 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Steerable Agentic Data Generation for Deep Search with Execution Feedback
Jan 26, 2026Deep search agents, which aim to answer complex questions requiring reasoning across multiple documents, can significantly speed up the information-seeking process. Collecting human annotations for this application is prohibitively expensive due to long and complex exploration trajectories. We propose an agentic pipeline that automatically generates high quality, difficulty-controlled deep search question-answer pairs for a given corpus and a target difficulty level. Our pipeline, SAGE, consists of a data generator which proposes QA pairs and a search agent which attempts to solve the generated question and provide execution feedback for the data generator. The two components interact over multiple rounds to iteratively refine the question-answer pairs until they satisfy the target difficulty level. Our intrinsic evaluation shows SAGE generates questions that require diverse reasoning strategies, while significantly increases the correctness and difficulty of the generated data. Our extrinsic evaluation demonstrates up to 23% relative performance gain on popular deep search benchmarks by training deep search agents with our synthetic data. Additional experiments show that agents trained on our data can adapt from fixed-corpus retrieval to Google Search at inference time, without further training.
Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
Oct 29, 2025Large Language Models (LLMs) often struggle with problems that require multi-step reasoning. For small-scale open-source models, Reinforcement Learning with Verifiable Rewards (RLVR) fails when correct solutions are rarely sampled even after many attempts, while Supervised Fine-Tuning (SFT) tends to overfit long demonstrations through rigid token-by-token imitation. To address this gap, we propose Supervised Reinforcement Learning (SRL), a framework that reformulates problem solving as generating a sequence of logical "actions". SRL trains the model to generate an internal reasoning monologue before committing to each action. It provides smoother rewards based on the similarity between the model's actions and expert actions extracted from the SFT dataset in a step-wise manner. This supervision offers richer learning signals even when all rollouts are incorrect, while encouraging flexible reasoning guided by expert demonstrations. As a result, SRL enables small models to learn challenging problems previously unlearnable by SFT or RLVR. Moreover, initializing training with SRL before refining with RLVR yields the strongest overall performance. Beyond reasoning benchmarks, SRL generalizes effectively to agentic software engineering tasks, establishing it as a robust and versatile training framework for reasoning-oriented LLMs.
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
Mar 11, 2025Large Language Models (LLMs) have made significant progress in open-ended dialogue, yet their inability to retain and retrieve relevant information from long-term interactions limits their effectiveness in applications requiring sustained personalization. External memory mechanisms have been proposed to address this limitation, enabling LLMs to maintain conversational continuity. However, existing approaches struggle with two key challenges. First, rigid memory granularity fails to capture the natural semantic structure of conversations, leading to fragmented and incomplete representations. Second, fixed retrieval mechanisms cannot adapt to diverse dialogue contexts and user interaction patterns. In this work, we propose Reflective Memory Management (RMM), a novel mechanism for long-term dialogue agents, integrating forward- and backward-looking reflections: (1) Prospective Reflection, which dynamically summarizes interactions across granularities-utterances, turns, and sessions-into a personalized memory bank for effective future retrieval, and (2) Retrospective Reflection, which iteratively refines the retrieval in an online reinforcement learning (RL) manner based on LLMs' cited evidence. Experiments show that RMM demonstrates consistent improvement across various metrics and benchmarks. For example, RMM shows more than 10% accuracy improvement over the baseline without memory management on the LongMemEval dataset.
