 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Topic Exposure for Under-Represented Users on Social Media
Aug 07, 2022
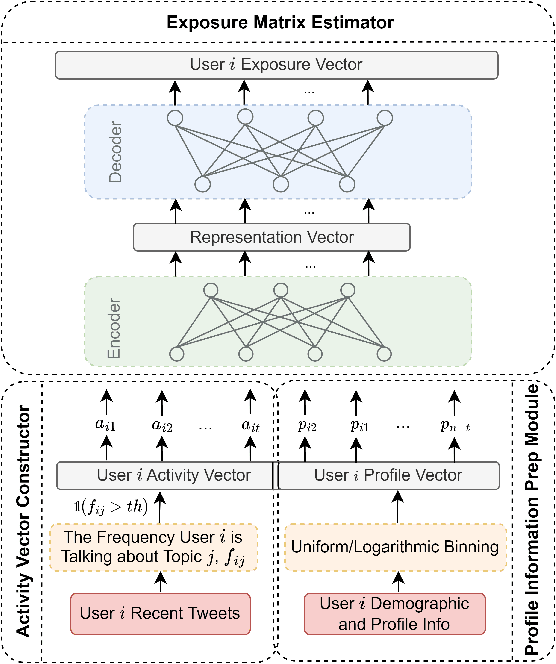
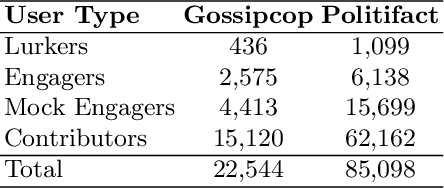

Online Social Networks (OSNs) facilitate access to a variety of data allowing researchers to analyze users' behavior and develop user behavioral analysis models. These models rely heavily on the observed data which is usually biased due to the participation inequality. This inequality consists of three groups of online users: the lurkers - users that solely consume the content, the engagers - users that contribute little to the content creation, and the contributors - users that are responsible for creating the majority of the online content. Failing to consider the contribution of all the groups while interpreting population-level interests or sentiments may yield biased results. To reduce the bias induced by the contributors, in this work, we focus on highlighting the engagers' contributions in the observed data as they are more likely to contribute when compared to lurkers, and they comprise a bigger population as compared to the contributors. The first step in behavioral analysis of these users is to find the topics they are exposed to but did not engage with. To do so, we propose a novel framework that aids in identifying these users and estimates their topic exposure. The exposure estimation mechanism is modeled by incorporating behavioral patterns from similar contributors as well as users' demographic and profile information.
Domain Adaptive Fake News Detection via Reinforcement Learning
Feb 16, 2022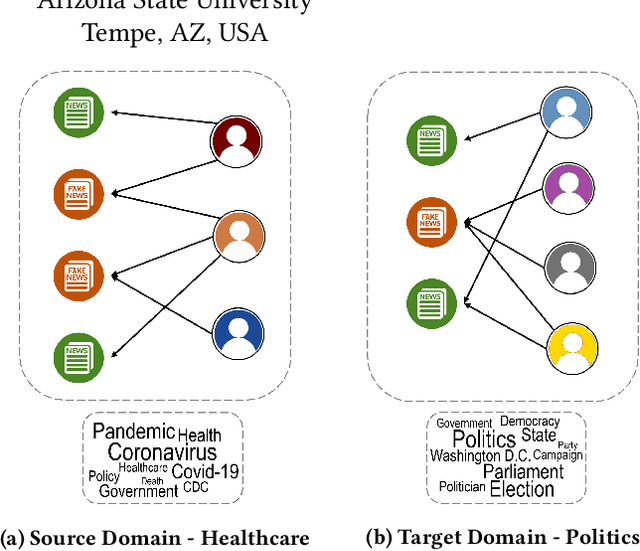
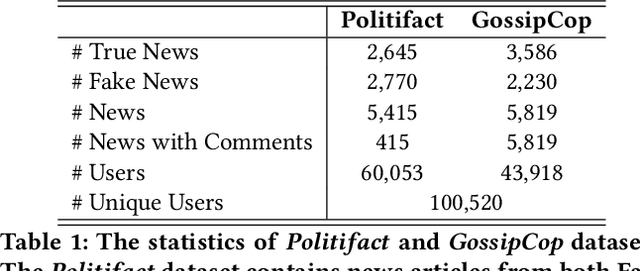
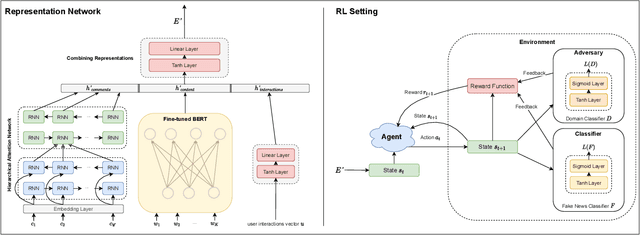
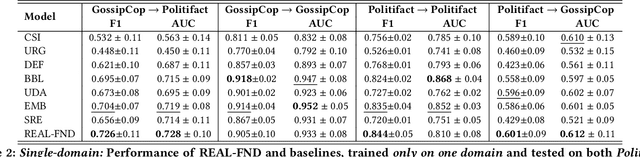
