 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankLLM: Weighted Ranking of LLMs by Quantifying Question Difficulty
Feb 12, 2026Benchmarks establish a standardized evaluation framework to systematically assess the performance of large language models (LLMs), facilitating objective comparisons and driving advancements in the field. However, existing benchmarks fail to differentiate question difficulty, limiting their ability to effectively distinguish models' capabilities. To address this limitation, we propose RankLLM, a novel framework designed to quantify both question difficulty and model competency. RankLLM introduces difficulty as the primary criterion for differentiation, enabling a more fine-grained evaluation of LLM capabilities. RankLLM's core mechanism facilitates bidirectional score propagation between models and questions. The core intuition of RankLLM is that a model earns a competency score when it correctly answers a question, while a question's difficulty score increases when it challenges a model. Using this framework, we evaluate 30 models on 35,550 questions across multiple domains. RankLLM achieves 90% agreement with human judgments and consistently outperforms strong baselines such as IRT. It also exhibits strong stability, fast convergence, and high computational efficiency, making it a practical solution for large-scale, difficulty-aware LLM evaluation.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Beyond Redundancy: Diverse and Specialized Multi-Expert Sparse Autoencoder
Nov 07, 2025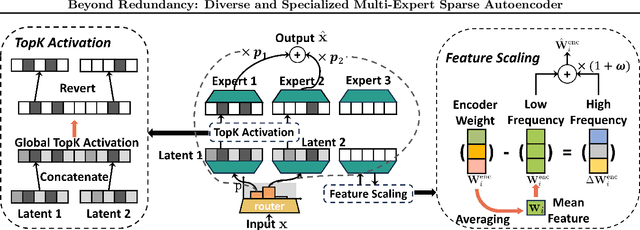
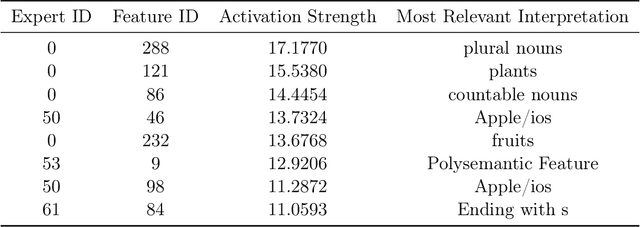
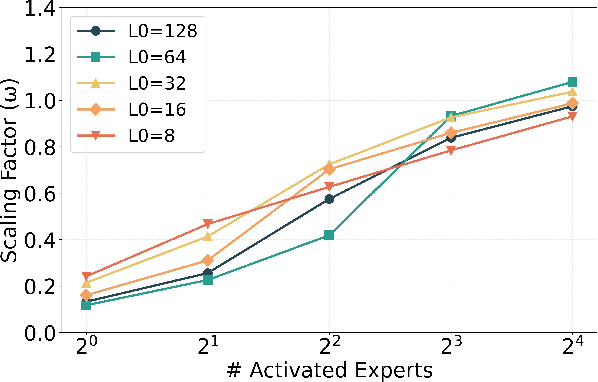
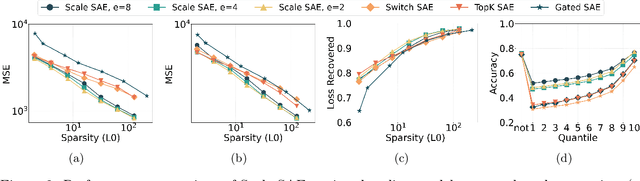
Sparse autoencoders (SAEs) have emerged as a powerful tool for interpreting large language models (LLMs) by decomposing token activations into combinations of human-understandable features. While SAEs provide crucial insights into LLM explanations, their practical adoption faces a fundamental challenge: better interpretability demands that SAEs' hidden layers have high dimensionality to satisfy sparsity constraints, resulting in prohibitive training and inference costs. Recent Mixture of Experts (MoE) approaches attempt to address this by partitioning SAEs into narrower expert networks with gated activation, thereby reducing computation. In a well-designed MoE, each expert should focus on learning a distinct set of features. However, we identify a \textit{critical limitation} in MoE-SAE: Experts often fail to specialize, which means they frequently learn overlapping or identical features. To deal with it, we propose two key innovations: (1) Multiple Expert Activation that simultaneously engages semantically weighted expert subsets to encourage specialization, and (2) Feature Scaling that enhances diversity through adaptive high-frequency scaling. Experiments demonstrate a 24\% lower reconstruction error and a 99\% reduction in feature redundancy compared to existing MoE-SAE methods. This work bridges the interpretability-efficiency gap in LLM analysis, allowing transparent model inspection without compromising computational feasibility.
