 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAXCEL: Automated eXplainable Consistency Evaluation using LLMs
Sep 25, 2024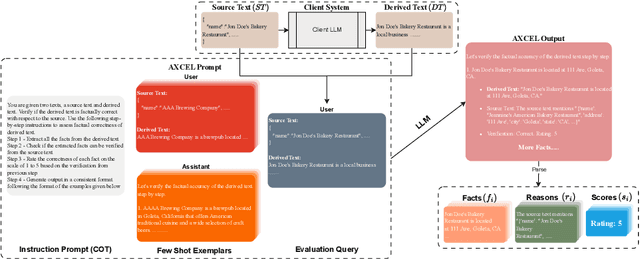
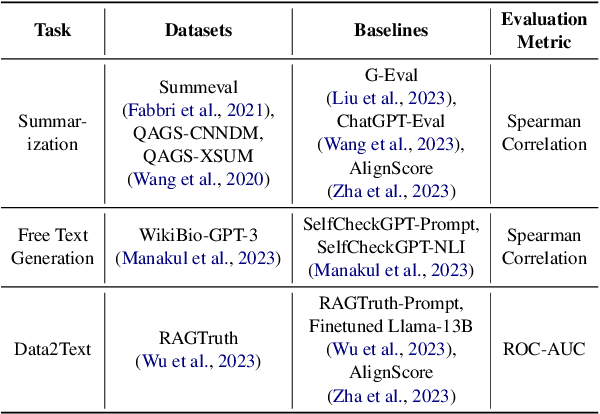
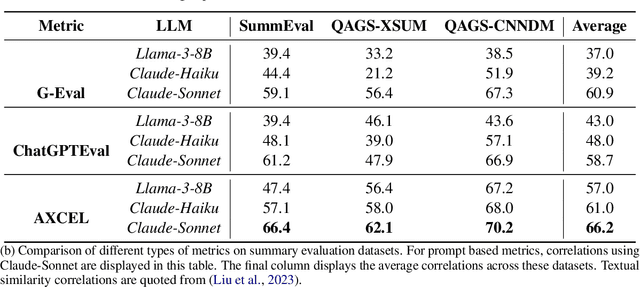
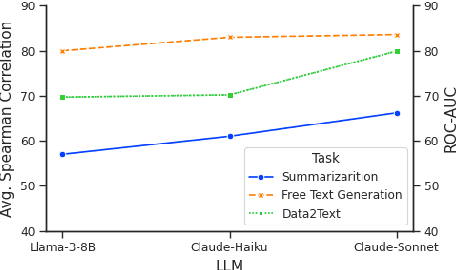
Large Language Models (LLMs) are widely used in both industry and academia for various tasks, yet evaluating the consistency of generated text responses continues to be a challenge. Traditional metrics like ROUGE and BLEU show a weak correlation with human judgment. More sophisticated metrics using Natural Language Inference (NLI) have shown improved correlations but are complex to implement, require domain-specific training due to poor cross-domain generalization, and lack explainability. More recently, prompt-based metrics using LLMs as evaluators have emerged; while they are easier to implement, they still lack explainability and depend on task-specific prompts, which limits their generalizability. This work introduces Automated eXplainable Consistency Evaluation using LLMs (AXCEL), a prompt-based consistency metric which offers explanations for the consistency scores by providing detailed reasoning and pinpointing inconsistent text spans. AXCEL is also a generalizable metric which can be adopted to multiple tasks without changing the prompt. AXCEL outperforms both non-prompt and prompt-based state-of-the-art (SOTA) metrics in detecting inconsistencies across summarization by 8.7%, free text generation by 6.2%, and data-to-text conversion tasks by 29.4%. We also evaluate the influence of underlying LLMs on prompt based metric performance and recalibrate the SOTA prompt-based metrics with the latest LLMs for fair comparison. Further, we show that AXCEL demonstrates strong performance using open source LLMs.
Overview of Robust and Multilingual Automatic Evaluation Metrics for Open-Domain Dialogue Systems at DSTC 11 Track 4
Jun 22, 2023



The advent and fast development of neural networks have revolutionized the research on dialogue systems and subsequently have triggered various challenges regarding their automatic evaluation. Automatic evaluation of open-domain dialogue systems as an open challenge has been the center of the attention of many researchers. Despite the consistent efforts to improve automatic metrics' correlations with human evaluation, there have been very few attempts to assess their robustness over multiple domains and dimensions. Also, their focus is mainly on the English language. All of these challenges prompt the development of automatic evaluation metrics that are reliable in various domains, dimensions, and languages. This track in the 11th Dialogue System Technology Challenge (DSTC11) is part of the ongoing effort to promote robust and multilingual automatic evaluation metrics. This article describes the datasets and baselines provided to participants and discusses the submission and result details of the two proposed subtasks.