With social media being a major force in information consumption, accelerated propagation of fake news has presented new challenges for platforms to distinguish between legitimate and fake news. Effective fake news detection is a non-trivial task due to the diverse nature of news domains and expensive annotation costs. In this work, we address the limitations of existing automated fake news detection models by incorporating auxiliary information (e.g., user comments and user-news interactions) into a novel reinforcement learning-based model called \textbf{RE}inforced \textbf{A}daptive \textbf{L}earning \textbf{F}ake \textbf{N}ews \textbf{D}etection (REAL-FND). REAL-FND exploits cross-domain and within-domain knowledge that makes it robust in a target domain, despite being trained in a different source domain. Extensive experiments on real-world datasets illustrate the effectiveness of the proposed model, especially when limited labeled data is available in the target domain.
Causal Learning for Socially Responsible AI
Apr 25, 2021

There have been increasing concerns about Artificial Intelligence (AI) due to its unfathomable potential power. To make AI address ethical challenges and shun undesirable outcomes, researchers proposed to develop socially responsible AI (SRAI). One of these approaches is causal learning (CL). We survey state-of-the-art methods of CL for SRAI. We begin by examining the seven CL tools to enhance the social responsibility of AI, then review how existing works have succeeded using these tools to tackle issues in developing SRAI such as fairness. The goal of this survey is to bring forefront the potentials and promises of CL for SRAI.
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
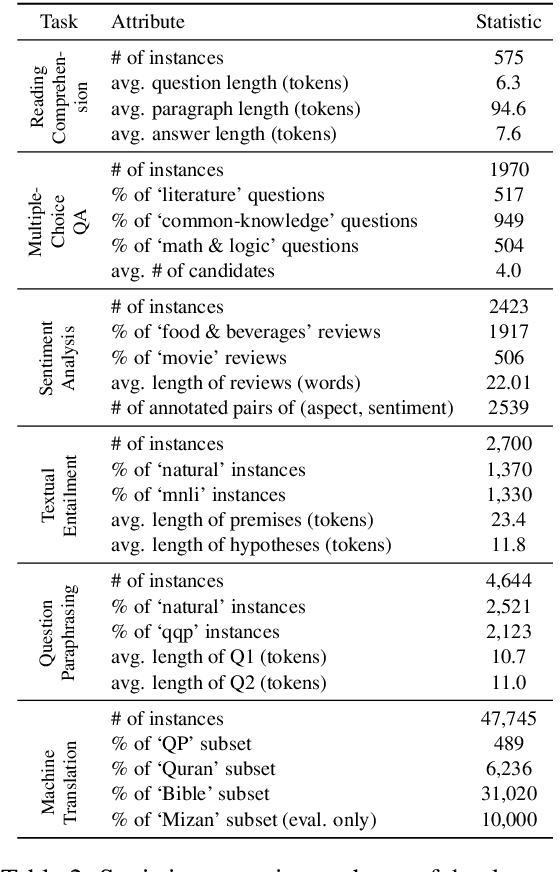
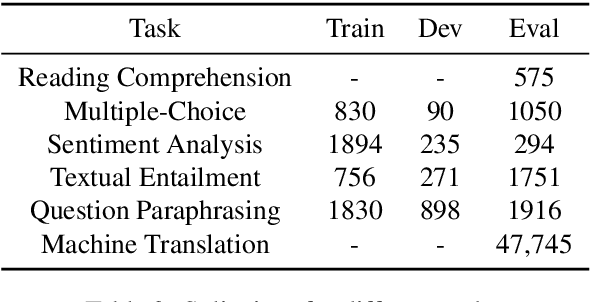
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.
