 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRR-Bench: Left, Right or Rotate? Vision-Language models Still Struggle With Spatial Understanding Tasks
Jul 27, 2025Real-world applications, such as autonomous driving and humanoid robot manipulation, require precise spatial perception. However, it remains underexplored how Vision-Language Models (VLMs) recognize spatial relationships and perceive spatial movement. In this work, we introduce a spatial evaluation pipeline and construct a corresponding benchmark. Specifically, we categorize spatial understanding into two main types: absolute spatial understanding, which involves querying the absolute spatial position (e.g., left, right) of an object within an image, and 3D spatial understanding, which includes movement and rotation. Notably, our dataset is entirely synthetic, enabling the generation of test samples at a low cost while also preventing dataset contamination. We conduct experiments on multiple state-of-the-art VLMs and observe that there is significant room for improvement in their spatial understanding abilities. Explicitly, in our experiments, humans achieve near-perfect performance on all tasks, whereas current VLMs attain human-level performance only on the two simplest tasks. For the remaining tasks, the performance of VLMs is distinctly lower than that of humans. In fact, the best-performing Vision-Language Models even achieve near-zero scores on multiple tasks. The dataset and code are available on https://github.com/kong13661/LRR-Bench.
The Final Layer Holds the Key: A Unified and Efficient GNN Calibration Framework
May 16, 2025Graph Neural Networks (GNNs) have demonstrated remarkable effectiveness on graph-based tasks. However, their predictive confidence is often miscalibrated, typically exhibiting under-confidence, which harms the reliability of their decisions. Existing calibration methods for GNNs normally introduce additional calibration components, which fail to capture the intrinsic relationship between the model and the prediction confidence, resulting in limited theoretical guarantees and increased computational overhead. To address this issue, we propose a simple yet efficient graph calibration method. We establish a unified theoretical framework revealing that model confidence is jointly governed by class-centroid-level and node-level calibration at the final layer. Based on this insight, we theoretically show that reducing the weight decay of the final-layer parameters alleviates GNN under-confidence by acting on the class-centroid level, while node-level calibration acts as a finer-grained complement to class-centroid level calibration, which encourages each test node to be closer to its predicted class centroid at the final-layer representations. Extensive experiments validate the superiority of our method.
SConU: Selective Conformal Uncertainty in Large Language Models
Apr 19, 2025As large language models are increasingly utilized in real-world applications, guarantees of task-specific metrics are essential for their reliable deployment. Previous studies have introduced various criteria of conformal uncertainty grounded in split conformal prediction, which offer user-specified correctness coverage. However, existing frameworks often fail to identify uncertainty data outliers that violate the exchangeability assumption, leading to unbounded miscoverage rates and unactionable prediction sets. In this paper, we propose a novel approach termed Selective Conformal Uncertainty (SConU), which, for the first time, implements significance tests, by developing two conformal p-values that are instrumental in determining whether a given sample deviates from the uncertainty distribution of the calibration set at a specific manageable risk level. Our approach not only facilitates rigorous management of miscoverage rates across both single-domain and interdisciplinary contexts, but also enhances the efficiency of predictions. Furthermore, we comprehensively analyze the components of the conformal procedures, aiming to approximate conditional coverage, particularly in high-stakes question-answering tasks.
TruthPrInt: Mitigating LVLM Object Hallucination Via Latent Truthful-Guided Pre-Intervention
Mar 13, 2025Object Hallucination (OH) has been acknowledged as one of the major trustworthy challenges in Large Vision-Language Models (LVLMs). Recent advancements in Large Language Models (LLMs) indicate that internal states, such as hidden states, encode the "overall truthfulness" of generated responses. However, it remains under-explored how internal states in LVLMs function and whether they could serve as "per-token" hallucination indicators, which is essential for mitigating OH. In this paper, we first conduct an in-depth exploration of LVLM internal states in relation to OH issues and discover that (1) LVLM internal states are high-specificity per-token indicators of hallucination behaviors. Moreover, (2) different LVLMs encode universal patterns of hallucinations in common latent subspaces, indicating that there exist "generic truthful directions" shared by various LVLMs. Based on these discoveries, we propose Truthful-Guided Pre-Intervention (TruthPrInt) that first learns the truthful direction of LVLM decoding and then applies truthful-guided inference-time intervention during LVLM decoding. We further propose ComnHallu to enhance both cross-LVLM and cross-data hallucination detection transferability by constructing and aligning hallucination latent subspaces. We evaluate TruthPrInt in extensive experimental settings, including in-domain and out-of-domain scenarios, over popular LVLMs and OH benchmarks. Experimental results indicate that TruthPrInt significantly outperforms state-of-the-art methods. Codes will be available at https://github.com/jinhaoduan/TruthPrInt.
ELU-GCN: Effectively Label-Utilizing Graph Convolutional Network
Nov 04, 2024
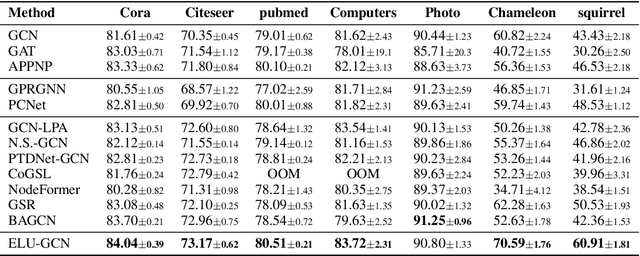


