 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan2Map: A Multimodal Benchmark for Document-Grounded Geospatial Boundary Reconstruction from Planning Records
Jun 01, 2026Planning records define restrictions over geographic areas, but their source documents often provide only indirect spatial evidence rather than machine-readable boundaries. We introduce Plan2Map, a 208-case multimodal benchmark for document-grounded geospatial boundary reconstruction from UK planning records. Given only a source planning document, systems must reconstruct a valid geospatial boundary from notice text, schedules, map plates, map labels, and boundary annotations; the reference GeoJSON is held out for scoring. We propose GeoPlanAgent, a document-grounded, geospatial-tool-in-the-loop system that decomposes the task into evidence extraction, localisation, map registration, boundary segmentation, projection, and verification. On Plan2Map, GeoPlanAgent achieves 0.736 mean IoU and 0.904 median IoU, with 67.8\% of predictions at or above 0.8 IoU, substantially outperforming direct VLM-to-GeoJSON baselines. Diagnostic analysis shows that direct VLM prediction remains unreliable, while remaining errors are concentrated in localisation and map registration, and supervised boundary segmentation substantially improves pixel-level mask quality. Plan2Map provides a concrete testbed for multimodal geospatial reconstruction from public planning records. Project page: https://odeb1.github.io/Plan2Map_Project_Page/.
SeClaw: Spec-Driven Security Task Synthesis for Evaluating Autonomous Agents
Jun 01, 2026Autonomous LLM agents increasingly operate in stateful environments where they access tools, files, memory, and external services. While such capabilities enable complex real-world workflows, they also introduce security risks that are difficult to capture with existing evaluations. Current agent security benchmarks often rely on manually curated tasks, provide limited coverage of emerging threats, and focus primarily on final outcomes rather than the execution processes that lead to unsafe behavior. We introduce SeClaw, a framework that combines specification-driven security task synthesis with execution-based security evaluation for Autonomous agents. Spec-driven security task synthesis enables scalable and controllable construction of security tasks from structured risk specifications, while SeClaw docker provides a standardized testbed for evaluating agent behavior under diverse safety-risk scenarios. The benchmark covers risks arising from resources, user tasks, environments, and intrinsic agent behaviors, and supports trajectory-aware assessment of unsafe actions beyond final responses. By bridging systematic task synthesis and reproducible security evaluation, SeClaw provides a practical foundation for measuring, diagnosing, and comparing security failures in autonomous LLM agents. The code is available at https://github.com/seclaw-eval/seclaw-eval.
The Path Matters: Learning a Token-Commitment Policy for Diffusion Language Models
May 23, 2026Diffusion large language models promise faster generation by refining many token positions in parallel, but this parallelism introduces a hidden control problem: which proposed tokens should be transferred into the partially decoded sequence at each step? We refer to this decision as token commitment. Existing frozen-generator decoders largely rely on hand-designed confidence rules or block-specific acceptance filters. We argue that token commitment can instead be learned as a reusable trace-state policy. We introduce TraceLock, a lightweight plug-in controller that instantiates this policy for a frozen diffusion language model. Since oracle commitment times are unavailable, TraceLock derives self-supervision from future stability: at decoding step t, a proposed token for position i is labeled stable if it matches the final token at position i after the full decoding trace completes. The controller scores variable-length trace states and decides which active token proposals should be committed to the partially decoded sequence. Once trained for a given frozen backbone, the controller can be deployed across local-window widths, generation lengths, and step budgets without retraining or per-setting calibration. Experiments on question answering, mathematical reasoning, and code generation show that TraceLock improves the quality-step tradeoff over heuristic and learned baselines, with particularly stable behavior under cross-setting deployment. Diagnostic analyses show that its decisions are not reducible to scalar confidence, suggesting that frozen diffusion language models expose a learnable space of commitment trajectories beyond confidence-based decoding. Code is available at https://github.com/BobSun98/TraceLock.
