 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPixie: Unified and Probabilistic 3D Physics Learning via Flow Matching
Jun 03, 2026Existing feed-forward networks excel at predicting a single set of physical properties from visual appearance, but this point-estimate paradigm fundamentally fails to capture the real world's inherent physical ambiguity. We address this by reframing physics prediction as a task of learning a controllable, continuous distribution of material properties. We introduce UNIPIXIE, a framework trained to predict a continuous and parameterized path of physically plausible material properties from a single visual input. By learning a direct mapping along an object's softest-to-stiffest spectrum on our PIXIEMULTIVERSE dataset, UNIPIXIE allows for controllable generation of diverse, physically valid material fields via a single intuitive parameter. Crucially, UNIPIXIE introduces a novel unified architecture to produce simulation-ready parameters for diverse physics solvers, including continuum-based Material Point Method (MPM), reduced-order deformation based on Linear Blend Skinning (LBS), and anchor-based Spring-Mass systems, addressing a key portability issue in prior work. Experiments show our approach not only generates a rich variety of plausible dynamics but also reduces Young's Modulus prediction error by over 50% against the strongest deterministic baseline, bridging the gap between static point estimates and the continuous nature of physical reality. Project page: https://unipixie.github.io/
OmniGuide: Universal Guidance Fields for Enhancing Generalist Robot Policies
Mar 09, 2026Vision-language-action(VLA) models have shown great promise as generalist policies for a large range of relatively simple tasks. However, they demonstrate limited performance on more complex tasks, such as those requiring complex spatial or semantic understanding, manipulation in clutter, or precise manipulation. We propose OMNIGUIDE, a flexible framework that improves VLA performance on such tasks by leveraging arbitrary sources of guidance, such as 3D foundation models, semantic-reasoning VLMs, and human pose models. We show how many kinds of guidance can be naturally expressed as differentiable energy functions with task-specific attractors and repellers located in 3D space, that influence the sampling of VLA actions. In this way, OMNIGUIDE enables guidance sources with complementary task-relevant strengths to improve a VLA model's performance on challenging tasks. Extensive experiments in both simulation and real-world environments, across diverse sources of guidance, demonstrate that OMNIGUIDE enhances the performance of state-of-the-art generalist policies (e.g., $π_{0.5}$, GR00T N1.6) significantly across success and safety rates. Critically, our unified framework matches or surpasses the performance of prior methods designed to incorporate specific sources of guidance into VLA policies. Project Page: $\href{https://omniguide.github.io/}{this \; url}$
PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving
Feb 22, 2025Recent agent frameworks and inference-time algorithms often struggle with complex planning problems due to limitations in verifying generated plans or reasoning and varying complexity of instances within a single task. Many existing methods for these tasks either perform task-level verification without considering constraints or apply inference-time algorithms without adapting to instance-level complexity. To address these limitations, we propose PlanGEN, a model-agnostic and easily scalable agent framework with three key components: constraint, verification, and selection agents. Specifically, our approach proposes constraint-guided iterative verification to enhance performance of inference-time algorithms--Best of N, Tree-of-Thought, and REBASE. In PlanGEN framework, the selection agent optimizes algorithm choice based on instance complexity, ensuring better adaptability to complex planning problems. Experimental results demonstrate significant improvements over the strongest baseline across multiple benchmarks, achieving state-of-the-art results on NATURAL PLAN ($\sim$8%$\uparrow$), OlympiadBench ($\sim$4%$\uparrow$), DocFinQA ($\sim$7%$\uparrow$), and GPQA ($\sim$1%$\uparrow$). Our key finding highlights that constraint-guided iterative verification improves inference-time algorithms, and adaptive selection further boosts performance on complex planning and reasoning problems.