The message-passing mechanism of graph convolutional networks (i.e., GCNs) enables label information to be propagated to a broader range of neighbors, thereby increasing the utilization of labels. However, the label information is not always effectively utilized in the traditional GCN framework. To address this issue, we propose a new two-step framework called ELU-GCN. In the first stage, ELU-GCN conducts graph learning to learn a new graph structure (\ie ELU-graph), which enables GCNs to effectively utilize label information. In the second stage, we design a new graph contrastive learning on the GCN framework for representation learning by exploring the consistency and mutually exclusive information between the learned ELU graph and the original graph. Moreover, we theoretically demonstrate that the proposed method can ensure the generalization ability of GCNs. Extensive experiments validate the superiority of the proposed method.
ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees
Jun 29, 2024



Uncertainty quantification (UQ) in natural language generation (NLG) tasks remains an open challenge, exacerbated by the intricate nature of the recent large language models (LLMs). This study investigates adapting conformal prediction (CP), which can convert any heuristic measure of uncertainty into rigorous theoretical guarantees by constructing prediction sets, for black-box LLMs in open-ended NLG tasks. We propose a sampling-based uncertainty measure leveraging self-consistency and develop a conformal uncertainty criterion by integrating the uncertainty condition aligned with correctness into the design of the CP algorithm. Experimental results indicate that our uncertainty measure generally surpasses prior state-of-the-art methods. Furthermore, we calibrate the prediction sets within the model's unfixed answer distribution and achieve strict control over the correctness coverage rate across 6 LLMs on 4 free-form NLG datasets, spanning general-purpose and medical domains, while the small average set size further highlights the efficiency of our method in providing trustworthy guarantees for practical open-ended NLG applications.
Word-Sequence Entropy: Towards Uncertainty Estimation in Free-Form Medical Question Answering Applications and Beyond
Feb 22, 2024



Uncertainty estimation plays a pivotal role in ensuring the reliability of safety-critical human-AI interaction systems, particularly in the medical domain. However, a general method for quantifying the uncertainty of free-form answers has yet to be established in open-ended medical question-answering (QA) tasks, where irrelevant words and sequences with limited semantic information can be the primary source of uncertainty due to the presence of generative inequality. In this paper, we propose the Word-Sequence Entropy (WSE), which calibrates the uncertainty proportion at both the word and sequence levels according to the semantic relevance, with greater emphasis placed on keywords and more relevant sequences when performing uncertainty quantification. We compare WSE with 6 baseline methods on 5 free-form medical QA datasets, utilizing 7 "off-the-shelf" large language models (LLMs), and show that WSE exhibits superior performance on accurate uncertainty measurement under two standard criteria for correctness evaluation (e.g., WSE outperforms existing state-of-the-art method by 3.23% AUROC on the MedQA dataset). Additionally, in terms of the potential for real-world medical QA applications, we achieve a significant enhancement in the performance of LLMs when employing sequences with lower uncertainty, identified by WSE, as final answers (e.g., +6.36% accuracy improvement on the COVID-QA dataset), without requiring any additional task-specific fine-tuning or architectural modifications.
ACT: Adversarial Consistency Models
Nov 23, 2023



Though diffusion models excel in image generation, their step-by-step denoising leads to slow generation speeds. Consistency training addresses this issue with single-step sampling but often produces lower-quality generations and requires high training costs. In this paper, we show that optimizing consistency training loss minimizes the Wasserstein distance between target and generated distributions. As timestep increases, the upper bound accumulates previous consistency training losses. Therefore, larger batch sizes are needed to reduce both current and accumulated losses. We propose Adversarial Consistency Training (ACT), which directly minimizes the Jensen-Shannon (JS) divergence between distributions at each timestep using a discriminator. Theoretically, ACT enhances generation quality, and convergence. By incorporating a discriminator into the consistency training framework, our method achieves improved FID scores on CIFAR10 and ImageNet 64$\times$64, retains zero-shot image inpainting capabilities, and uses less than $1/6$ of the original batch size and fewer than $1/2$ of the model parameters and training steps compared to the baseline method, this leads to a substantial reduction in resource consumption.
Feature Noise Boosts DNN Generalization under Label Noise
Aug 03, 2023



The presence of label noise in the training data has a profound impact on the generalization of deep neural networks (DNNs). In this study, we introduce and theoretically demonstrate a simple feature noise method, which directly adds noise to the features of training data, can enhance the generalization of DNNs under label noise. Specifically, we conduct theoretical analyses to reveal that label noise leads to weakened DNN generalization by loosening the PAC-Bayes generalization bound, and feature noise results in better DNN generalization by imposing an upper bound on the mutual information between the model weights and the features, which constrains the PAC-Bayes generalization bound. Furthermore, to ensure effective generalization of DNNs in the presence of label noise, we conduct application analyses to identify the optimal types and levels of feature noise to add for obtaining desirable label noise generalization. Finally, extensive experimental results on several popular datasets demonstrate the feature noise method can significantly enhance the label noise generalization of the state-of-the-art label noise method.
Exposing the Fake: Effective Diffusion-Generated Images Detection
Jul 12, 2023



Image synthesis has seen significant advancements with the advent of diffusion-based generative models like Denoising Diffusion Probabilistic Models (DDPM) and text-to-image diffusion models. Despite their efficacy, there is a dearth of research dedicated to detecting diffusion-generated images, which could pose potential security and privacy risks. This paper addresses this gap by proposing a novel detection method called Stepwise Error for Diffusion-generated Image Detection (SeDID). Comprising statistical-based $\text{SeDID}_{\text{Stat}}$ and neural network-based $\text{SeDID}_{\text{NNs}}$, SeDID exploits the unique attributes of diffusion models, namely deterministic reverse and deterministic denoising computation errors. Our evaluations demonstrate SeDID's superior performance over existing methods when applied to diffusion models. Thus, our work makes a pivotal contribution to distinguishing diffusion model-generated images, marking a significant step in the domain of artificial intelligence security.