Reverse Thinking Makes LLMs Stronger Reasoners
Nov 29, 2024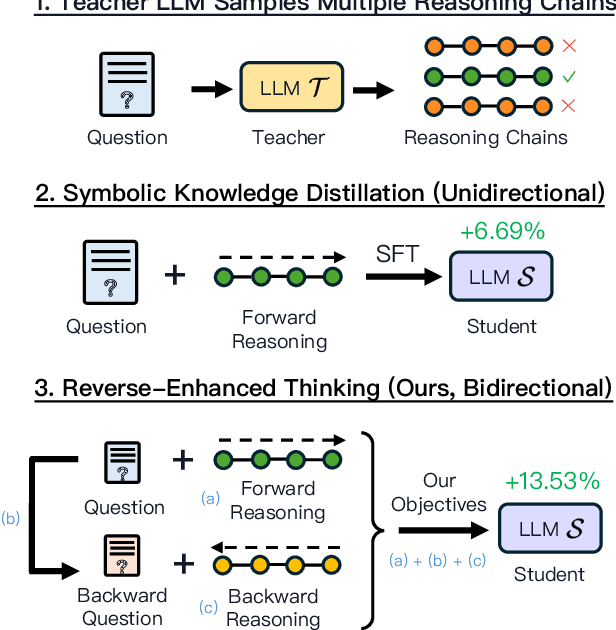
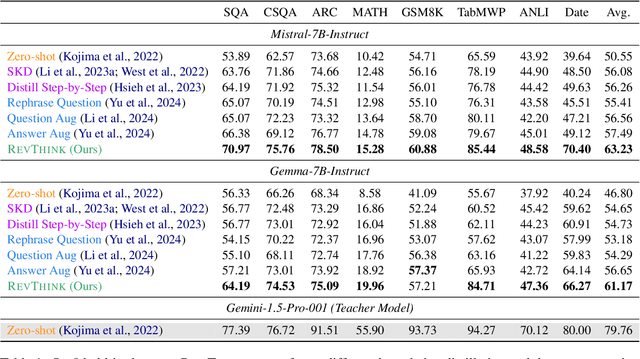
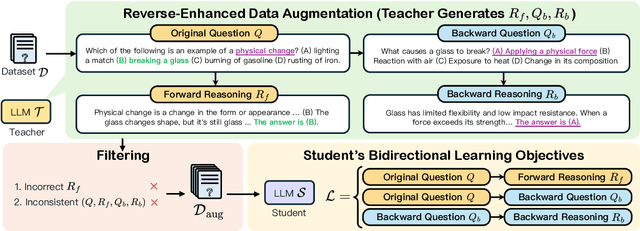
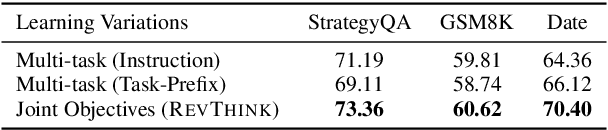
Reverse thinking plays a crucial role in human reasoning. Humans can reason not only from a problem to a solution but also in reverse, i.e., start from the solution and reason towards the problem. This often enhances overall reasoning performance as it enables consistency checks between their forward and backward thinking. To enable Large Language Models (LLMs) to perform reverse thinking, we introduce Reverse-Enhanced Thinking (RevThink), a framework composed of data augmentation and learning objectives. In RevThink, we augment the dataset by collecting structured forward-backward reasoning from a teacher model, consisting of: (1) the original question, (2) forward reasoning, (3) backward question, and (4) backward reasoning. We then employ three objectives to train a smaller student model in a multi-task learning fashion: (a) generate forward reasoning from a question, (b) generate a backward question from a question, and (c) generate backward reasoning from the backward question. Experiments across 12 datasets covering commonsense, math, and logical reasoning show an average 13.53% improvement over the student model's zero-shot performance and a 6.84% improvement over the strongest knowledge distillation baselines. Moreover, our method demonstrates sample efficiency -- using only 10% of the correct forward reasoning from the training data, it outperforms a standard fine-tuning method trained on 10x more forward reasoning. RevThink also exhibits strong generalization to out-of-distribution held-out datasets.
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling
Oct 15, 2024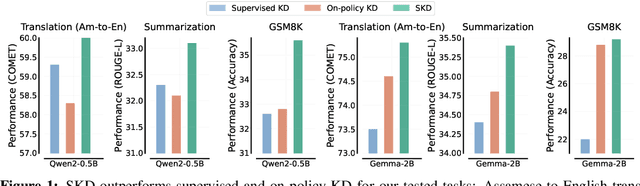
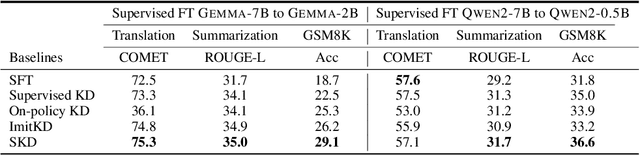

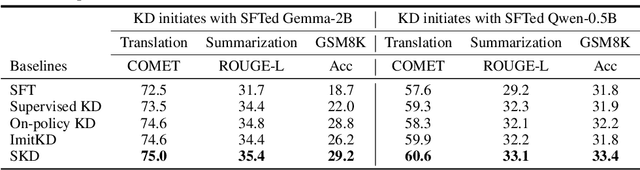
Recent advances in knowledge distillation (KD) have enabled smaller student models to approach the performance of larger teacher models. However, popular methods such as supervised KD and on-policy KD, are adversely impacted by the knowledge gaps between teacher-student in practical scenarios. Supervised KD suffers from a distribution mismatch between training with a static dataset and inference over final student-generated outputs. Conversely, on-policy KD, which uses student-generated samples for training, can suffer from low-quality training examples with which teacher models are not familiar, resulting in inaccurate teacher feedback. To address these limitations, we introduce Speculative Knowledge Distillation (SKD), a novel approach that leverages cooperation between student and teacher models to generate high-quality training data on-the-fly while aligning with the student's inference-time distribution. In SKD, the student proposes tokens, and the teacher replaces poorly ranked ones based on its own distribution, transferring high-quality knowledge adaptively. We evaluate SKD on various text generation tasks, including translation, summarization, math, and instruction following, and show that SKD consistently outperforms existing KD methods across different domains, data sizes, and model initialization strategies.
