 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Apr 28, 2026Flow-based vision-language-action (VLA) policies offer strong expressivity for action generation, but suffer from a fundamental inefficiency: multi-step inference is required to recover action structure from uninformative Gaussian noise, leading to a poor efficiency-quality trade-off under real-time constraints. We address this issue by rethinking the role of the starting point in generative action modeling. Instead of shortening the sampling trajectory, we propose CF-VLA, a coarse-to-fine two-stage formulation that restructures action generation into a coarse initialization step that constructs an action-aware starting point, followed by a single-step local refinement that corrects residual errors. Concretely, the coarse stage learns a conditional posterior over endpoint velocity to transform Gaussian noise into a structured initialization, while the fine stage performs a fixed-time refinement from this initialization. To stabilize training, we introduce a stepwise strategy that first learns a controlled coarse predictor and then performs joint optimization. Experiments on CALVIN and LIBERO show that our method establishes a strong efficiency-performance frontier under low-NFE (Number of Function Evaluations) regimes: it consistently outperforms existing NFE=2 methods, matches or surpasses the NFE=10 $π_{0.5}$ baseline on several metrics, reduces action sampling latency by 75.4%, and achieves the best average real-robot success rate of 83.0%, outperforming MIP by 19.5 points and $π_{0.5}$ by 4.0 points. These results suggest that structured, coarse-to-fine generation enables both strong performance and efficient inference. Our code is available at https://github.com/EmbodiedAI-RoboTron/CF-VLA.
Latent Bias Alignment for High-Fidelity Diffusion Inversion in Real-World Image Reconstruction and Manipulation
Mar 25, 2026Recent research has shown that text-to-image diffusion models are capable of generating high-quality images guided by text prompts. But can they be used to generate or approximate real-world images from the seed noise? This is known as the diffusion inversion problem, which serves as a fundamental building block for bridging diffusion models and real-world scenarios. However, existing diffusion inversion methods often suffer from low reconstruction quality or weak robustness. Two major challenges need to be carefully addressed: (1) the misalignment between the inversion and generation trajectories during the diffusion process, and (2) the mismatch between the diffusion inversion process and the VQ autoencoder (VQAE) reconstruction. To address these challenges, we introduce a latent bias vector at each inversion step, which is learned to reduce the misalignment between inversion and generation trajectories. We refer to this strategy as Latent Bias Optimization (LBO). Furthermore, we perform an approximate joint optimization of the diffusion inversion and VQAE reconstruction processes by learning to adjust the image latent representation, which serves as the connecting interface between them. We refer to this technique as Image Latent Boosting (ILB). Extensive experimental results demonstrate that the proposed method significantly improves the image reconstruction quality of the diffusion model, as well as the performance of downstream tasks, including image editing and rare concept generation.
Training-Free Test-Time Adaptation with Brownian Distance Covariance in Vision-Language Models
Jan 30, 2026Vision-language models suffer performance degradation under domain shift, limiting real-world applicability. Existing test-time adaptation methods are computationally intensive, rely on back-propagation, and often focus on single modalities. To address these issues, we propose Training-free Test-Time Adaptation with Brownian Distance Covariance (TaTa). TaTa leverages Brownian Distance Covariance-a powerful statistical measure that captures both linear and nonlinear dependencies via pairwise distances-to dynamically adapt VLMs to new domains without training or back-propagation. This not only improves efficiency but also enhances stability by avoiding disruptive weight updates. TaTa further integrates attribute-enhanced prompting to improve vision-language inference with descriptive visual cues. Combined with dynamic clustering and pseudo-label refinement, it effectively recalibrates the model for novel visual contexts. Experiments across diverse datasets show that TaTa significantly reduces computational cost while achieving state-of-the-art performance in domain and cross-dataset generalization.