ACCENT: An Automatic Event Commonsense Evaluation Metric for Open-Domain Dialogue Systems
May 12, 2023



Commonsense reasoning is omnipresent in human communications and thus is an important feature for open-domain dialogue systems. However, evaluating commonsense in dialogue systems is still an open challenge. We take the first step by focusing on event commonsense that considers events and their relations, and is crucial in both dialogues and general commonsense reasoning. We propose ACCENT, an event commonsense evaluation metric empowered by commonsense knowledge bases (CSKBs). ACCENT first extracts event-relation tuples from a dialogue, and then evaluates the response by scoring the tuples in terms of their compatibility with the CSKB. To evaluate ACCENT, we construct the first public event commonsense evaluation dataset for open-domain dialogues. Our experiments show that ACCENT is an efficient metric for event commonsense evaluation, which achieves higher correlations with human judgments than existing baselines.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
What is wrong with you?: Leveraging User Sentiment for Automatic Dialog Evaluation
Mar 25, 2022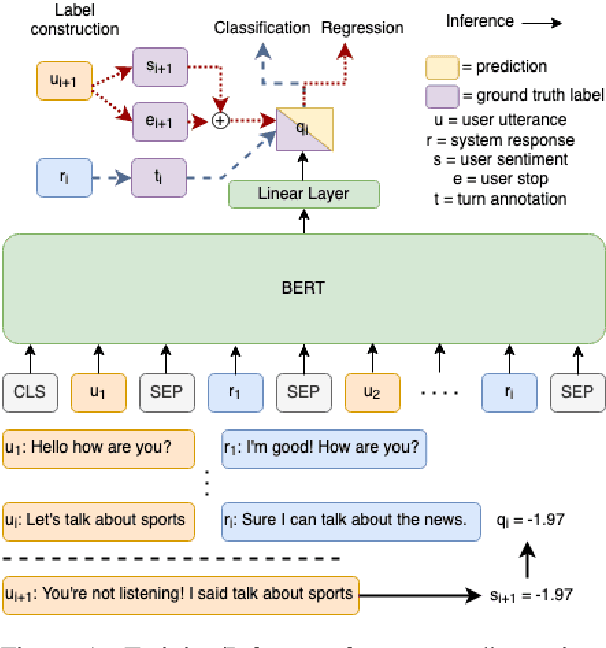

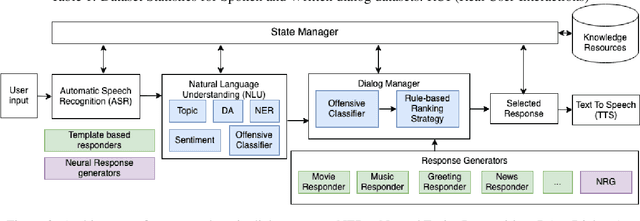
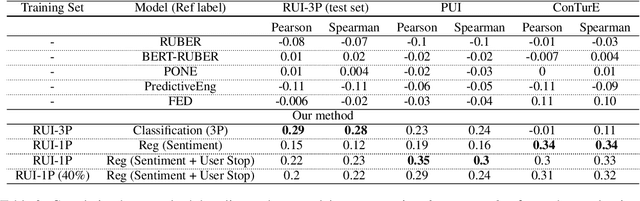
Accurate automatic evaluation metrics for open-domain dialogs are in high demand. Existing model-based metrics for system response evaluation are trained on human annotated data, which is cumbersome to collect. In this work, we propose to use information that can be automatically extracted from the next user utterance, such as its sentiment or whether the user explicitly ends the conversation, as a proxy to measure the quality of the previous system response. This allows us to train on a massive set of dialogs with weak supervision, without requiring manual system turn quality annotations. Experiments show that our model is comparable to models trained on human annotated data. Furthermore, our model generalizes across both spoken and written open-domain dialog corpora collected from real and paid users.
