 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting with Generated Data: Annotation-Free LLM Skill Estimation and Expert Selection
Jan 14, 2026Large Language Model (LLM) routers dynamically select optimal models for given inputs. Existing approaches typically assume access to ground-truth labeled data, which is often unavailable in practice, especially when user request distributions are heterogeneous and unknown. We introduce Routing with Generated Data (RGD), a challenging setting in which routers are trained exclusively on generated queries and answers produced from high-level task descriptions by generator LLMs. We evaluate query-answer routers (using both queries and labels) and query-only routers across four diverse benchmarks and 12 models, finding that query-answer routers degrade faster than query-only routers as generator quality decreases. Our analysis reveals two crucial characteristics of effective generators: they must accurately respond to their own questions, and their questions must produce sufficient performance differentiation among the model pool. We then show how filtering for these characteristics can improve the quality of generated data. We further propose CASCAL, a novel query-only router that estimates model correctness through consensus voting and identifies model-specific skill niches via hierarchical clustering. CASCAL is substantially more robust to generator quality, outperforming the best query-answer router by 4.6% absolute accuracy when trained on weak generator data.
Think Right: Learning to Mitigate Under-Over Thinking via Adaptive, Attentive Compression
Oct 02, 2025Recent thinking models solve complex reasoning tasks by scaling test-time compute, but this scaling must be allocated in line with task difficulty. On one hand, short reasoning (underthinking) leads to errors on harder problems that require extended reasoning steps; but, excessively long reasoning (overthinking) can be token-inefficient, generating unnecessary steps even after reaching a correct intermediate solution. We refer to this as under-adaptivity, where the model fails to modulate its response length appropriately given problems of varying difficulty. To address under-adaptivity and strike a balance between under- and overthinking, we propose TRAAC (Think Right with Adaptive, Attentive Compression), an online post-training RL method that leverages the model's self-attention over a long reasoning trajectory to identify important steps and prune redundant ones. TRAAC also estimates difficulty and incorporates it into training rewards, thereby learning to allocate reasoning budget commensurate with example difficulty. Our approach improves accuracy, reduces reasoning steps, and enables adaptive thinking compared to base models and other RL baselines. Across a variety of tasks (AIME, AMC, GPQA-D, BBEH), TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4% with a relative reduction in reasoning length of 36.8% compared to the base model, and a 7.9% accuracy gain paired with a 29.4% length drop compared to the best RL baseline. TRAAC also shows strong generalization: although our models are trained on math datasets, they show accuracy and efficiency gains on out-of-distribution non-math datasets like GPQA-D, BBEH, and OptimalThinkingBench. Our analysis further verifies that TRAAC provides fine-grained adjustments to thinking budget based on difficulty and that a combination of task-difficulty calibration and attention-based compression yields gains across diverse tasks.
MAMM-Refine: A Recipe for Improving Faithfulness in Generation with Multi-Agent Collaboration
Mar 19, 2025Multi-agent collaboration among models has shown promise in reasoning tasks but is underexplored in long-form generation tasks like summarization and question-answering. We extend multi-agent multi-model reasoning to generation, specifically to improving faithfulness through refinement, i.e., revising model-generated outputs to remove factual inconsistencies. We investigate how iterative collaboration among multiple instances and types of large language models (LLMs) enhances subtasks in the refinement process, such as error detection, critiquing unfaithful sentences, and making corrections based on critiques. We design intrinsic evaluations for each subtask, with our findings indicating that both multi-agent (multiple instances) and multi-model (diverse LLM types) approaches benefit error detection and critiquing. Additionally, reframing critiquing and refinement as reranking rather than generation tasks improves multi-agent performance. We consolidate these insights into a final "recipe" called Multi-Agent Multi-Model Refinement (MAMM-Refine), where multi-agent and multi-model collaboration significantly boosts performance on three summarization datasets as well as on long-form question answering, demonstrating the effectiveness and generalizability of our recipe.