Progressive Conditioned Scale-Shift Recalibration of Self-Attention for Online Test-time Adaptation
Dec 14, 2025
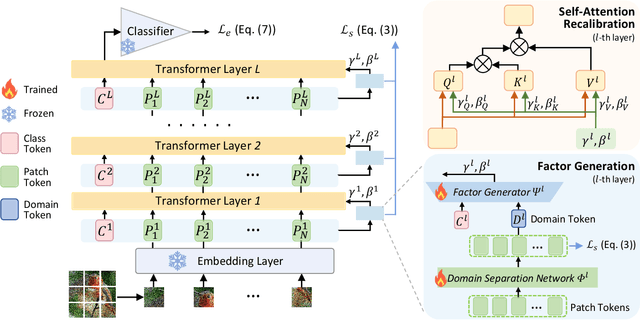


Online test-time adaptation aims to dynamically adjust a network model in real-time based on sequential input samples during the inference stage. In this work, we find that, when applying a transformer network model to a new target domain, the Query, Key, and Value features of its self-attention module often change significantly from those in the source domain, leading to substantial performance degradation of the transformer model. To address this important issue, we propose to develop a new approach to progressively recalibrate the self-attention at each layer using a local linear transform parameterized by conditioned scale and shift factors. We consider the online model adaptation from the source domain to the target domain as a progressive domain shift separation process. At each transformer network layer, we learn a Domain Separation Network to extract the domain shift feature, which is used to predict the scale and shift parameters for self-attention recalibration using a Factor Generator Network. These two lightweight networks are adapted online during inference. Experimental results on benchmark datasets demonstrate that the proposed progressive conditioned scale-shift recalibration (PCSR) method is able to significantly improve the online test-time domain adaptation performance by a large margin of up to 3.9\% in classification accuracy on the ImageNet-C dataset.
Training-Free Dual Hyperbolic Adapters for Better Cross-Modal Reasoning
Dec 09, 2025Recent research in Vision-Language Models (VLMs) has significantly advanced our capabilities in cross-modal reasoning. However, existing methods suffer from performance degradation with domain changes or require substantial computational resources for fine-tuning in new domains. To address this issue, we develop a new adaptation method for large vision-language models, called \textit{Training-free Dual Hyperbolic Adapters} (T-DHA). We characterize the vision-language relationship between semantic concepts, which typically has a hierarchical tree structure, in the hyperbolic space instead of the traditional Euclidean space. Hyperbolic spaces exhibit exponential volume growth with radius, unlike the polynomial growth in Euclidean space. We find that this unique property is particularly effective for embedding hierarchical data structures using the Poincaré ball model, achieving significantly improved representation and discrimination power. Coupled with negative learning, it provides more accurate and robust classifications with fewer feature dimensions. Our extensive experimental results on various datasets demonstrate that the T-DHA method significantly outperforms existing state-of-the-art methods in few-shot image recognition and domain generalization tasks.
Open-World Test-Time Adaptation with Hierarchical Feature Aggregation and Attention Affine
Nov 16, 2025Test-time adaptation (TTA) refers to adjusting the model during the testing phase to cope with changes in sample distribution and enhance the model's adaptability to new environments. In real-world scenarios, models often encounter samples from unseen (out-of-distribution, OOD) categories. Misclassifying these as known (in-distribution, ID) classes not only degrades predictive accuracy but can also impair the adaptation process, leading to further errors on subsequent ID samples. Many existing TTA methods suffer substantial performance drops under such conditions. To address this challenge, we propose a Hierarchical Ladder Network that extracts OOD features from class tokens aggregated across all Transformer layers. OOD detection performance is enhanced by combining the original model prediction with the output of the Hierarchical Ladder Network (HLN) via weighted probability fusion. To improve robustness under domain shift, we further introduce an Attention Affine Network (AAN) that adaptively refines the self-attention mechanism conditioned on the token information to better adapt to domain drift, thereby improving the classification performance of the model on datasets with domain shift. Additionally, a weighted entropy mechanism is employed to dynamically suppress the influence of low-confidence samples during adaptation. Experimental results on benchmark datasets show that our method significantly improves the performance on the most widely used classification datasets.