Dancing in Chains: Reconciling Instruction Following and Faithfulness in Language Models
Jul 31, 2024Modern language models (LMs) need to follow human instructions while being faithful; yet, they often fail to achieve both. Here, we provide concrete evidence of a trade-off between instruction following (i.e., follow open-ended instructions) and faithfulness (i.e., ground responses in given context) when training LMs with these objectives. For instance, fine-tuning LLaMA-7B on instruction following datasets renders it less faithful. Conversely, instruction-tuned Vicuna-7B shows degraded performance at following instructions when further optimized on tasks that require contextual grounding. One common remedy is multi-task learning (MTL) with data mixing, yet it remains far from achieving a synergic outcome. We propose a simple yet effective method that relies on Rejection Sampling for Continued Self-instruction Tuning (ReSet), which significantly outperforms vanilla MTL. Surprisingly, we find that less is more, as training ReSet with high-quality, yet substantially smaller data (three-fold less) yields superior results. Our findings offer a better understanding of objective discrepancies in alignment training of LMs.
RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering
Jul 19, 2024Question answering based on retrieval augmented generation (RAG-QA) is an important research topic in NLP and has a wide range of real-world applications. However, most existing datasets for this task are either constructed using a single source corpus or consist of short extractive answers, which fall short of evaluating large language model (LLM) based RAG-QA systems on cross-domain generalization. To address these limitations, we create Long-form RobustQA (LFRQA), a new dataset comprising human-written long-form answers that integrate short extractive answers from multiple documents into a single, coherent narrative, covering 26K queries and large corpora across seven different domains. We further propose RAG-QA Arena by directly comparing model-generated answers against LFRQA's answers using LLMs as evaluators. We show via extensive experiments that RAG-QA Arena and human judgments on answer quality are highly correlated. Moreover, only 41.3% of the most competitive LLM's answers are preferred to LFRQA's answers, demonstrating RAG-QA Arena as a challenging evaluation platform for future research.
ACCENT: An Automatic Event Commonsense Evaluation Metric for Open-Domain Dialogue Systems
May 12, 2023



Commonsense reasoning is omnipresent in human communications and thus is an important feature for open-domain dialogue systems. However, evaluating commonsense in dialogue systems is still an open challenge. We take the first step by focusing on event commonsense that considers events and their relations, and is crucial in both dialogues and general commonsense reasoning. We propose ACCENT, an event commonsense evaluation metric empowered by commonsense knowledge bases (CSKBs). ACCENT first extracts event-relation tuples from a dialogue, and then evaluates the response by scoring the tuples in terms of their compatibility with the CSKB. To evaluate ACCENT, we construct the first public event commonsense evaluation dataset for open-domain dialogues. Our experiments show that ACCENT is an efficient metric for event commonsense evaluation, which achieves higher correlations with human judgments than existing baselines.