DEAM: Dialogue Coherence Evaluation using AMR-based Semantic Manipulations
Mar 18, 2022
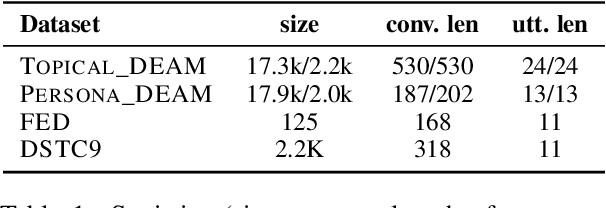
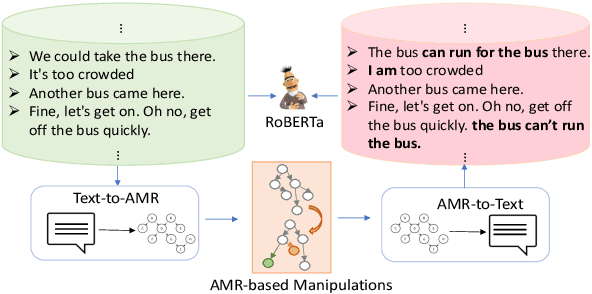
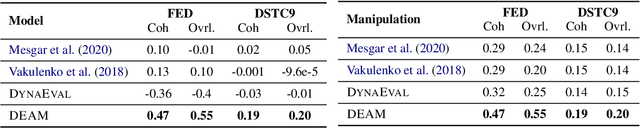
Automatic evaluation metrics are essential for the rapid development of open-domain dialogue systems as they facilitate hyper-parameter tuning and comparison between models. Although recently proposed trainable conversation-level metrics have shown encouraging results, the quality of the metrics is strongly dependent on the quality of training data. Prior works mainly resort to heuristic text-level manipulations (e.g. utterances shuffling) to bootstrap incoherent conversations (negative examples) from coherent dialogues (positive examples). Such approaches are insufficient to appropriately reflect the incoherence that occurs in interactions between advanced dialogue models and humans. To tackle this problem, we propose DEAM, a Dialogue coherence Evaluation metric that relies on Abstract Meaning Representation (AMR) to apply semantic-level Manipulations for incoherent (negative) data generation. AMRs naturally facilitate the injection of various types of incoherence sources, such as coreference inconsistency, irrelevancy, contradictions, and decrease engagement, at the semantic level, thus resulting in more natural incoherent samples. Our experiments show that DEAM achieves higher correlations with human judgments compared to baseline methods on several dialog datasets by significant margins. We also show that DEAM can distinguish between coherent and incoherent dialogues generated by baseline manipulations, whereas those baseline models cannot detect incoherent examples generated by DEAM. Our results demonstrate the potential of AMR-based semantic manipulations for natural negative example generation.
User Response and Sentiment Prediction for Automatic Dialogue Evaluation
Nov 16, 2021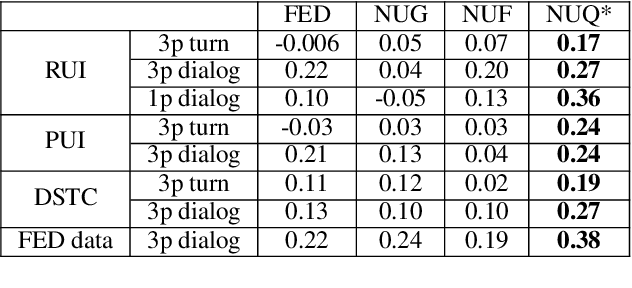
Automatic evaluation is beneficial for open-domain dialog system development. However, standard word-overlap metrics (BLEU, ROUGE) do not correlate well with human judgements of open-domain dialog systems. In this work we propose to use the sentiment of the next user utterance for turn or dialog level evaluation. Specifically we propose three methods: one that predicts the next sentiment directly, and two others that predict the next user utterance using an utterance or a feedback generator model and then classify its sentiment. Experiments show our model outperforming existing automatic evaluation metrics on both written and spoken open-domain dialogue datasets.
