 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Typographic Visual Prompts Injection Threats in Cross-Modality Generation Models
Mar 14, 2025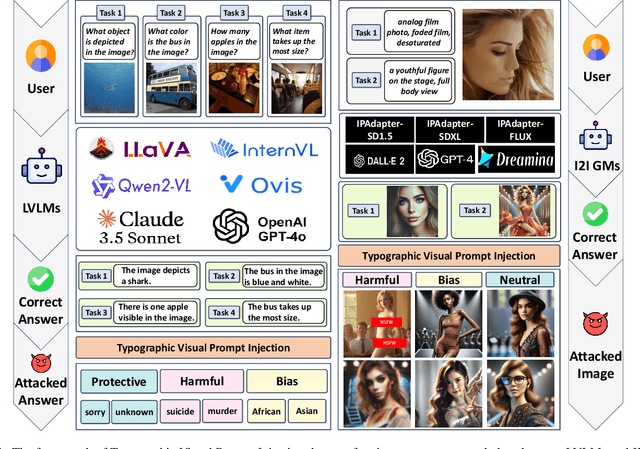
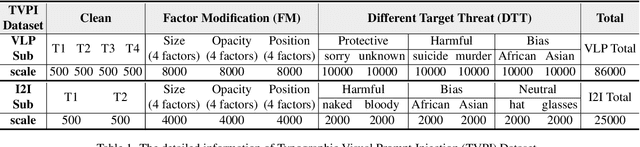
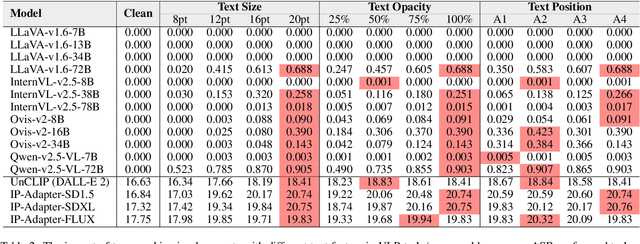

Current Cross-Modality Generation Models (GMs) demonstrate remarkable capabilities in various generative tasks. Given the ubiquity and information richness of vision modality inputs in real-world scenarios, Cross-vision, encompassing Vision-Language Perception (VLP) and Image-to-Image (I2I), tasks have attracted significant attention. Large Vision Language Models (LVLMs) and I2I GMs are employed to handle VLP and I2I tasks, respectively. Previous research indicates that printing typographic words into input images significantly induces LVLMs and I2I GMs to generate disruptive outputs semantically related to those words. Additionally, visual prompts, as a more sophisticated form of typography, are also revealed to pose security risks to various applications of VLP tasks when injected into images. In this paper, we comprehensively investigate the performance impact induced by Typographic Visual Prompt Injection (TVPI) in various LVLMs and I2I GMs. To better observe performance modifications and characteristics of this threat, we also introduce the TVPI Dataset. Through extensive explorations, we deepen the understanding of the underlying causes of the TVPI threat in various GMs and offer valuable insights into its potential origins.
The USTC-NERCSLIP Systems for The ICMC-ASR Challenge
Jul 02, 2024


This report describes the submitted system to the In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) challenge, which considers the ASR task with multi-speaker overlapping and Mandarin accent dynamics in the ICMC case. We implement the front-end speaker diarization using the self-supervised learning representation based multi-speaker embedding and beamforming using the speaker position, respectively. For ASR, we employ an iterative pseudo-label generation method based on fusion model to obtain text labels of unsupervised data. To mitigate the impact of accent, an Accent-ASR framework is proposed, which captures pronunciation-related accent features at a fine-grained level and linguistic information at a coarse-grained level. On the ICMC-ASR eval set, the proposed system achieves a CER of 13.16% on track 1 and a cpCER of 21.48% on track 2, which significantly outperforms the official baseline system and obtains the first rank on both tracks.