 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Conditioned Transformer for Fully Test-time Adaptation
Oct 14, 2024Fully test-time adaptation aims to adapt a network model online based on sequential analysis of input samples during the inference stage. We observe that, when applying a transformer network model into a new domain, the self-attention profiles of image samples in the target domain deviate significantly from those in the source domain, which results in large performance degradation during domain changes. To address this important issue, we propose a new structure for the self-attention modules in the transformer. Specifically, we incorporate three domain-conditioning vectors, called domain conditioners, into the query, key, and value components of the self-attention module. We learn a network to generate these three domain conditioners from the class token at each transformer network layer. We find that, during fully online test-time adaptation, these domain conditioners at each transform network layer are able to gradually remove the impact of domain shift and largely recover the original self-attention profile. Our extensive experimental results demonstrate that the proposed domain-conditioned transformer significantly improves the online fully test-time domain adaptation performance and outperforms existing state-of-the-art methods by large margins.
Dual-Path Adversarial Lifting for Domain Shift Correction in Online Test-time Adaptation
Aug 26, 2024

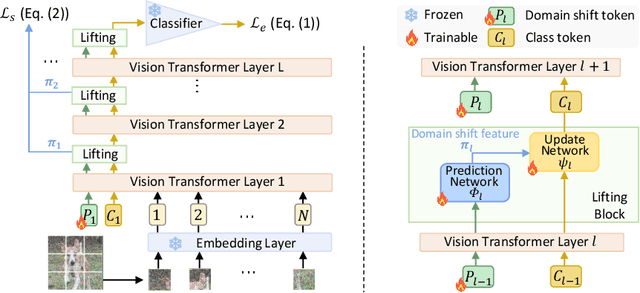
Transformer-based methods have achieved remarkable success in various machine learning tasks. How to design efficient test-time adaptation methods for transformer models becomes an important research task. In this work, motivated by the dual-subband wavelet lifting scheme developed in multi-scale signal processing which is able to efficiently separate the input signals into principal components and noise components, we introduce a dual-path token lifting for domain shift correction in test time adaptation. Specifically, we introduce an extra token, referred to as \textit{domain shift token}, at each layer of the transformer network. We then perform dual-path lifting with interleaved token prediction and update between the path of domain shift tokens and the path of class tokens at all network layers. The prediction and update networks are learned in an adversarial manner. Specifically, the task of the prediction network is to learn the residual noise of domain shift which should be largely invariant across all classes and all samples in the target domain. In other words, the predicted domain shift noise should be indistinguishable between all sample classes. On the other hand, the task of the update network is to update the class tokens by removing the domain shift from the input image samples so that input samples become more discriminative between different classes in the feature space. To effectively learn the prediction and update networks with two adversarial tasks, both theoretically and practically, we demonstrate that it is necessary to use smooth optimization for the update network but non-smooth optimization for the prediction network. Experimental results on the benchmark datasets demonstrate that our proposed method significantly improves the online fully test-time domain adaptation performance. Code is available at \url{https://github.com/yushuntang/DPAL}.