Generative Semantic Coding for Ultra-Low Bitrate Visual Communication and Analysis
Oct 31, 2025
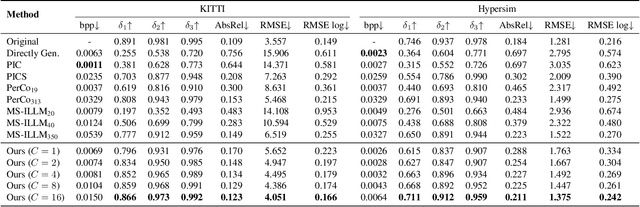

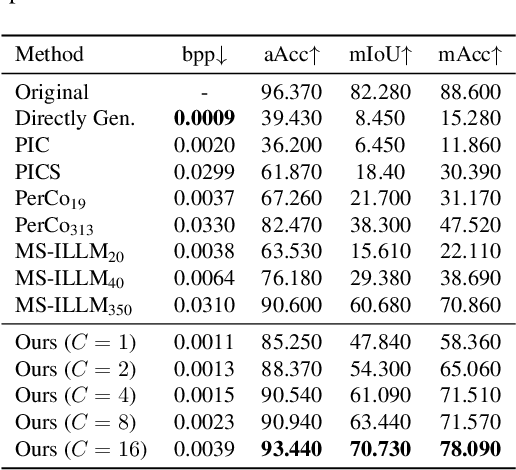
We consider the problem of ultra-low bit rate visual communication for remote vision analysis, human interactions and control in challenging scenarios with very low communication bandwidth, such as deep space exploration, battlefield intelligence, and robot navigation in complex environments. In this paper, we ask the following important question: can we accurately reconstruct the visual scene using only a very small portion of the bit rate in existing coding methods while not sacrificing the accuracy of vision analysis and performance of human interactions? Existing text-to-image generation models offer a new approach for ultra-low bitrate image description. However, they can only achieve a semantic-level approximation of the visual scene, which is far insufficient for the purpose of visual communication and remote vision analysis and human interactions. To address this important issue, we propose to seamlessly integrate image generation with deep image compression, using joint text and coding latent to guide the rectified flow models for precise generation of the visual scene. The semantic text description and coding latent are both encoded and transmitted to the decoder at a very small bit rate. Experimental results demonstrate that our method can achieve the same image reconstruction quality and vision analysis accuracy as existing methods while using much less bandwidth. The code will be released upon paper acceptance.
Understanding the Implicit User Intention via Reasoning with Large Language Model for Image Editing
Oct 31, 2025Existing image editing methods can handle simple editing instructions very well. To deal with complex editing instructions, they often need to jointly fine-tune the large language models (LLMs) and diffusion models (DMs), which involves very high computational complexity and training cost. To address this issue, we propose a new method, called \textbf{C}omplex \textbf{I}mage \textbf{E}diting via \textbf{L}LM \textbf{R}easoning (CIELR), which converts a complex user instruction into a set of simple and explicit editing actions, eliminating the need for jointly fine-tuning the large language models and diffusion models. Specifically, we first construct a structured semantic representation of the input image using foundation models. Then, we introduce an iterative update mechanism that can progressively refine this representation, obtaining a fine-grained visual representation of the image scene. This allows us to perform complex and flexible image editing tasks. Extensive experiments on the SmartEdit Reasoning Scenario Set show that our method surpasses the previous state-of-the-art by 9.955 dB in PSNR, indicating its superior preservation of regions that should remain consistent. Due to the limited number of samples of public datasets of complex image editing with reasoning, we construct a benchmark named CIEBench, containing 86 image samples, together with a metric specifically for reasoning-based image editing. CIELR also outperforms previous methods on this benchmark. The code and dataset are available at \href{https://github.com/Jia-shao/Reasoning-Editing}{https://github.com/Jia-shao/Reasoning-Editing}.