Symbolic Mixture-of-Experts: Adaptive Skill-based Routing for Heterogeneous Reasoning
Mar 07, 2025



Combining existing pre-trained expert LLMs is a promising avenue for scalably tackling large-scale and diverse tasks. However, selecting experts at the task level is often too coarse-grained, as heterogeneous tasks may require different expertise for each instance. To enable adaptive instance-level mixing of pre-trained LLM experts, we propose Symbolic-MoE, a symbolic, text-based, and gradient-free Mixture-of-Experts framework. Symbolic-MoE takes a fine-grained approach to selection by emphasizing skills, e.g., algebra in math or molecular biology in biomedical reasoning. We propose a skill-based recruiting strategy that dynamically selects the most relevant set of expert LLMs for diverse reasoning tasks based on their strengths. Each selected expert then generates its own reasoning, resulting in k outputs from k experts, which are then synthesized into a final high-quality response by an aggregator chosen based on its ability to integrate diverse reasoning outputs. We show that Symbolic-MoE's instance-level expert selection improves performance by a large margin but -- when implemented naively -- can introduce a high computational overhead due to the need for constant model loading and offloading. To address this, we implement a batch inference strategy that groups instances based on their assigned experts, loading each model only once. This allows us to integrate 16 expert models on 1 GPU with a time cost comparable to or better than prior multi-agent baselines using 4 GPUs. Through extensive evaluations on diverse benchmarks (MMLU-Pro, GPQA, AIME, and MedMCQA), we demonstrate that Symbolic-MoE outperforms strong LLMs like GPT4o-mini, as well as multi-agent approaches, with an absolute average improvement of 8.15% over the best multi-agent baseline. Moreover, Symbolic-MoE removes the need for expensive multi-round discussions, outperforming discussion baselines with less computation.
Learning to Generate Unit Tests for Automated Debugging
Feb 03, 2025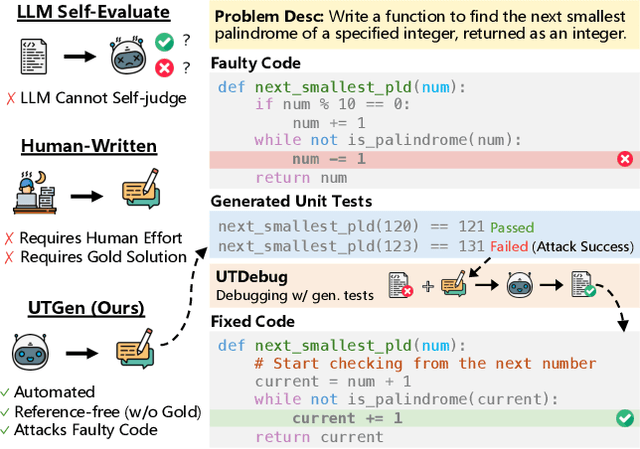

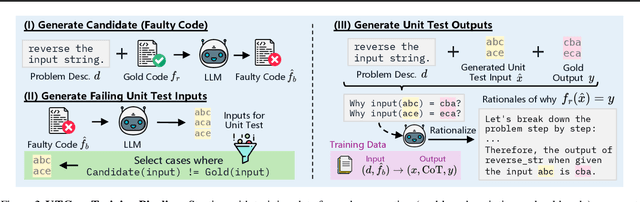

Unit tests (UTs) play an instrumental role in assessing code correctness as well as providing feedback to a large language model (LLM) as it iteratively debugs faulty code, motivating automated test generation. However, we uncover a trade-off between generating unit test inputs that reveal errors when given a faulty code and correctly predicting the unit test output without access to the gold solution. To address this trade-off, we propose UTGen, which teaches LLMs to generate unit test inputs that reveal errors along with their correct expected outputs based on task descriptions and candidate code. We integrate UTGen into UTDebug, a robust debugging pipeline that uses generated tests to help LLMs debug effectively. Since model-generated tests can provide noisy signals (e.g., from incorrectly predicted outputs), UTDebug (i) scales UTGen via test-time compute to improve UT output prediction, and (ii) validates and back-tracks edits based on multiple generated UTs to avoid overfitting. We show that UTGen outperforms UT generation baselines by 7.59% based on a metric measuring the presence of both error-revealing UT inputs and correct UT outputs. When used with UTDebug, we find that feedback from UTGen's unit tests improves pass@1 accuracy of Qwen-2.5 7B on HumanEvalFix and our own harder debugging split of MBPP+ by over 3% and 12.35% (respectively) over other LLM-based UT generation baselines.