Learning Visual Conditioning Tokens to Correct Domain Shift for Fully Test-time Adaptation
Jun 27, 2024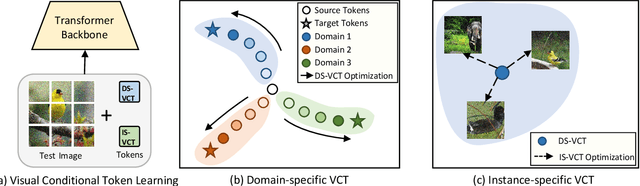
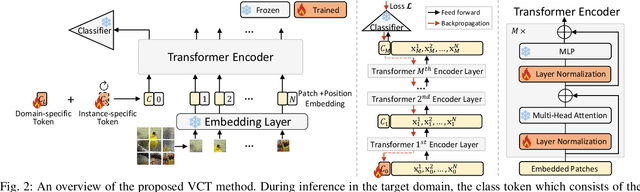
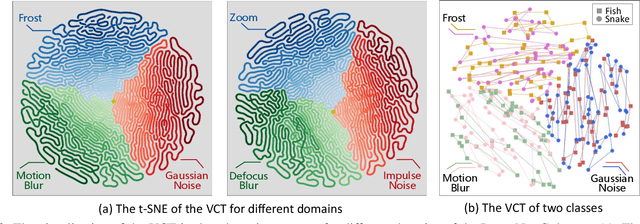
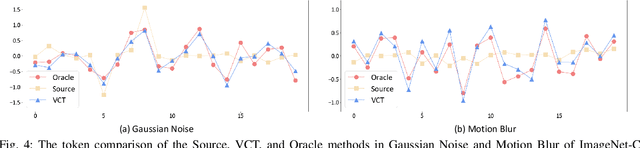
Fully test-time adaptation aims to adapt the network model based on sequential analysis of input samples during the inference stage to address the cross-domain performance degradation problem of deep neural networks. This work is based on the following interesting finding: in transformer-based image classification, the class token at the first transformer encoder layer can be learned to capture the domain-specific characteristics of target samples during test-time adaptation. This learned token, when combined with input image patch embeddings, is able to gradually remove the domain-specific information from the feature representations of input samples during the transformer encoding process, thereby significantly improving the test-time adaptation performance of the source model across different domains. We refer to this class token as visual conditioning token (VCT). To successfully learn the VCT, we propose a bi-level learning approach to capture the long-term variations of domain-specific characteristics while accommodating local variations of instance-specific characteristics. Experimental results on the benchmark datasets demonstrate that our proposed bi-level visual conditioning token learning method is able to achieve significantly improved test-time adaptation performance by up to 1.9%.
Self-Correctable and Adaptable Inference for Generalizable Human Pose Estimation
Mar 25, 2023A central challenge in human pose estimation, as well as in many other machine learning and prediction tasks, is the generalization problem. The learned network does not have the capability to characterize the prediction error, generate feedback information from the test sample, and correct the prediction error on the fly for each individual test sample, which results in degraded performance in generalization. In this work, we introduce a self-correctable and adaptable inference (SCAI) method to address the generalization challenge of network prediction and use human pose estimation as an example to demonstrate its effectiveness and performance. We learn a correction network to correct the prediction result conditioned by a fitness feedback error. This feedback error is generated by a learned fitness feedback network which maps the prediction result to the original input domain and compares it against the original input. Interestingly, we find that this self-referential feedback error is highly correlated with the actual prediction error. This strong correlation suggests that we can use this error as feedback to guide the correction process. It can be also used as a loss function to quickly adapt and optimize the correction network during the inference process. Our extensive experimental results on human pose estimation demonstrate that the proposed SCAI method is able to significantly improve the generalization capability and performance of human pose estimation.
Neuro-Modulated Hebbian Learning for Fully Test-Time Adaptation
Mar 10, 2023
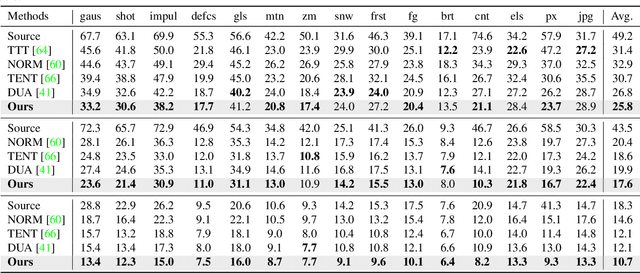
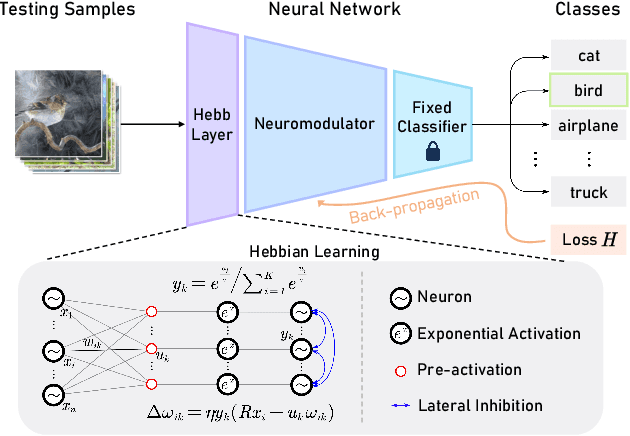

Fully test-time adaptation aims to adapt the network model based on sequential analysis of input samples during the inference stage to address the cross-domain performance degradation problem of deep neural networks. We take inspiration from the biological plausibility learning where the neuron responses are tuned based on a local synapse-change procedure and activated by competitive lateral inhibition rules. Based on these feed-forward learning rules, we design a soft Hebbian learning process which provides an unsupervised and effective mechanism for online adaptation. We observe that the performance of this feed-forward Hebbian learning for fully test-time adaptation can be significantly improved by incorporating a feedback neuro-modulation layer. It is able to fine-tune the neuron responses based on the external feedback generated by the error back-propagation from the top inference layers. This leads to our proposed neuro-modulated Hebbian learning (NHL) method for fully test-time adaptation. With the unsupervised feed-forward soft Hebbian learning being combined with a learned neuro-modulator to capture feedback from external responses, the source model can be effectively adapted during the testing process. Experimental results on benchmark datasets demonstrate that our proposed method can significantly improve the adaptation performance of network models and outperforms existing state-of-the-art methods.
Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation
Jul 06, 2022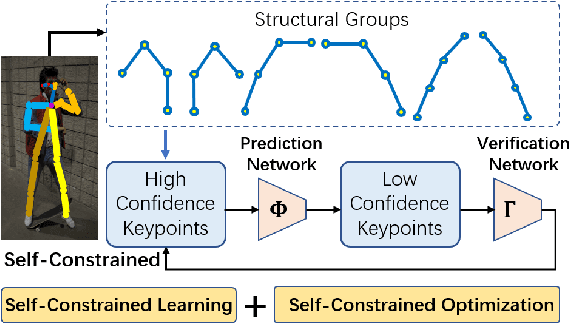
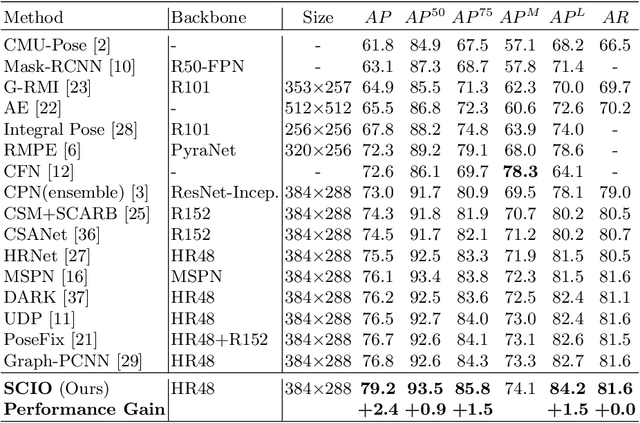
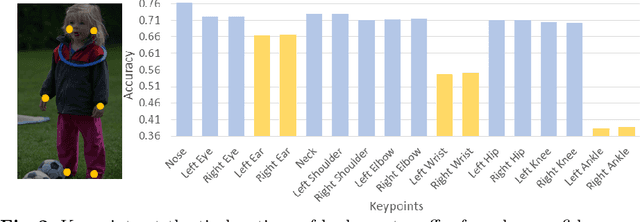

We observe that human poses exhibit strong group-wise structural correlation and spatial coupling between keypoints due to the biological constraints of different body parts. This group-wise structural correlation can be explored to improve the accuracy and robustness of human pose estimation. In this work, we develop a self-constrained prediction-verification network to characterize and learn the structural correlation between keypoints during training. During the inference stage, the feedback information from the verification network allows us to perform further optimization of pose prediction, which significantly improves the performance of human pose estimation. Specifically, we partition the keypoints into groups according to the biological structure of human body. Within each group, the keypoints are further partitioned into two subsets, high-confidence base keypoints and low-confidence terminal keypoints. We develop a self-constrained prediction-verification network to perform forward and backward predictions between these keypoint subsets. One fundamental challenge in pose estimation, as well as in generic prediction tasks, is that there is no mechanism for us to verify if the obtained pose estimation or prediction results are accurate or not, since the ground truth is not available. Once successfully learned, the verification network serves as an accuracy verification module for the forward pose prediction. During the inference stage, it can be used to guide the local optimization of the pose estimation results of low-confidence keypoints with the self-constrained loss on high-confidence keypoints as the objective function. Our extensive experimental results on benchmark MS COCO and CrowdPose datasets demonstrate that the proposed method can significantly improve the pose estimation results.