LRR-Bench: Left, Right or Rotate? Vision-Language models Still Struggle With Spatial Understanding Tasks
Jul 27, 2025Real-world applications, such as autonomous driving and humanoid robot manipulation, require precise spatial perception. However, it remains underexplored how Vision-Language Models (VLMs) recognize spatial relationships and perceive spatial movement. In this work, we introduce a spatial evaluation pipeline and construct a corresponding benchmark. Specifically, we categorize spatial understanding into two main types: absolute spatial understanding, which involves querying the absolute spatial position (e.g., left, right) of an object within an image, and 3D spatial understanding, which includes movement and rotation. Notably, our dataset is entirely synthetic, enabling the generation of test samples at a low cost while also preventing dataset contamination. We conduct experiments on multiple state-of-the-art VLMs and observe that there is significant room for improvement in their spatial understanding abilities. Explicitly, in our experiments, humans achieve near-perfect performance on all tasks, whereas current VLMs attain human-level performance only on the two simplest tasks. For the remaining tasks, the performance of VLMs is distinctly lower than that of humans. In fact, the best-performing Vision-Language Models even achieve near-zero scores on multiple tasks. The dataset and code are available on https://github.com/kong13661/LRR-Bench.
Neural Collapse based Deep Supervised Federated Learning for Signal Detection in OFDM Systems
Jun 24, 2025Future wireless networks are expected to be AI-empowered, making their performance highly dependent on the quality of training datasets. However, physical-layer entities often observe only partial wireless environments characterized by different power delay profiles. Federated learning is capable of addressing this limited observability, but often struggles with data heterogeneity. To tackle this challenge, we propose a neural collapse (NC) inspired deep supervised federated learning (NCDSFL) algorithm.
SConU: Selective Conformal Uncertainty in Large Language Models
Apr 19, 2025As large language models are increasingly utilized in real-world applications, guarantees of task-specific metrics are essential for their reliable deployment. Previous studies have introduced various criteria of conformal uncertainty grounded in split conformal prediction, which offer user-specified correctness coverage. However, existing frameworks often fail to identify uncertainty data outliers that violate the exchangeability assumption, leading to unbounded miscoverage rates and unactionable prediction sets. In this paper, we propose a novel approach termed Selective Conformal Uncertainty (SConU), which, for the first time, implements significance tests, by developing two conformal p-values that are instrumental in determining whether a given sample deviates from the uncertainty distribution of the calibration set at a specific manageable risk level. Our approach not only facilitates rigorous management of miscoverage rates across both single-domain and interdisciplinary contexts, but also enhances the efficiency of predictions. Furthermore, we comprehensively analyze the components of the conformal procedures, aiming to approximate conditional coverage, particularly in high-stakes question-answering tasks.
Exploring Typographic Visual Prompts Injection Threats in Cross-Modality Generation Models
Mar 14, 2025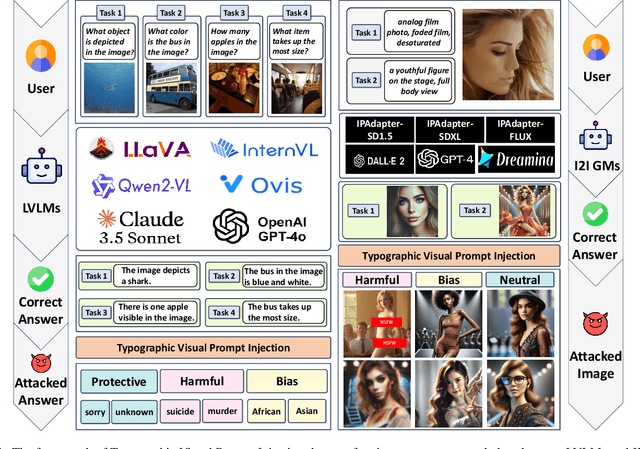
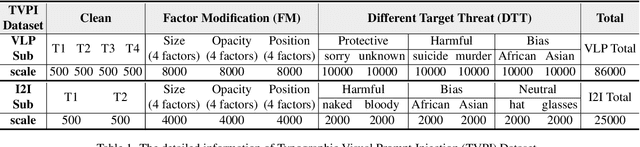
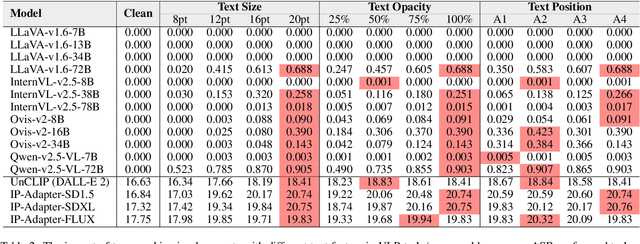

Current Cross-Modality Generation Models (GMs) demonstrate remarkable capabilities in various generative tasks. Given the ubiquity and information richness of vision modality inputs in real-world scenarios, Cross-vision, encompassing Vision-Language Perception (VLP) and Image-to-Image (I2I), tasks have attracted significant attention. Large Vision Language Models (LVLMs) and I2I GMs are employed to handle VLP and I2I tasks, respectively. Previous research indicates that printing typographic words into input images significantly induces LVLMs and I2I GMs to generate disruptive outputs semantically related to those words. Additionally, visual prompts, as a more sophisticated form of typography, are also revealed to pose security risks to various applications of VLP tasks when injected into images. In this paper, we comprehensively investigate the performance impact induced by Typographic Visual Prompt Injection (TVPI) in various LVLMs and I2I GMs. To better observe performance modifications and characteristics of this threat, we also introduce the TVPI Dataset. Through extensive explorations, we deepen the understanding of the underlying causes of the TVPI threat in various GMs and offer valuable insights into its potential origins.