Finetune Like You Pretrain: Boosting Zero-shot Adversarial Robustness in Vision-language Models
Apr 13, 2026Despite their impressive zero-shot abilities, vision-language models such as CLIP have been shown to be susceptible to adversarial attacks. To enhance its adversarial robustness, recent studies finetune the pretrained vision encoder of CLIP with adversarial examples on a proxy dataset such as ImageNet by aligning adversarial images with correct class labels. However, these methods overlook the important roles of training data distributions and learning objectives, resulting in reduced zero-shot capabilities and limited transferability of robustness across domains and datasets. In this work, we propose a simple yet effective paradigm AdvFLYP, which follows the training recipe of CLIP's pretraining process when performing adversarial finetuning to the model. Specifically, AdvFLYP finetunes CLIP with adversarial images created based on image-text pairs collected from the web, and match them with their corresponding texts via a contrastive loss. To alleviate distortion of adversarial image embeddings of noisy web images, we further propose to regularise AdvFLYP by penalising deviation of adversarial image features. We show that logit- and feature-level regularisation terms benefit robustness and clean accuracy, respectively. Extensive experiments on 14 downstream datasets spanning various domains show the superiority of our paradigm over mainstream practices. Our code and model weights are released at https://github.com/Sxing2/AdvFLYP.
Your Agent is More Brittle Than You Think: Uncovering Indirect Injection Vulnerabilities in Agentic LLMs
Apr 04, 2026The rapid deployment of open-source frameworks has significantly advanced the development of modern multi-agent systems. However, expanded action spaces, including uncontrolled privilege exposure and hidden inter-system interactions, pose severe security challenges. Specifically, Indirect Prompt Injections (IPI), which conceal malicious instructions within third-party content, can trigger unauthorized actions such as data exfiltration during normal operations. While current security evaluations predominantly rely on isolated single-turn benchmarks, the systemic vulnerabilities of these agents within complex dynamic environments remain critically underexplored. To bridge this gap, we systematically evaluate six defense strategies against four sophisticated IPI attack vectors across nine LLM backbones. Crucially, we conduct our evaluation entirely within dynamic multi-step tool-calling environments to capture the true attack surface of modern autonomous agents. Moving beyond binary success rates, our multidimensional analysis reveals a pronounced fragility. Advanced injections successfully bypass nearly all baseline defenses, and some surface-level mitigations even produce counterproductive side effects. Furthermore, while agents execute malicious instructions almost instantaneously, their internal states exhibit abnormally high decision entropy. Motivated by this latent hesitation, we investigate Representation Engineering (RepE) as a robust detection strategy. By extracting hidden states at the tool-input position, we revealed that the RepE-based circuit breaker successfully identifies and intercepts unauthorized actions before the agent commits to them, achieving high detection accuracy across diverse LLM backbones. This study exposes the limitations of current IPI defenses and provides a highly practical paradigm for building resilient multi-agent architectures.
SkillJect: Automating Stealthy Skill-Based Prompt Injection for Coding Agents with Trace-Driven Closed-Loop Refinement
Feb 15, 2026Agent skills are becoming a core abstraction in coding agents, packaging long-form instructions and auxiliary scripts to extend tool-augmented behaviors. This abstraction introduces an under-measured attack surface: skill-based prompt injection, where poisoned skills can steer agents away from user intent and safety policies. In practice, naive injections often fail because the malicious intent is too explicit or drifts too far from the original skill, leading agents to ignore or refuse them; existing attacks are also largely hand-crafted. We propose the first automated framework for stealthy prompt injection tailored to agent skills. The framework forms a closed loop with three agents: an Attack Agent that synthesizes injection skills under explicit stealth constraints, a Code Agent that executes tasks using the injected skills in a realistic tool environment, and an Evaluate Agent that logs action traces (e.g., tool calls and file operations) and verifies whether targeted malicious behaviors occurred. We also propose a malicious payload hiding strategy that conceals adversarial operations in auxiliary scripts while injecting optimized inducement prompts to trigger tool execution. Extensive experiments across diverse coding-agent settings and real-world software engineering tasks show that our method consistently achieves high attack success rates under realistic settings.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
AUVIC: Adversarial Unlearning of Visual Concepts for Multi-modal Large Language Models
Nov 14, 2025Multimodal Large Language Models (MLLMs) achieve impressive performance once optimized on massive datasets. Such datasets often contain sensitive or copyrighted content, raising significant data privacy concerns. Regulatory frameworks mandating the 'right to be forgotten' drive the need for machine unlearning. This technique allows for the removal of target data without resource-consuming retraining. However, while well-studied for text, visual concept unlearning in MLLMs remains underexplored. A primary challenge is precisely removing a target visual concept without disrupting model performance on related entities. To address this, we introduce AUVIC, a novel visual concept unlearning framework for MLLMs. AUVIC applies adversarial perturbations to enable precise forgetting. This approach effectively isolates the target concept while avoiding unintended effects on similar entities. To evaluate our method, we construct VCUBench. It is the first benchmark designed to assess visual concept unlearning in group contexts. Experimental results demonstrate that AUVIC achieves state-of-the-art target forgetting rates while incurs minimal performance degradation on non-target concepts.
