 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Expand-Merge: Training-Free Token Compression for Vision-Language-Action Models
Dec 10, 2025Vision-Language-Action (VLA) models pretrained on large-scale multimodal datasets have emerged as powerful foundations for robotic perception and control. However, their massive scale, often billions of parameters, poses significant challenges for real-time deployment, as inference becomes computationally expensive and latency-sensitive in dynamic environments. To address this, we propose Token Expand-and-Merge-VLA (TEAM-VLA), a training-free token compression framework that accelerates VLA inference while preserving task performance. TEAM-VLA introduces a dynamic token expansion mechanism that identifies and samples additional informative tokens in the spatial vicinity of attention-highlighted regions, enhancing contextual completeness. These expanded tokens are then selectively merged in deeper layers under action-aware guidance, effectively reducing redundancy while maintaining semantic coherence. By coupling expansion and merging within a single feed-forward pass, TEAM-VLA achieves a balanced trade-off between efficiency and effectiveness, without any retraining or parameter updates. Extensive experiments on LIBERO benchmark demonstrate that TEAM-VLA consistently improves inference speed while maintaining or even surpassing the task success rate of full VLA models. The code is public available on \href{https://github.com/Jasper-aaa/TEAM-VLA}{https://github.com/Jasper-aaa/TEAM-VLA}
Temporal Realism Evaluation of Generated Videos Using Compressed-Domain Motion Vectors
Nov 17, 2025Temporal realism remains a central weakness of current generative video models, as most evaluation metrics prioritize spatial appearance and offer limited sensitivity to motion. We introduce a scalable, model-agnostic framework that assesses temporal behavior using motion vectors (MVs) extracted directly from compressed video streams. Codec-generated MVs from standards such as H.264 and HEVC provide lightweight, resolution-consistent descriptors of motion dynamics. We quantify realism by computing Kullback-Leibler, Jensen-Shannon, and Wasserstein divergences between MV statistics of real and generated videos. Experiments on the GenVidBench dataset containing videos from eight state-of-the-art generators reveal systematic discrepancies from real motion: entropy-based divergences rank Pika and SVD as closest to real videos, MV-sum statistics favor VC2 and Text2Video-Zero, and CogVideo shows the largest deviations across both measures. Visualizations of MV fields and class-conditional motion heatmaps further reveal center bias, sparse and piecewise constant flows, and grid-like artifacts that frame-level metrics do not capture. Beyond evaluation, we investigate MV-RGB fusion through channel concatenation, cross-attention, joint embedding, and a motion-aware fusion module. Incorporating MVs improves downstream classification across ResNet, I3D, and TSN backbones, with ResNet-18 and ResNet-34 reaching up to 97.4% accuracy and I3D achieving 99.0% accuracy on real-versus-generated discrimination. These findings demonstrate that compressed-domain MVs provide an effective temporal signal for diagnosing motion defects in generative videos and for strengthening temporal reasoning in discriminative models. The implementation is available at: https://github.com/KurbanIntelligenceLab/Motion-Vector-Learning
Revisiting Self-Supervised Heterogeneous Graph Learning from Spectral Clustering Perspective
Dec 01, 2024



Self-supervised heterogeneous graph learning (SHGL) has shown promising potential in diverse scenarios. However, while existing SHGL methods share a similar essential with clustering approaches, they encounter two significant limitations: (i) noise in graph structures is often introduced during the message-passing process to weaken node representations, and (ii) cluster-level information may be inadequately captured and leveraged, diminishing the performance in downstream tasks. In this paper, we address these limitations by theoretically revisiting SHGL from the spectral clustering perspective and introducing a novel framework enhanced by rank and dual consistency constraints. Specifically, our framework incorporates a rank-constrained spectral clustering method that refines the affinity matrix to exclude noise effectively. Additionally, we integrate node-level and cluster-level consistency constraints that concurrently capture invariant and clustering information to facilitate learning in downstream tasks. We theoretically demonstrate that the learned representations are divided into distinct partitions based on the number of classes and exhibit enhanced generalization ability across tasks. Experimental results affirm the superiority of our method, showcasing remarkable improvements in several downstream tasks compared to existing methods.