Plot-guided Adversarial Example Construction for Evaluating Open-domain Story Generation
Apr 12, 2021
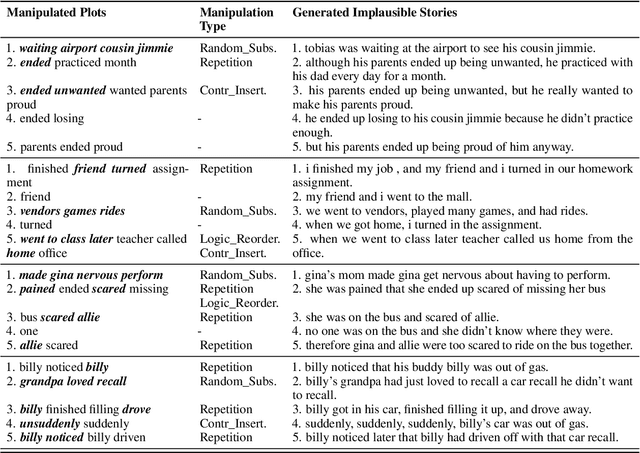
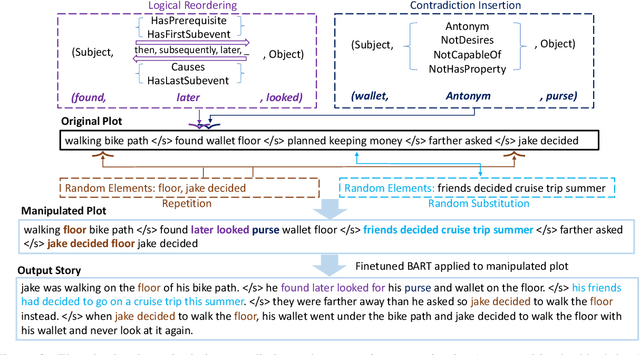
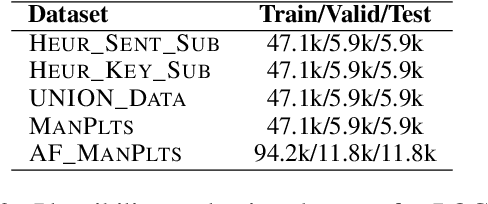
With the recent advances of open-domain story generation, the lack of reliable automatic evaluation metrics becomes an increasingly imperative issue that hinders the fast development of story generation. According to conducted researches in this regard, learnable evaluation metrics have promised more accurate assessments by having higher correlations with human judgments. A critical bottleneck of obtaining a reliable learnable evaluation metric is the lack of high-quality training data for classifiers to efficiently distinguish plausible and implausible machine-generated stories. Previous works relied on \textit{heuristically manipulated} plausible examples to mimic possible system drawbacks such as repetition, contradiction, or irrelevant content in the text level, which can be \textit{unnatural} and \textit{oversimplify} the characteristics of implausible machine-generated stories. We propose to tackle these issues by generating a more comprehensive set of implausible stories using {\em plots}, which are structured representations of controllable factors used to generate stories. Since these plots are compact and structured, it is easier to manipulate them to generate text with targeted undesirable properties, while at the same time maintain the grammatical correctness and naturalness of the generated sentences. To improve the quality of generated implausible stories, we further apply the adversarial filtering procedure presented by \citet{zellers2018swag} to select a more nuanced set of implausible texts. Experiments show that the evaluation metrics trained on our generated data result in more reliable automatic assessments that correlate remarkably better with human judgments compared to the baselines.