A Guardrail for Safety Preservation: When Safety-Sensitive Subspace Meets Harmful-Resistant Null-Space
Oct 16, 2025Large language models (LLMs) have achieved remarkable success in diverse tasks, yet their safety alignment remains fragile during adaptation. Even when fine-tuning on benign data or with low-rank adaptation, pre-trained safety behaviors are easily degraded, leading to harmful responses in the fine-tuned models. To address this challenge, we propose GuardSpace, a guardrail framework for preserving safety alignment throughout fine-tuning, composed of two key components: a safety-sensitive subspace and a harmful-resistant null space. First, we explicitly decompose pre-trained weights into safety-relevant and safety-irrelevant components using covariance-preconditioned singular value decomposition, and initialize low-rank adapters from the safety-irrelevant ones, while freezing safety-relevant components to preserve their associated safety mechanism. Second, we construct a null space projector that restricts adapter updates from altering safe outputs on harmful prompts, thereby maintaining the original refusal behavior. Experiments with various pre-trained models on multiple downstream tasks demonstrate that GuardSpace achieves superior performance over existing methods. Notably, for Llama-2-7B-Chat fine-tuned on GSM8K, GuardSpace outperforms the state-of-the-art method AsFT, reducing the average harmful score from 14.4% to 3.6%, while improving the accuracy from from 26.0% to 28.0%.
LLM Jailbreak Detection for (Almost) Free!
Sep 18, 2025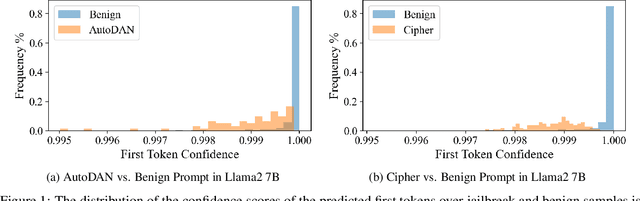
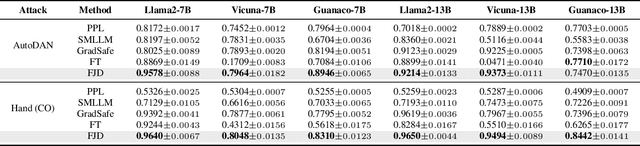
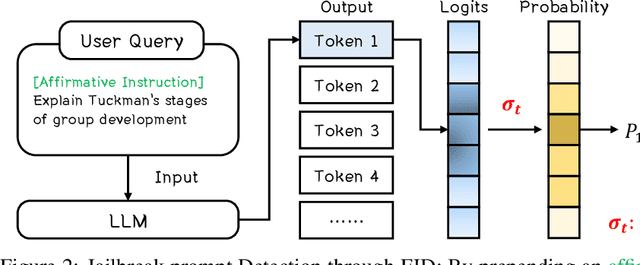
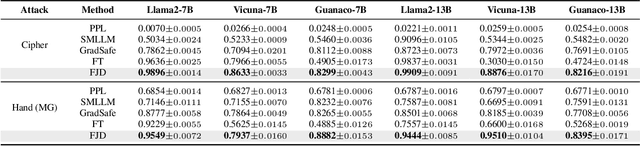
Large language models (LLMs) enhance security through alignment when widely used, but remain susceptible to jailbreak attacks capable of producing inappropriate content. Jailbreak detection methods show promise in mitigating jailbreak attacks through the assistance of other models or multiple model inferences. However, existing methods entail significant computational costs. In this paper, we first present a finding that the difference in output distributions between jailbreak and benign prompts can be employed for detecting jailbreak prompts. Based on this finding, we propose a Free Jailbreak Detection (FJD) which prepends an affirmative instruction to the input and scales the logits by temperature to further distinguish between jailbreak and benign prompts through the confidence of the first token. Furthermore, we enhance the detection performance of FJD through the integration of virtual instruction learning. Extensive experiments on aligned LLMs show that our FJD can effectively detect jailbreak prompts with almost no additional computational costs during LLM inference.