Reverse Thinking Makes LLMs Stronger Reasoners
Nov 29, 2024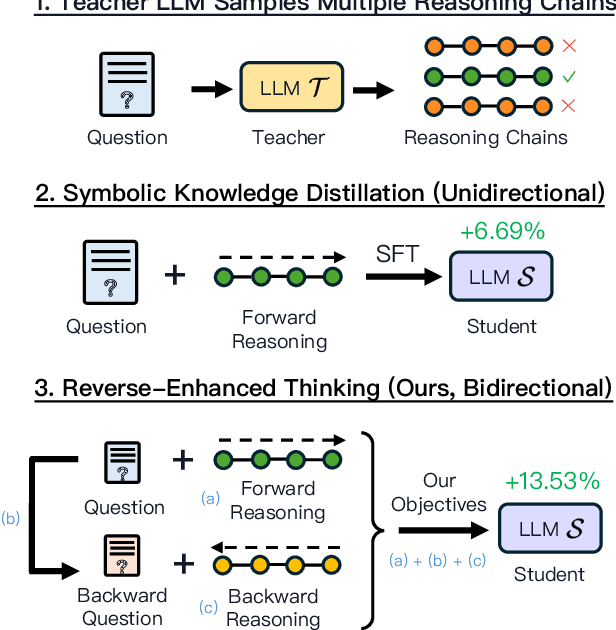
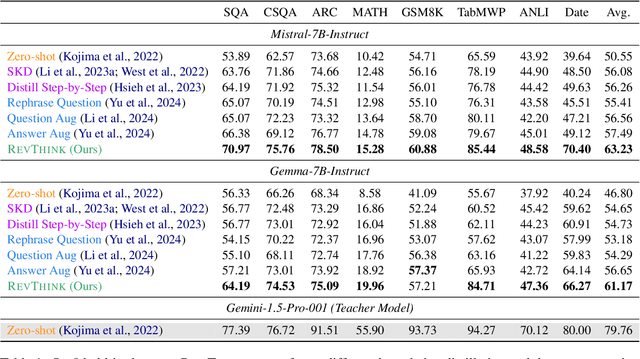
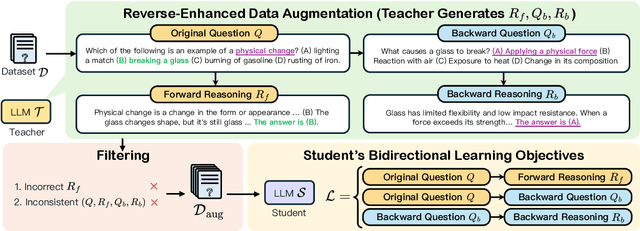
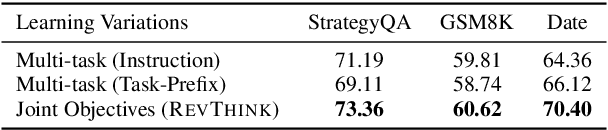
Reverse thinking plays a crucial role in human reasoning. Humans can reason not only from a problem to a solution but also in reverse, i.e., start from the solution and reason towards the problem. This often enhances overall reasoning performance as it enables consistency checks between their forward and backward thinking. To enable Large Language Models (LLMs) to perform reverse thinking, we introduce Reverse-Enhanced Thinking (RevThink), a framework composed of data augmentation and learning objectives. In RevThink, we augment the dataset by collecting structured forward-backward reasoning from a teacher model, consisting of: (1) the original question, (2) forward reasoning, (3) backward question, and (4) backward reasoning. We then employ three objectives to train a smaller student model in a multi-task learning fashion: (a) generate forward reasoning from a question, (b) generate a backward question from a question, and (c) generate backward reasoning from the backward question. Experiments across 12 datasets covering commonsense, math, and logical reasoning show an average 13.53% improvement over the student model's zero-shot performance and a 6.84% improvement over the strongest knowledge distillation baselines. Moreover, our method demonstrates sample efficiency -- using only 10% of the correct forward reasoning from the training data, it outperforms a standard fine-tuning method trained on 10x more forward reasoning. RevThink also exhibits strong generalization to out-of-distribution held-out datasets.
Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
Jul 11, 2024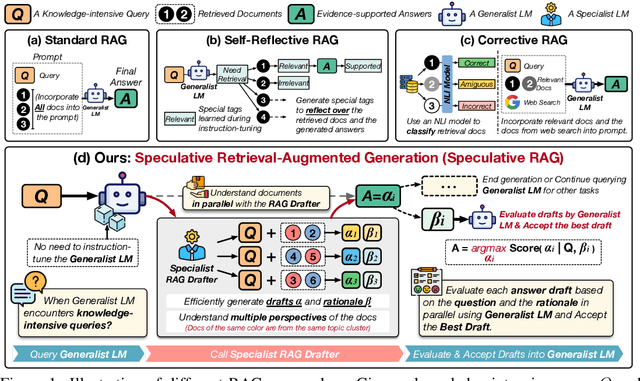
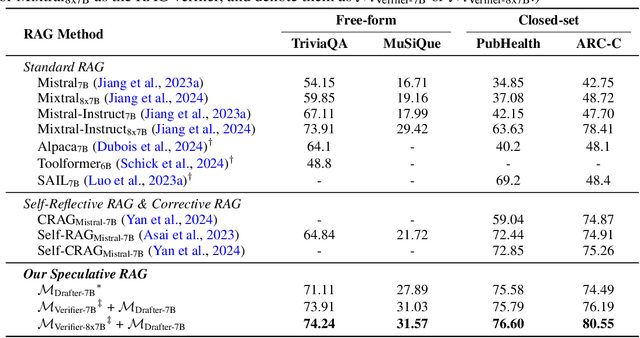
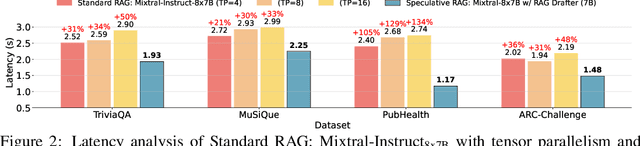
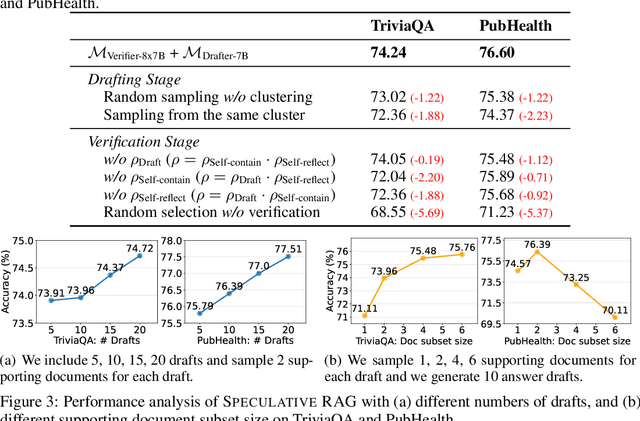
Retrieval augmented generation (RAG) combines the generative abilities of large language models (LLMs) with external knowledge sources to provide more accurate and up-to-date responses. Recent RAG advancements focus on improving retrieval outcomes through iterative LLM refinement or self-critique capabilities acquired through additional instruction tuning of LLMs. In this work, we introduce Speculative RAG - a framework that leverages a larger generalist LM to efficiently verify multiple RAG drafts produced in parallel by a smaller, distilled specialist LM. Each draft is generated from a distinct subset of retrieved documents, offering diverse perspectives on the evidence while reducing input token counts per draft. This approach enhances comprehension of each subset and mitigates potential position bias over long context. Our method accelerates RAG by delegating drafting to the smaller specialist LM, with the larger generalist LM performing a single verification pass over the drafts. Extensive experiments demonstrate that Speculative RAG achieves state-of-the-art performance with reduced latency on TriviaQA, MuSiQue, PubHealth, and ARC-Challenge benchmarks. It notably enhances accuracy by up to 12.97% while reducing latency by 51% compared to conventional RAG systems on PubHealth.
Distributed Continual Learning
May 23, 2024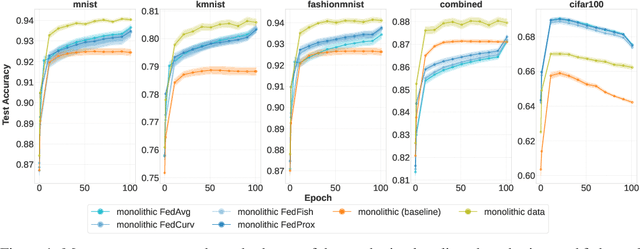
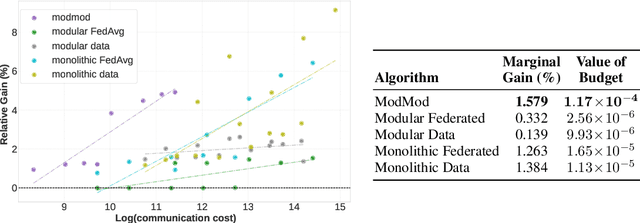
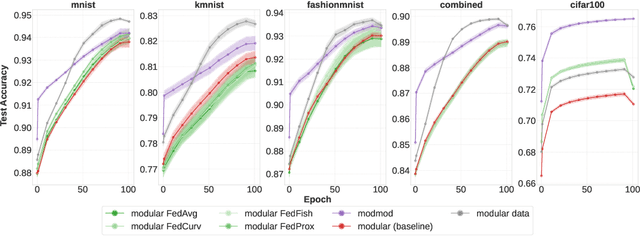

This work studies the intersection of continual and federated learning, in which independent agents face unique tasks in their environments and incrementally develop and share knowledge. We introduce a mathematical framework capturing the essential aspects of distributed continual learning, including agent model and statistical heterogeneity, continual distribution shift, network topology, and communication constraints. Operating on the thesis that distributed continual learning enhances individual agent performance over single-agent learning, we identify three modes of information exchange: data instances, full model parameters, and modular (partial) model parameters. We develop algorithms for each sharing mode and conduct extensive empirical investigations across various datasets, topology structures, and communication limits. Our findings reveal three key insights: sharing parameters is more efficient than sharing data as tasks become more complex; modular parameter sharing yields the best performance while minimizing communication costs; and combining sharing modes can cumulatively improve performance.
