 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Self-Supervised Heterogeneous Graph Learning from Spectral Clustering Perspective
Dec 01, 2024



Self-supervised heterogeneous graph learning (SHGL) has shown promising potential in diverse scenarios. However, while existing SHGL methods share a similar essential with clustering approaches, they encounter two significant limitations: (i) noise in graph structures is often introduced during the message-passing process to weaken node representations, and (ii) cluster-level information may be inadequately captured and leveraged, diminishing the performance in downstream tasks. In this paper, we address these limitations by theoretically revisiting SHGL from the spectral clustering perspective and introducing a novel framework enhanced by rank and dual consistency constraints. Specifically, our framework incorporates a rank-constrained spectral clustering method that refines the affinity matrix to exclude noise effectively. Additionally, we integrate node-level and cluster-level consistency constraints that concurrently capture invariant and clustering information to facilitate learning in downstream tasks. We theoretically demonstrate that the learned representations are divided into distinct partitions based on the number of classes and exhibit enhanced generalization ability across tasks. Experimental results affirm the superiority of our method, showcasing remarkable improvements in several downstream tasks compared to existing methods.
ELU-GCN: Effectively Label-Utilizing Graph Convolutional Network
Nov 04, 2024
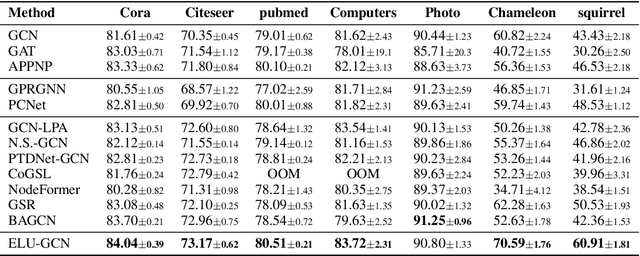


The message-passing mechanism of graph convolutional networks (i.e., GCNs) enables label information to be propagated to a broader range of neighbors, thereby increasing the utilization of labels. However, the label information is not always effectively utilized in the traditional GCN framework. To address this issue, we propose a new two-step framework called ELU-GCN. In the first stage, ELU-GCN conducts graph learning to learn a new graph structure (\ie ELU-graph), which enables GCNs to effectively utilize label information. In the second stage, we design a new graph contrastive learning on the GCN framework for representation learning by exploring the consistency and mutually exclusive information between the learned ELU graph and the original graph. Moreover, we theoretically demonstrate that the proposed method can ensure the generalization ability of GCNs. Extensive experiments validate the superiority of the proposed method.
HG-Adapter: Improving Pre-Trained Heterogeneous Graph Neural Networks with Dual Adapters
Nov 02, 2024



The "pre-train, prompt-tuning'' paradigm has demonstrated impressive performance for tuning pre-trained heterogeneous graph neural networks (HGNNs) by mitigating the gap between pre-trained models and downstream tasks. However, most prompt-tuning-based works may face at least two limitations: (i) the model may be insufficient to fit the graph structures well as they are generally ignored in the prompt-tuning stage, increasing the training error to decrease the generalization ability; and (ii) the model may suffer from the limited labeled data during the prompt-tuning stage, leading to a large generalization gap between the training error and the test error to further affect the model generalization. To alleviate the above limitations, we first derive the generalization error bound for existing prompt-tuning-based methods, and then propose a unified framework that combines two new adapters with potential labeled data extension to improve the generalization of pre-trained HGNN models. Specifically, we design dual structure-aware adapters to adaptively fit task-related homogeneous and heterogeneous structural information. We further design a label-propagated contrastive loss and two self-supervised losses to optimize dual adapters and incorporate unlabeled nodes as potential labeled data. Theoretical analysis indicates that the proposed method achieves a lower generalization error bound than existing methods, thus obtaining superior generalization ability. Comprehensive experiments demonstrate the effectiveness and generalization of the proposed method on different downstream tasks.