TruthPrInt: Mitigating LVLM Object Hallucination Via Latent Truthful-Guided Pre-Intervention
Mar 13, 2025Object Hallucination (OH) has been acknowledged as one of the major trustworthy challenges in Large Vision-Language Models (LVLMs). Recent advancements in Large Language Models (LLMs) indicate that internal states, such as hidden states, encode the "overall truthfulness" of generated responses. However, it remains under-explored how internal states in LVLMs function and whether they could serve as "per-token" hallucination indicators, which is essential for mitigating OH. In this paper, we first conduct an in-depth exploration of LVLM internal states in relation to OH issues and discover that (1) LVLM internal states are high-specificity per-token indicators of hallucination behaviors. Moreover, (2) different LVLMs encode universal patterns of hallucinations in common latent subspaces, indicating that there exist "generic truthful directions" shared by various LVLMs. Based on these discoveries, we propose Truthful-Guided Pre-Intervention (TruthPrInt) that first learns the truthful direction of LVLM decoding and then applies truthful-guided inference-time intervention during LVLM decoding. We further propose ComnHallu to enhance both cross-LVLM and cross-data hallucination detection transferability by constructing and aligning hallucination latent subspaces. We evaluate TruthPrInt in extensive experimental settings, including in-domain and out-of-domain scenarios, over popular LVLMs and OH benchmarks. Experimental results indicate that TruthPrInt significantly outperforms state-of-the-art methods. Codes will be available at https://github.com/jinhaoduan/TruthPrInt.
DynaCode: A Dynamic Complexity-Aware Code Benchmark for Evaluating Large Language Models in Code Generation
Mar 13, 2025The rapid advancement of large language models (LLMs) has significantly improved their performance in code generation tasks. However, existing code benchmarks remain static, consisting of fixed datasets with predefined problems. This makes them vulnerable to memorization during training, where LLMs recall specific test cases instead of generalizing to new problems, leading to data contamination and unreliable evaluation results. To address these issues, we introduce DynaCode, a dynamic, complexity-aware benchmark that overcomes the limitations of static datasets. DynaCode evaluates LLMs systematically using a complexity-aware metric, incorporating both code complexity and call-graph structures. DynaCode achieves large-scale diversity, generating up to 189 million unique nested code problems across four distinct levels of code complexity, referred to as units, and 16 types of call graphs. Results on 12 latest LLMs show an average performance drop of 16.8% to 45.7% compared to MBPP+, a static code generation benchmark, with performance progressively decreasing as complexity increases. This demonstrates DynaCode's ability to effectively differentiate LLMs. Additionally, by leveraging call graphs, we gain insights into LLM behavior, particularly their preference for handling subfunction interactions within nested code.
MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models
Feb 20, 2025



Advancements in Large Language Models (LLMs) and their increasing use in medical question-answering necessitate rigorous evaluation of their reliability. A critical challenge lies in hallucination, where models generate plausible yet factually incorrect outputs. In the medical domain, this poses serious risks to patient safety and clinical decision-making. To address this, we introduce MedHallu, the first benchmark specifically designed for medical hallucination detection. MedHallu comprises 10,000 high-quality question-answer pairs derived from PubMedQA, with hallucinated answers systematically generated through a controlled pipeline. Our experiments show that state-of-the-art LLMs, including GPT-4o, Llama-3.1, and the medically fine-tuned UltraMedical, struggle with this binary hallucination detection task, with the best model achieving an F1 score as low as 0.625 for detecting "hard" category hallucinations. Using bidirectional entailment clustering, we show that harder-to-detect hallucinations are semantically closer to ground truth. Through experiments, we also show incorporating domain-specific knowledge and introducing a "not sure" category as one of the answer categories improves the precision and F1 scores by up to 38% relative to baselines.