Supervised Parameter Estimation of Neuron Populations from Multiple Firing Events
Oct 02, 2022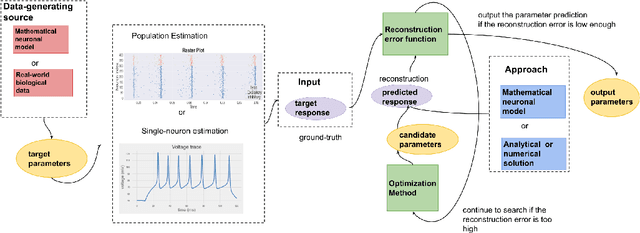
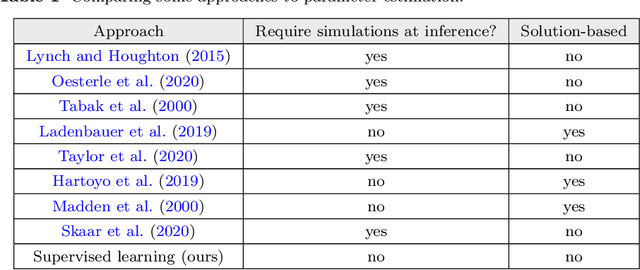
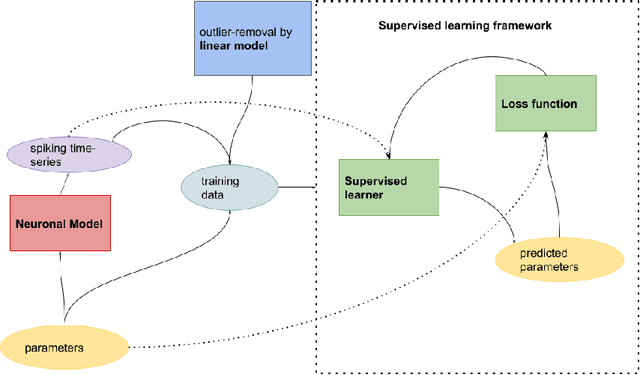
The firing dynamics of biological neurons in mathematical models is often determined by the model's parameters, representing the neurons' underlying properties. The parameter estimation problem seeks to recover those parameters of a single neuron or a neuron population from their responses to external stimuli and interactions between themselves. Most common methods for tackling this problem in the literature use some mechanistic models in conjunction with either a simulation-based or solution-based optimization scheme. In this paper, we study an automatic approach of learning the parameters of neuron populations from a training set consisting of pairs of spiking series and parameter labels via supervised learning. Unlike previous work, this automatic learning does not require additional simulations at inference time nor expert knowledge in deriving an analytical solution or in constructing some approximate models. We simulate many neuronal populations with different parameter settings using a stochastic neuron model. Using that data, we train a variety of supervised machine learning models, including convolutional and deep neural networks, random forest, and support vector regression. We then compare their performance against classical approaches including a genetic search, Bayesian sequential estimation, and a random walk approximate model. The supervised models almost always outperform the classical methods in parameter estimation and spike reconstruction errors, and computation expense. Convolutional neural network, in particular, is the best among all models across all metrics. The supervised models can also generalize to out-of-distribution data to a certain extent.