"Let's Eat Grandma": When Punctuation Matters in Sentence Representation for Sentiment Analysis
Dec 10, 2020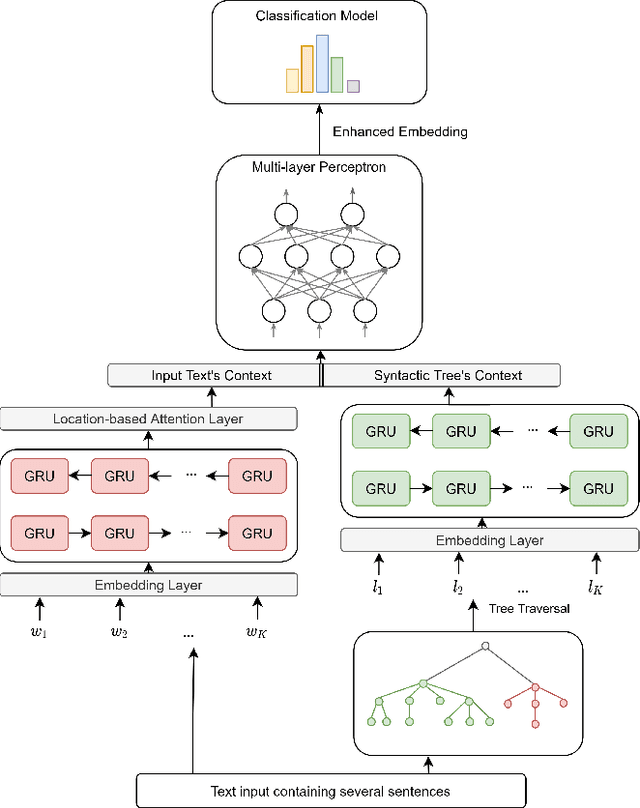

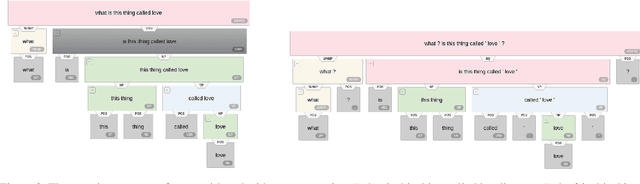
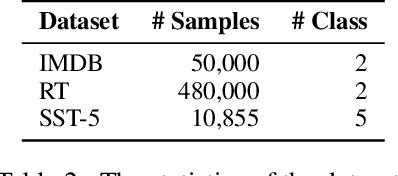
Neural network-based embeddings have been the mainstream approach for creating a vector representation of the text to capture lexical and semantic similarities and dissimilarities. In general, existing encoding methods dismiss the punctuation as insignificant information; consequently, they are routinely eliminated in the pre-processing phase as they are shown to improve task performance. In this paper, we hypothesize that punctuation could play a significant role in sentiment analysis and propose a novel representation model to improve syntactic and contextual performance. We corroborate our findings by conducting experiments on publicly available datasets and verify that our model can identify the sentiments more accurately over other state-of-the-art baseline methods.
Topic-Preserving Synthetic News Generation: An Adversarial Deep Reinforcement Learning Approach
Oct 30, 2020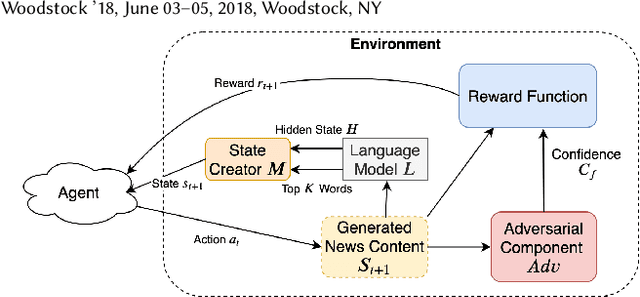
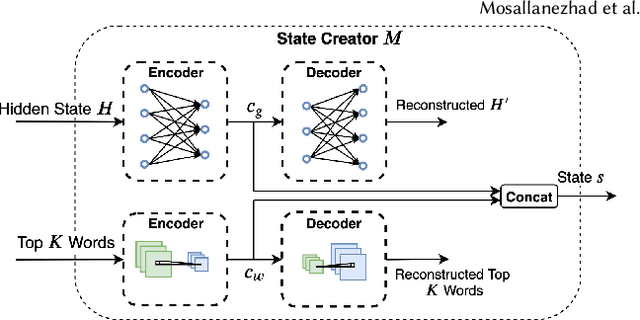
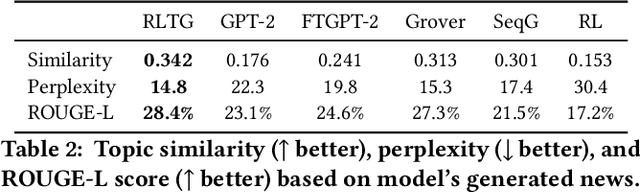
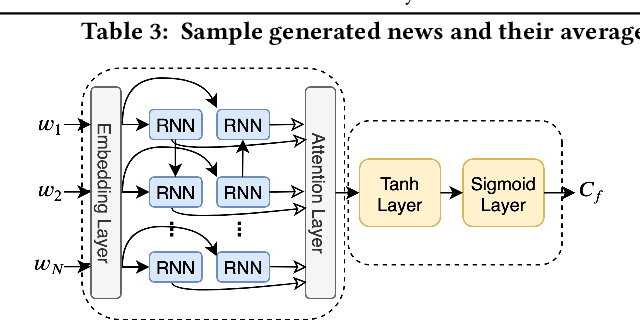
Nowadays, there exist powerful language models such as OpenAI's GPT-2 that can generate readable text and can be fine-tuned to generate text for a specific domain. Considering GPT-2, it cannot directly generate synthetic news with respect to a given topic and the output of the language model cannot be explicitly controlled. In this paper, we study the novel problem of topic-preserving synthetic news generation. We propose a novel deep reinforcement learning-based method to control the output of GPT-2 with respect to a given news topic. When