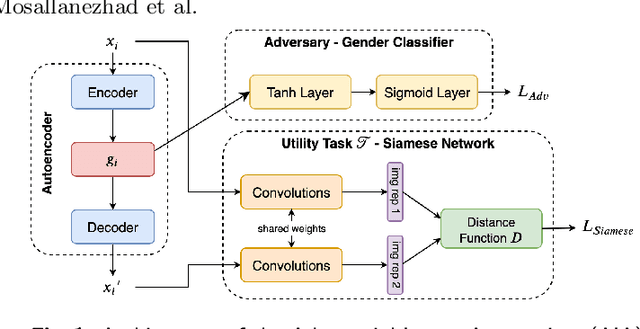
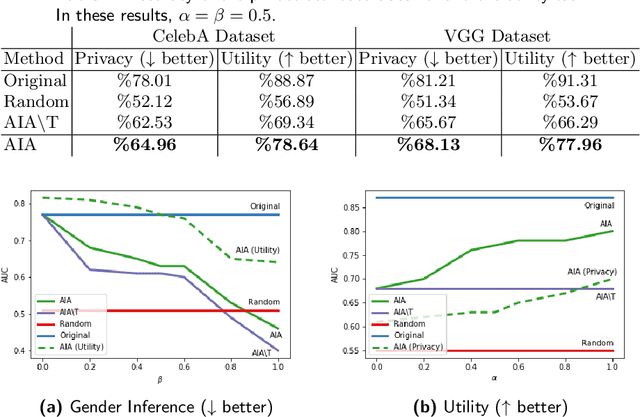

Face images are rich data items that are useful and can easily be collected in many applications, such as in 1-to-1 face verification tasks in the domain of security and surveillance systems. Multiple methods have been proposed to protect an individual's privacy by perturbing the images to remove traces of identifiable information, such as gender or race. However, significantly less attention has been given to the problem of protecting images while maintaining optimal task utility. In this paper, we study the novel problem of creating privacy-preserving image representations with respect to a given utility task by proposing a principled framework called the Adversarial Image Anonymizer (AIA). AIA first creates an image representation using a generative model, then enhances the learned image representations using adversarial learning to preserve privacy and utility for a given task. Experiments were conducted on a publicly available data set to demonstrate the effectiveness of AIA as a privacy-preserving mechanism for face images.