Reverse Thinking Makes LLMs Stronger Reasoners
Nov 29, 2024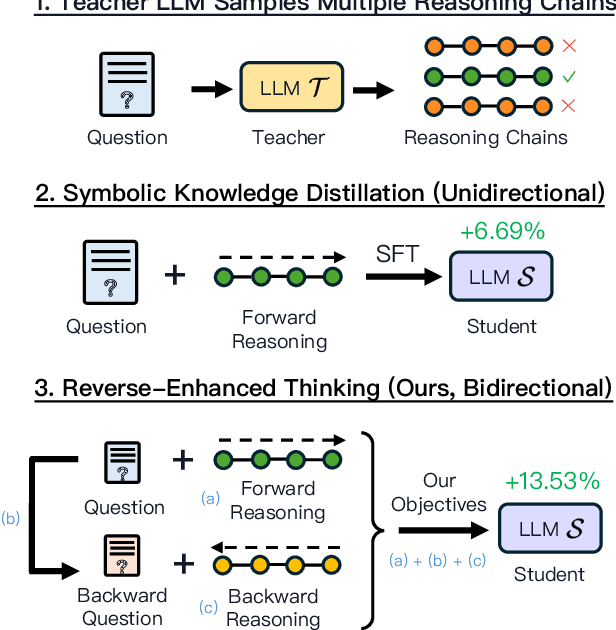
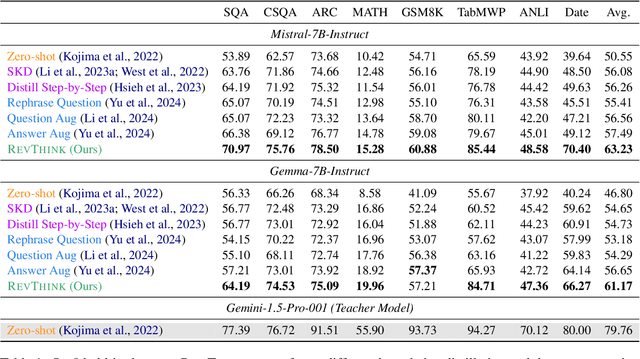
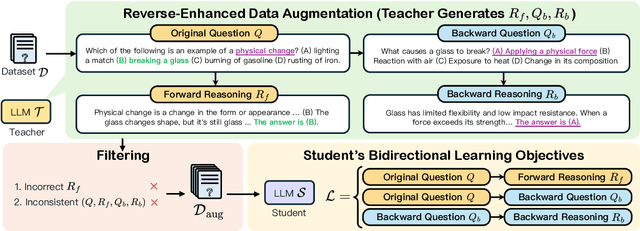
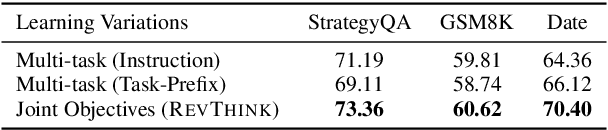
Reverse thinking plays a crucial role in human reasoning. Humans can reason not only from a problem to a solution but also in reverse, i.e., start from the solution and reason towards the problem. This often enhances overall reasoning performance as it enables consistency checks between their forward and backward thinking. To enable Large Language Models (LLMs) to perform reverse thinking, we introduce Reverse-Enhanced Thinking (RevThink), a framework composed of data augmentation and learning objectives. In RevThink, we augment the dataset by collecting structured forward-backward reasoning from a teacher model, consisting of: (1) the original question, (2) forward reasoning, (3) backward question, and (4) backward reasoning. We then employ three objectives to train a smaller student model in a multi-task learning fashion: (a) generate forward reasoning from a question, (b) generate a backward question from a question, and (c) generate backward reasoning from the backward question. Experiments across 12 datasets covering commonsense, math, and logical reasoning show an average 13.53% improvement over the student model's zero-shot performance and a 6.84% improvement over the strongest knowledge distillation baselines. Moreover, our method demonstrates sample efficiency -- using only 10% of the correct forward reasoning from the training data, it outperforms a standard fine-tuning method trained on 10x more forward reasoning. RevThink also exhibits strong generalization to out-of-distribution held-out datasets.
MAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning
Sep 18, 2024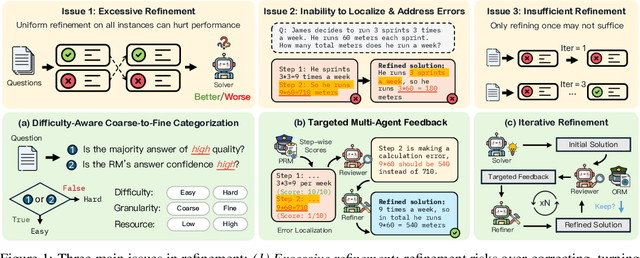
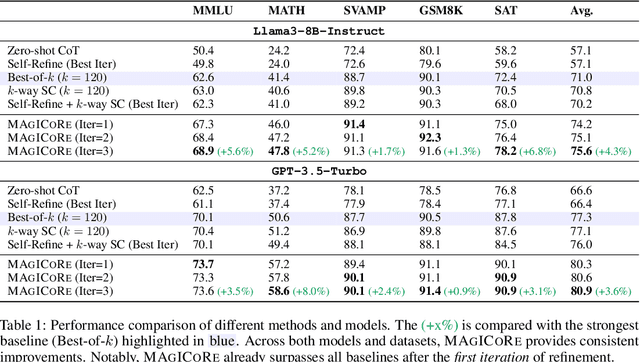
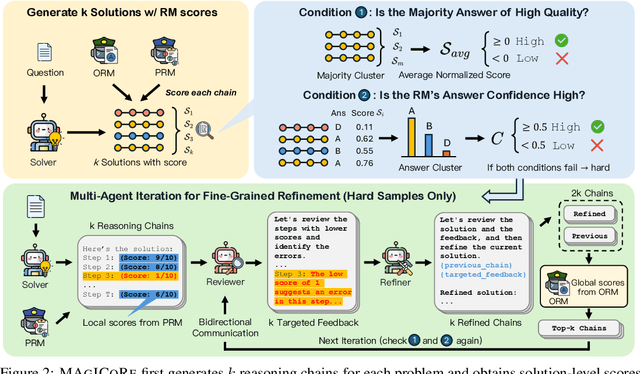
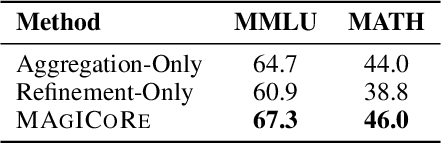
Large Language Models' (LLM) reasoning can be improved using test-time aggregation strategies, i.e., generating multiple samples and voting among generated samples. While these improve performance, they often reach a saturation point. Refinement offers an alternative by using LLM-generated feedback to improve solution quality. However, refinement introduces 3 key challenges: (1) Excessive refinement: Uniformly refining all instances can over-correct and reduce the overall performance. (2) Inability to localize and address errors: LLMs have a limited ability to self-correct and struggle to identify and correct their own mistakes. (3) Insufficient refinement: Deciding how many iterations of refinement are needed is non-trivial, and stopping too soon could leave errors unaddressed. To tackle these issues, we propose MAgICoRe, which avoids excessive refinement by categorizing problem difficulty as easy or hard, solving easy problems with coarse-grained aggregation and hard ones with fine-grained and iterative multi-agent refinement. To improve error localization, we incorporate external step-wise reward model (RM) scores. Moreover, to ensure effective refinement, we employ a multi-agent loop with three agents: Solver, Reviewer (which generates targeted feedback based on step-wise RM scores), and the Refiner (which incorporates feedback). To ensure sufficient refinement, we re-evaluate updated solutions, iteratively initiating further rounds of refinement. We evaluate MAgICoRe on Llama-3-8B and GPT-3.5 and show its effectiveness across 5 math datasets. Even one iteration of MAgICoRe beats Self-Consistency by 3.4%, Best-of-k by 3.2%, and Self-Refine by 4.0% while using less than half the samples. Unlike iterative refinement with baselines, MAgICoRe continues to improve with more iterations. Finally, our ablations highlight the importance of MAgICoRe's RMs and multi-agent communication.