Character-Centric Story Visualization via Visual Planning and Token Alignment
Oct 20, 2022
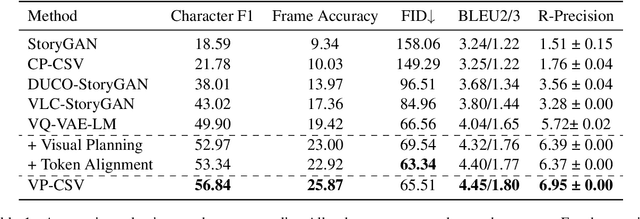
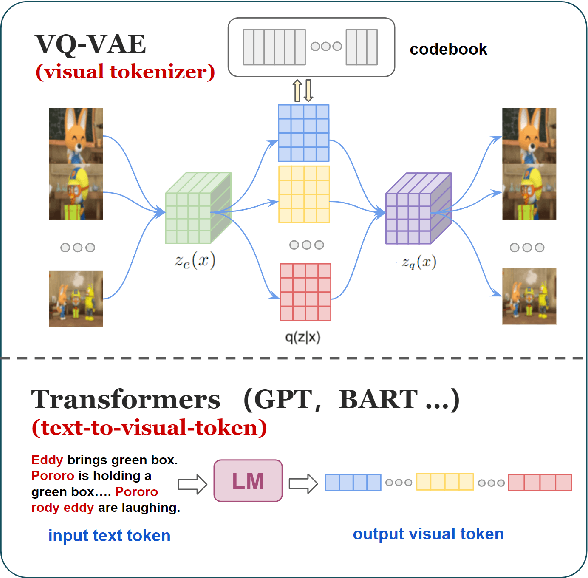
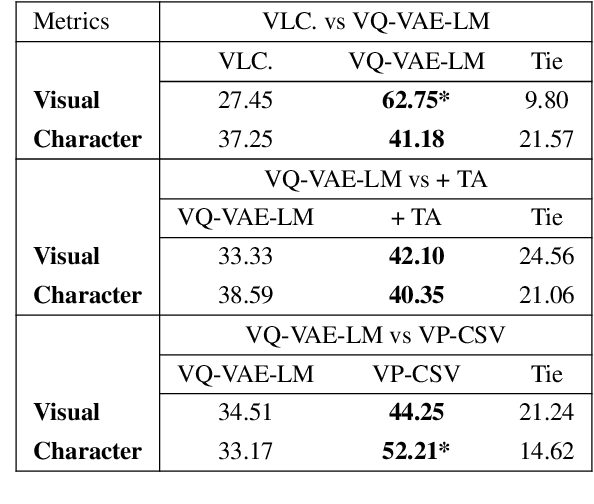
Story visualization advances the traditional text-to-image generation by enabling multiple image generation based on a complete story. This task requires machines to 1) understand long text inputs and 2) produce a globally consistent image sequence that illustrates the contents of the story. A key challenge of consistent story visualization is to preserve characters that are essential in stories. To tackle the challenge, we propose to adapt a recent work that augments Vector-Quantized Variational Autoencoders (VQ-VAE) with a text-tovisual-token (transformer) architecture. Specifically, we modify the text-to-visual-token module with a two-stage framework: 1) character token planning model that predicts the visual tokens for characters only; 2) visual token completion model that generates the remaining visual token sequence, which is sent to VQ-VAE for finalizing image generations. To encourage characters to appear in the images, we further train the two-stage framework with a character-token alignment objective. Extensive experiments and evaluations demonstrate that the proposed method excels at preserving characters and can produce higher quality image sequences compared with the strong baselines. Codes can be found in https://github.com/sairin1202/VP-CSV
Go Back in Time: Generating Flashbacks in Stories with Event Temporal Prompts
May 04, 2022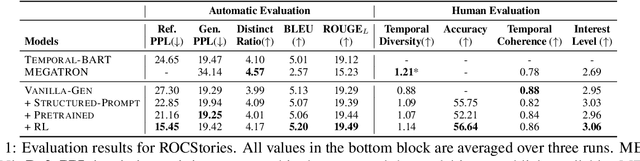
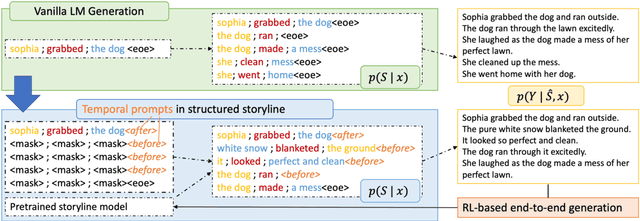

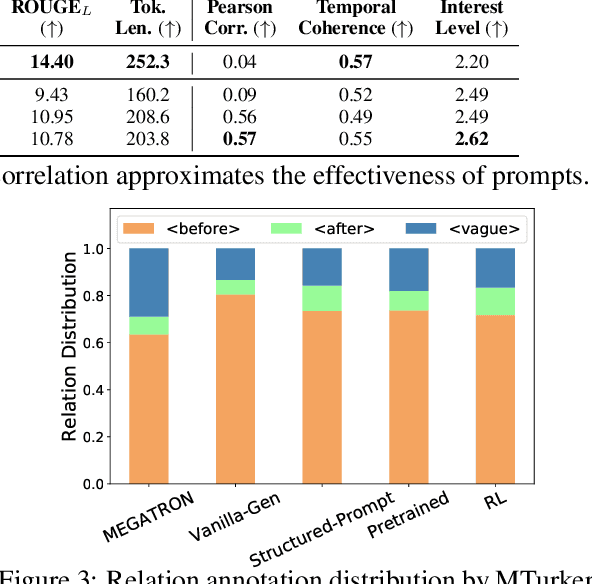
Stories or narratives are comprised of a sequence of events. To compose interesting stories, professional writers often leverage a creative writing technique called flashback that inserts past events into current storylines as we commonly observe in novels and plays. However, it is challenging for machines to generate flashback as it requires a solid understanding of event temporal order (e.g. "feeling hungry" before "eat," not vice versa), and the creativity to arrange storylines so that earlier events do not always appear first in narrative order. Two major issues in existing systems that exacerbate the challenges: 1) temporal bias in pertaining and story datasets that leads to monotonic event temporal orders; 2) lack of explicit guidance that helps machines decide where to insert flashbacks. We propose to address these issues using structured storylines to encode events and their pair-wise temporal relations (before, after and vague) as temporal prompts that guide how stories should unfold temporally. We leverage a Plan-and-Write framework enhanced by reinforcement learning to generate storylines and stories end-to-end. Evaluation results show that the proposed method can generate more interesting stories with flashbacks while maintaining textual diversity, fluency, and temporal coherence.