generating text using GPT-2, by default, the most probable word is selected from the vocabulary. Instead of selecting the best word each time from GPT-2's output, an RL agent tries to select words that optimize the matching of a given topic. In addition, using a fake news detector as an adversary, we investigate generating realistic news using our proposed method. In this paper, we consider realistic news as news that cannot be easily detected by a fake news classifier. Experimental results demonstrate the effectiveness of the proposed framework on generating topic-preserving news content than state-of-the-art baselines.
Toward Privacy and Utility Preserving Image Representation
Oct 17, 2020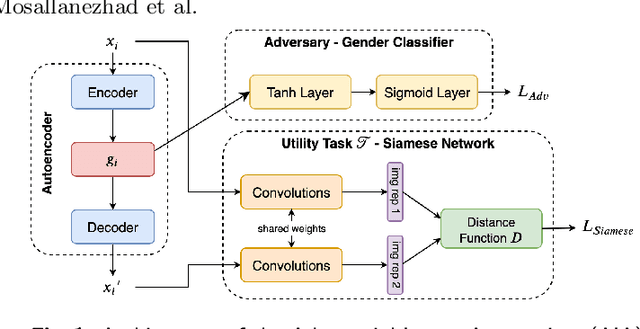
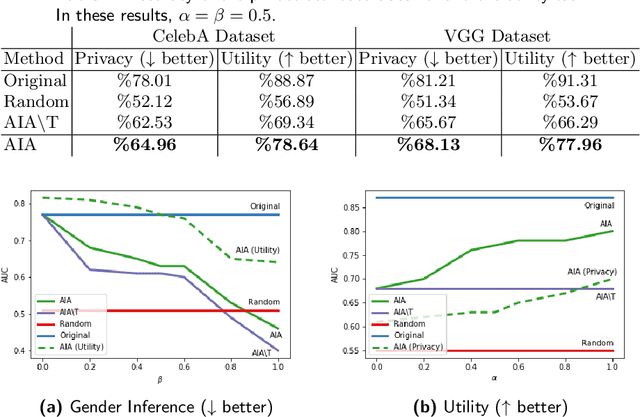

Face images are rich data items that are useful and can easily be collected in many applications, such as in 1-to-1 face verification tasks in the domain of security and surveillance systems. Multiple methods have been proposed to protect an individual's privacy by perturbing the images to remove traces of identifiable information, such as gender or race. However, significantly less attention has been given to the problem of protecting images while maintaining optimal task utility. In this paper, we study the novel problem of creating privacy-preserving image representations with respect to a given utility task by proposing a principled framework called the Adversarial Image Anonymizer (AIA). AIA first creates an image representation using a generative model, then enhances the learned image representations using adversarial learning to preserve privacy and utility for a given task. Experiments were conducted on a publicly available data set to demonstrate the effectiveness of AIA as a privacy-preserving mechanism for face images.