Dual-Path Adversarial Lifting for Domain Shift Correction in Online Test-time Adaptation
Aug 26, 2024

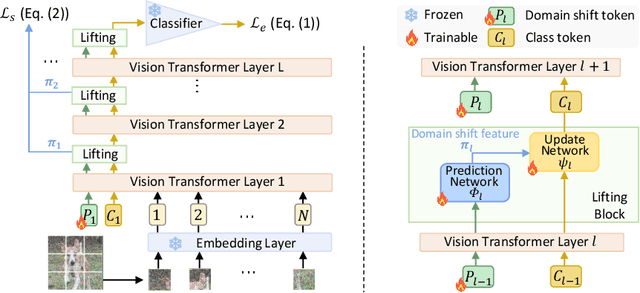
Transformer-based methods have achieved remarkable success in various machine learning tasks. How to design efficient test-time adaptation methods for transformer models becomes an important research task. In this work, motivated by the dual-subband wavelet lifting scheme developed in multi-scale signal processing which is able to efficiently separate the input signals into principal components and noise components, we introduce a dual-path token lifting for domain shift correction in test time adaptation. Specifically, we introduce an extra token, referred to as \textit{domain shift token}, at each layer of the transformer network. We then perform dual-path lifting with interleaved token prediction and update between the path of domain shift tokens and the path of class tokens at all network layers. The prediction and update networks are learned in an adversarial manner. Specifically, the task of the prediction network is to learn the residual noise of domain shift which should be largely invariant across all classes and all samples in the target domain. In other words, the predicted domain shift noise should be indistinguishable between all sample classes. On the other hand, the task of the update network is to update the class tokens by removing the domain shift from the input image samples so that input samples become more discriminative between different classes in the feature space. To effectively learn the prediction and update networks with two adversarial tasks, both theoretically and practically, we demonstrate that it is necessary to use smooth optimization for the update network but non-smooth optimization for the prediction network. Experimental results on the benchmark datasets demonstrate that our proposed method significantly improves the online fully test-time domain adaptation performance. Code is available at \url{https://github.com/yushuntang/DPAL}.
Parameter-Efficient and Memory-Efficient Tuning for Vision Transformer: A Disentangled Approach
Jul 09, 2024



Recent works on parameter-efficient transfer learning (PETL) show the potential to adapt a pre-trained Vision Transformer to downstream recognition tasks with only a few learnable parameters. However, since they usually insert new structures into the pre-trained model, entire intermediate features of that model are changed and thus need to be stored to be involved in back-propagation, resulting in memory-heavy training. We solve this problem from a novel disentangled perspective, i.e., dividing PETL into two aspects: task-specific learning and pre-trained knowledge utilization. Specifically, we synthesize the task-specific query with a learnable and lightweight module, which is independent of the pre-trained model. The synthesized query equipped with task-specific knowledge serves to extract the useful features for downstream tasks from the intermediate representations of the pre-trained model in a query-only manner. Built upon these features, a customized classification head is proposed to make the prediction for the input sample. lightweight architecture and avoids the use of heavy intermediate features for running gradient descent, it demonstrates limited memory usage in training. Extensive experiments manifest that our method achieves state-of-the-art performance under memory constraints, showcasing its applicability in real-world situations.