System-1.x: Learning to Balance Fast and Slow Planning with Language Models
Jul 19, 2024

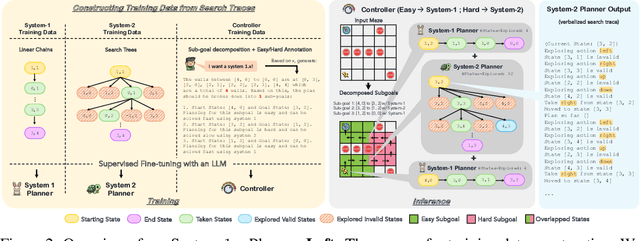

Language models can be used to solve long-horizon planning problems in two distinct modes: a fast 'System-1' mode, directly generating plans without any explicit search or backtracking, and a slow 'System-2' mode, planning step-by-step by explicitly searching over possible actions. While System-2 is typically more effective, it is also more computationally expensive, making it infeasible for long plans or large action spaces. Moreover, isolated System-1 or 2 ignores the user's end goals, failing to provide ways to control the model's behavior. To this end, we propose the System-1.x Planner, a controllable planning framework with LLMs that is capable of generating hybrid plans and balancing between the two planning modes based on the difficulty of the problem at hand. System-1.x consists of (i) a controller, (ii) a System-1 Planner, and (iii) a System-2 Planner. Based on a user-specified hybridization factor (x) governing the mixture between System-1 and 2, the controller decomposes a problem into sub-goals, and classifies them as easy or hard to be solved by either System-1 or 2, respectively. We fine-tune all three components on top of a single base LLM, requiring only search traces as supervision. Experiments with two diverse planning tasks -- Maze Navigation and Blocksworld -- show that our System-1.x Planner outperforms a System-1 Planner, a System-2 Planner trained to approximate A* search, and also a symbolic planner (A*). We demonstrate the following key properties of our planner: (1) controllability: increasing the hybridization factor (e.g., System-1.75 vs 1.5) performs more search, improving performance, (2) flexibility: by building a neuro-symbolic variant with a neural System-1 and a symbolic System-2, we can use existing symbolic methods, and (3) generalizability: by being able to learn from different search algorithms, our method is robust to the choice of search algorithm.
MAGDi: Structured Distillation of Multi-Agent Interaction Graphs Improves Reasoning in Smaller Language Models
Feb 02, 2024Multi-agent interactions between Large Language Model (LLM) agents have shown major improvements on diverse reasoning tasks. However, these involve long generations from multiple models across several rounds, making them expensive. Moreover, these multi-agent approaches fail to provide a final, single model for efficient inference. To address this, we introduce MAGDi, a new method for structured distillation of the reasoning interactions between multiple LLMs into smaller LMs. MAGDi teaches smaller models by representing multi-agent interactions as graphs, augmenting a base student model with a graph encoder, and distilling knowledge using three objective functions: next-token prediction, a contrastive loss between correct and incorrect reasoning, and a graph-based objective to model the interaction structure. Experiments on seven widely-used commonsense and math reasoning benchmarks show that MAGDi improves the reasoning capabilities of smaller models, outperforming several methods that distill from a single teacher and multiple teachers. Moreover, MAGDi also demonstrates an order of magnitude higher efficiency over its teachers. We conduct extensive analyses to show that MAGDi (1) enhances the generalizability to out-of-domain tasks, (2) scales positively with the size and strength of the base student model, and (3) obtains larger improvements (via our multi-teacher training) when applying self-consistency - an inference technique that relies on model diversity.
Location-Aware Visual Question Generation with Lightweight Models
Oct 23, 2023



This work introduces a novel task, location-aware visual question generation (LocaVQG), which aims to generate engaging questions from data relevant to a particular geographical location. Specifically, we represent such location-aware information with surrounding images and a GPS coordinate. To tackle this task, we present a dataset generation pipeline that leverages GPT-4 to produce diverse and sophisticated questions. Then, we aim to learn a lightweight model that can address the LocaVQG task and fit on an edge device, such as a mobile phone. To this end, we propose a method which can reliably generate engaging questions from location-aware information. Our proposed method outperforms baselines regarding human evaluation (e.g., engagement, grounding, coherence) and automatic evaluation metrics (e.g., BERTScore, ROUGE-2). Moreover, we conduct extensive ablation studies to justify our proposed techniques for both generating the dataset and solving the task.