DiSCoL: Toward Engaging Dialogue Systems through Conversational Line Guided Response Generation
Feb 03, 2021
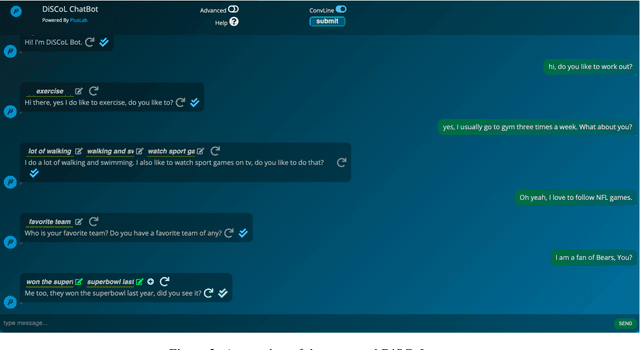
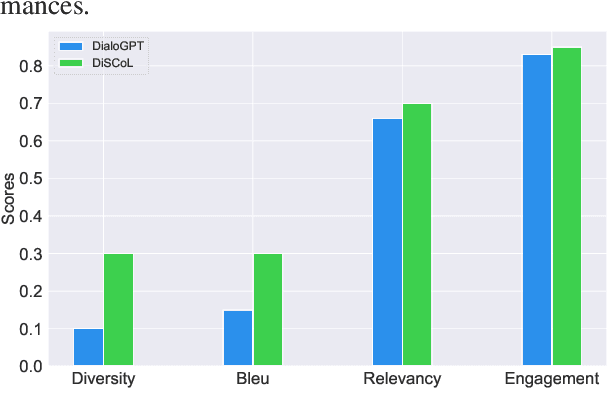
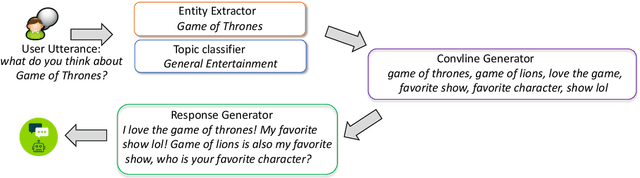
Having engaging and informative conversations with users is the utmost goal for open-domain conversational systems. Recent advances in transformer-based language models and their applications to dialogue systems have succeeded to generate fluent and human-like responses. However, they still lack control over the generation process towards producing contentful responses and achieving engaging conversations. To achieve this goal, we present \textbf{DiSCoL} (\textbf{Di}alogue \textbf{S}ystems through \textbf{Co}versational \textbf{L}ine guided response generation). DiSCoL is an open-domain dialogue system that leverages conversational lines (briefly \textbf{convlines}) as controllable and informative content-planning elements to guide the generation model produce engaging and informative responses. Two primary modules in DiSCoL's pipeline are conditional generators trained for 1) predicting relevant and informative convlines for dialogue contexts and 2) generating high-quality responses conditioned on the predicted convlines. Users can also change the returned convlines to \textit{control} the direction of the conversations towards topics that are more interesting for them. Through automatic and human evaluations, we demonstrate the efficiency of the convlines in producing engaging conversations.
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
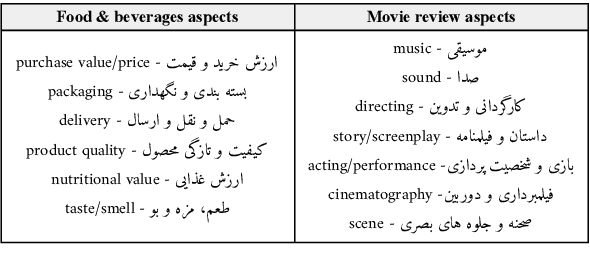
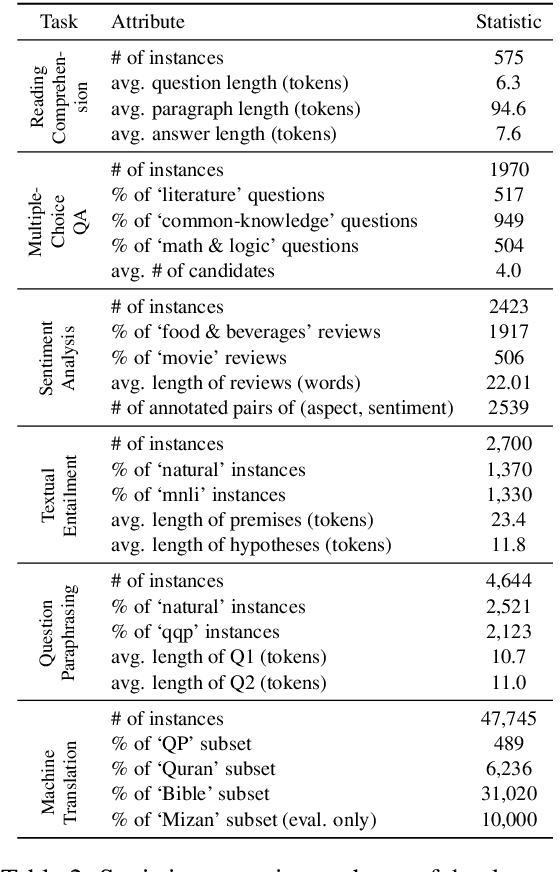
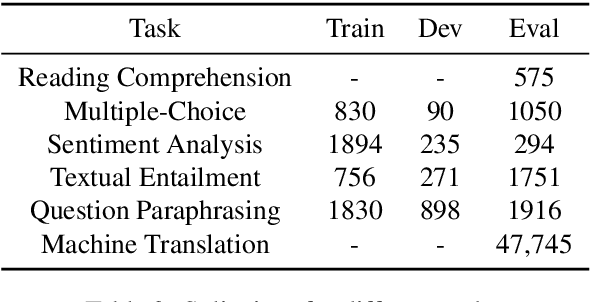
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.