Beyond Sole Strength: Customized Ensembles for Generalized Vision-Language Models
Nov 28, 2023



Fine-tuning pre-trained vision-language models (VLMs), e.g., CLIP, for the open-world generalization has gained increasing popularity due to its practical value. However, performance advancements are limited when relying solely on intricate algorithmic designs for a single model, even one exhibiting strong performance, e.g., CLIP-ViT-B/16. This paper, for the first time, explores the collaborative potential of leveraging much weaker VLMs to enhance the generalization of a robust single model. The affirmative findings motivate us to address the generalization problem from a novel perspective, i.e., ensemble of pre-trained VLMs. We introduce three customized ensemble strategies, each tailored to one specific scenario. Firstly, we introduce the zero-shot ensemble, automatically adjusting the logits of different models based on their confidence when only pre-trained VLMs are available. Furthermore, for scenarios with extra few-shot samples, we propose the training-free and tuning ensemble, offering flexibility based on the availability of computing resources. The proposed ensemble strategies are evaluated on zero-shot, base-to-new, and cross-dataset generalization, achieving new state-of-the-art performance. Notably, this work represents an initial stride toward enhancing the generalization performance of VLMs via ensemble. The code is available at https://github.com/zhiheLu/Ensemble_VLM.git.
GraphAdapter: Tuning Vision-Language Models With Dual Knowledge Graph
Sep 24, 2023



Adapter-style efficient transfer learning (ETL) has shown excellent performance in the tuning of vision-language models (VLMs) under the low-data regime, where only a few additional parameters are introduced to excavate the task-specific knowledge based on the general and powerful representation of VLMs. However, most adapter-style works face two limitations: (i) modeling task-specific knowledge with a single modality only; and (ii) overlooking the exploitation of the inter-class relationships in downstream tasks, thereby leading to sub-optimal solutions. To mitigate that, we propose an effective adapter-style tuning strategy, dubbed GraphAdapter, which performs the textual adapter by explicitly modeling the dual-modality structure knowledge (i.e., the correlation of different semantics/classes in textual and visual modalities) with a dual knowledge graph. In particular, the dual knowledge graph is established with two sub-graphs, i.e., a textual knowledge sub-graph, and a visual knowledge sub-graph, where the nodes and edges represent the semantics/classes and their correlations in two modalities, respectively. This enables the textual feature of each prompt to leverage the task-specific structure knowledge from both textual and visual modalities, yielding a more effective classifier for downstream tasks. Extensive experimental results on 11 benchmark datasets reveal that our GraphAdapter significantly outperforms previous adapter-based methods. The code will be released at https://github.com/lixinustc/GraphAdapter
Efficient Multi-Grained Knowledge Reuse for Class Incremental Segmentation
Jun 03, 2023Class Incremental Semantic Segmentation (CISS) has been a trend recently due to its great significance in real-world applications. Although the existing CISS methods demonstrate remarkable performance, they either leverage the high-level knowledge (feature) only while neglecting the rich and diverse knowledge in the low-level features, leading to poor old knowledge preservation and weak new knowledge exploration; or use multi-level features for knowledge distillation by retraining a heavy backbone, which is computationally intensive. In this paper, we for the first time propose to efficiently reuse the multi-grained knowledge for CISS by fusing multi-level features with the frozen backbone and show a simple aggregation of varying-level features, i.e., naive feature pyramid, can boost the performance significantly. We further introduce a novel densely-interactive feature pyramid (DEFY) module that enhances the fusion of high- and low-level features by enabling their dense interaction. Specifically, DEFY establishes a per-pixel relationship between pairs of feature maps, allowing for multi-pair outputs to be aggregated. This results in improved semantic segmentation by leveraging the complementary information from multi-level features. We show that DEFY can be effortlessly integrated into three representative methods for performance enhancement. Our method yields a new state-of-the-art performance when combined with the current SOTA by notably averaged mIoU gains on two widely used benchmarks, i.e., 2.5% on PASCAL VOC 2012 and 2.3% on ADE20K.