Runge-Kutta Approximation and Decoupled Attention for Rectified Flow Inversion and Semantic Editing
Sep 16, 2025Rectified flow (RF) models have recently demonstrated superior generative performance compared to DDIM-based diffusion models. However, in real-world applications, they suffer from two major challenges: (1) low inversion accuracy that hinders the consistency with the source image, and (2) entangled multimodal attention in diffusion transformers, which hinders precise attention control. To address the first challenge, we propose an efficient high-order inversion method for rectified flow models based on the Runge-Kutta solver of differential equations. To tackle the second challenge, we introduce Decoupled Diffusion Transformer Attention (DDTA), a novel mechanism that disentangles text and image attention inside the multimodal diffusion transformers, enabling more precise semantic control. Extensive experiments on image reconstruction and text-guided editing tasks demonstrate that our method achieves state-of-the-art performance in terms of fidelity and editability. Code is available at https://github.com/wmchen/RKSovler_DDTA.
Cross-Modal Few-Shot Learning with Second-Order Neural Ordinary Differential Equations
Dec 20, 2024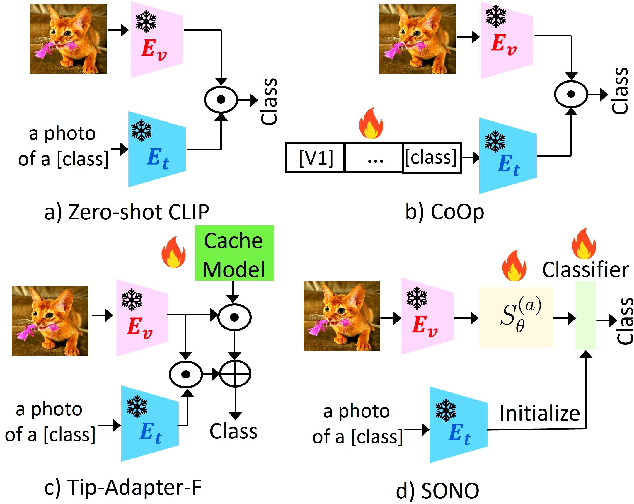
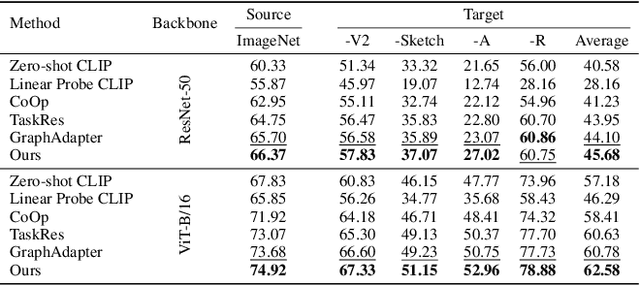
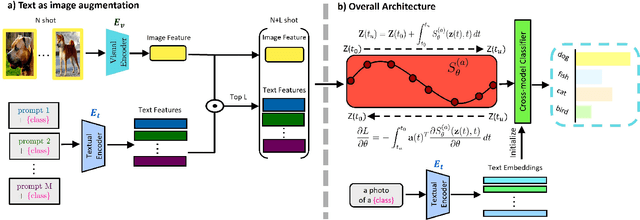
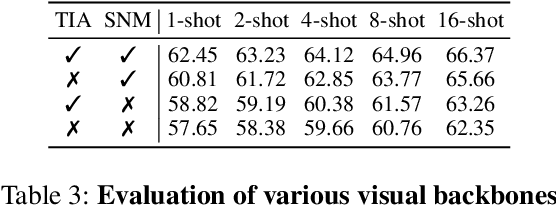
We introduce SONO, a novel method leveraging Second-Order Neural Ordinary Differential Equations (Second-Order NODEs) to enhance cross-modal few-shot learning. By employing a simple yet effective architecture consisting of a Second-Order NODEs model paired with a cross-modal classifier, SONO addresses the significant challenge of overfitting, which is common in few-shot scenarios due to limited training examples. Our second-order approach can approximate a broader class of functions, enhancing the model's expressive power and feature generalization capabilities. We initialize our cross-modal classifier with text embeddings derived from class-relevant prompts, streamlining training efficiency by avoiding the need for frequent text encoder processing. Additionally, we utilize text-based image augmentation, exploiting CLIP's robust image-text correlation to enrich training data significantly. Extensive experiments across multiple datasets demonstrate that SONO outperforms existing state-of-the-art methods in few-shot learning performance.