A Dive into SAM Prior in Image Restoration
May 23, 2023
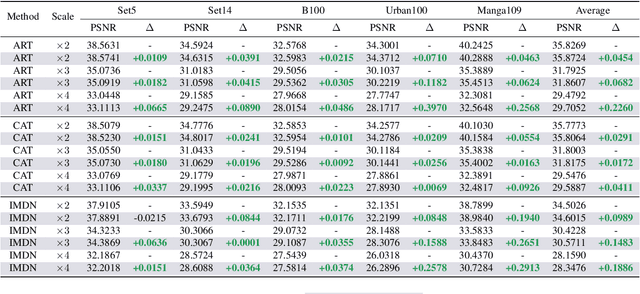
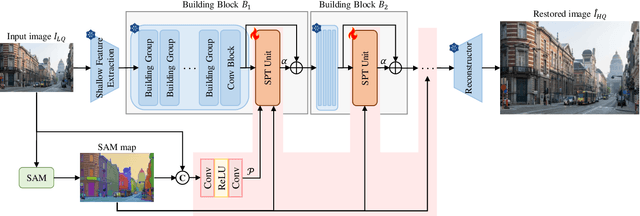
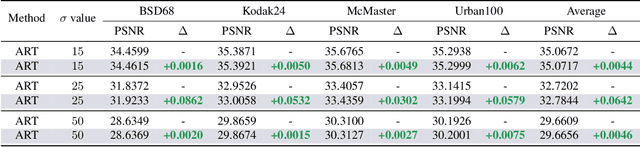
The goal of image restoration (IR), a fundamental issue in computer vision, is to restore a high-quality (HQ) image from its degraded low-quality (LQ) observation. Multiple HQ solutions may correspond to an LQ input in this poorly posed problem, creating an ambiguous solution space. This motivates the investigation and incorporation of prior knowledge in order to effectively constrain the solution space and enhance the quality of the restored images. In spite of the pervasive use of hand-crafted and learned priors in IR, limited attention has been paid to the incorporation of knowledge from large-scale foundation models. In this paper, we for the first time leverage the prior knowledge of the state-of-the-art segment anything model (SAM) to boost the performance of existing IR networks in an parameter-efficient tuning manner. In particular, the choice of SAM is based on its robustness to image degradations, such that HQ semantic masks can be extracted from it. In order to leverage semantic priors and enhance restoration quality, we propose a lightweight SAM prior tuning (SPT) unit. This plug-and-play component allows us to effectively integrate semantic priors into existing IR networks, resulting in significant improvements in restoration quality. As the only trainable module in our method, the SPT unit has the potential to improve both efficiency and scalability. We demonstrate the effectiveness of the proposed method in enhancing a variety of methods across multiple tasks, such as image super-resolution and color image denoising.
Can SAM Boost Video Super-Resolution?
May 12, 2023The primary challenge in video super-resolution (VSR) is to handle large motions in the input frames, which makes it difficult to accurately aggregate information from multiple frames. Existing works either adopt deformable convolutions or estimate optical flow as a prior to establish correspondences between frames for the effective alignment and fusion. However, they fail to take into account the valuable semantic information that can greatly enhance it; and flow-based methods heavily rely on the accuracy of a flow estimate model, which may not provide precise flows given two low-resolution frames. In this paper, we investigate a more robust and semantic-aware prior for enhanced VSR by utilizing the Segment Anything Model (SAM), a powerful foundational model that is less susceptible to image degradation. To use the SAM-based prior, we propose a simple yet effective module -- SAM-guidEd refinEment Module (SEEM), which can enhance both alignment and fusion procedures by the utilization of semantic information. This light-weight plug-in module is specifically designed to not only leverage the attention mechanism for the generation of semantic-aware feature but also be easily and seamlessly integrated into existing methods. Concretely, we apply our SEEM to two representative methods, EDVR and BasicVSR, resulting in consistently improved performance with minimal implementation effort, on three widely used VSR datasets: Vimeo-90K, REDS and Vid4. More importantly, we found that the proposed SEEM can advance the existing methods in an efficient tuning manner, providing increased flexibility in adjusting the balance between performance and the number of training parameters. Code will be open-source soon.