 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHebbian Learning with Global Direction
Jan 29, 2026Backpropagation algorithm has driven the remarkable success of deep neural networks, but its lack of biological plausibility and high computational costs have motivated the ongoing search for alternative training methods. Hebbian learning has attracted considerable interest as a biologically plausible alternative to backpropagation. Nevertheless, its exclusive reliance on local information, without consideration of global task objectives, fundamentally limits its scalability. Inspired by the biological synergy between neuromodulators and local plasticity, we introduce a novel model-agnostic Global-guided Hebbian Learning (GHL) framework, which seamlessly integrates local and global information to scale up across diverse networks and tasks. In specific, the local component employs Oja's rule with competitive learning to ensure stable and effective local updates. Meanwhile, the global component introduces a sign-based signal that guides the direction of local Hebbian plasticity updates. Extensive experiments demonstrate that our method consistently outperforms existing Hebbian approaches. Notably, on large-scale network and complex datasets like ImageNet, our framework achieves the competitive results and significantly narrows the gap with standard backpropagation.
MAR: Efficient Large Language Models via Module-aware Architecture Refinement
Jan 29, 2026Large Language Models (LLMs) excel across diverse domains but suffer from high energy costs due to quadratic attention and dense Feed-Forward Network (FFN) operations. To address these issues, we propose Module-aware Architecture Refinement (MAR), a two-stage framework that integrates State Space Models (SSMs) for linear-time sequence modeling and applies activation sparsification to reduce FFN costs. In addition, to mitigate low information density and temporal mismatch in integrating Spiking Neural Networks (SNNs) with SSMs, we design the Adaptive Ternary Multi-step Neuron (ATMN) and the Spike-aware Bidirectional Distillation Strategy (SBDS). Extensive experiments demonstrate that MAR effectively restores the performance of its dense counterpart under constrained resources while substantially reducing inference energy consumption. Furthermore, it outperforms efficient models of comparable or even larger scale, underscoring its potential for building efficient and practical LLMs.
Explicit Mutual Information Maximization for Self-Supervised Learning
Sep 11, 2024Recently, self-supervised learning (SSL) has been extensively studied. Theoretically, mutual information maximization (MIM) is an optimal criterion for SSL, with a strong theoretical foundation in information theory. However, it is difficult to directly apply MIM in SSL since the data distribution is not analytically available in applications. In practice, many existing methods can be viewed as approximate implementations of the MIM criterion. This work shows that, based on the invariance property of MI, explicit MI maximization can be applied to SSL under a generic distribution assumption, i.e., a relaxed condition of the data distribution. We further illustrate this by analyzing the generalized Gaussian distribution. Based on this result, we derive a loss function based on the MIM criterion using only second-order statistics. We implement the new loss for SSL and demonstrate its effectiveness via extensive experiments.
SpikingSSMs: Learning Long Sequences with Sparse and Parallel Spiking State Space Models
Aug 27, 2024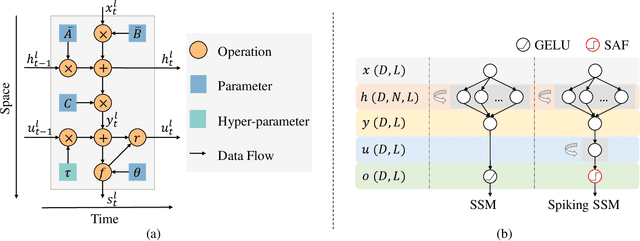
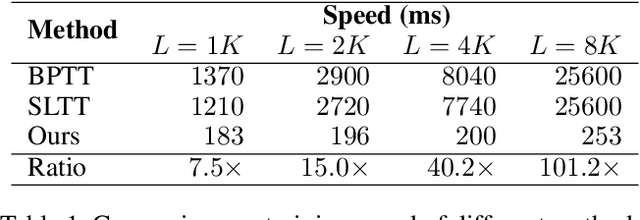
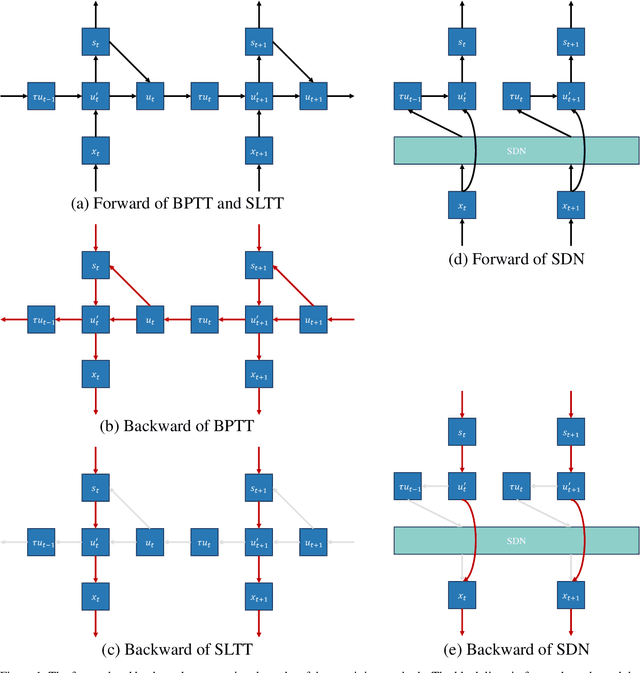
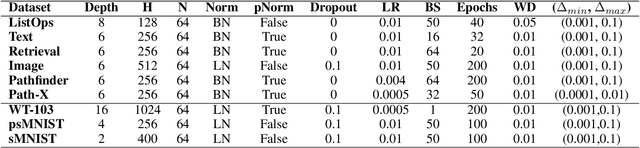
Known as low energy consumption networks, spiking neural networks (SNNs) have gained a lot of attention within the past decades. While SNNs are increasing competitive with artificial neural networks (ANNs) for vision tasks, they are rarely used for long sequence tasks, despite their intrinsic temporal dynamics. In this work, we develop spiking state space models (SpikingSSMs) for long sequence learning by leveraging on the sequence learning abilities of state space models (SSMs). Inspired by dendritic neuron structure, we hierarchically integrate neuronal dynamics with the original SSM block, meanwhile realizing sparse synaptic computation. Furthermore, to solve the conflict of event-driven neuronal dynamics with parallel computing, we propose a light-weight surrogate dynamic network which accurately predicts the after-reset membrane potential and compatible to learnable thresholds, enabling orders of acceleration in training speed compared with conventional iterative methods. On the long range arena benchmark task, SpikingSSM achieves competitive performance to state-of-the-art SSMs meanwhile realizing on average 90\% of network sparsity. On language modeling, our network significantly surpasses existing spiking large language models (spikingLLMs) on the WikiText-103 dataset with only a third of the model size, demonstrating its potential as backbone architecture for low computation cost LLMs.
BKDSNN: Enhancing the Performance of Learning-based Spiking Neural Networks Training with Blurred Knowledge Distillation
Jul 12, 2024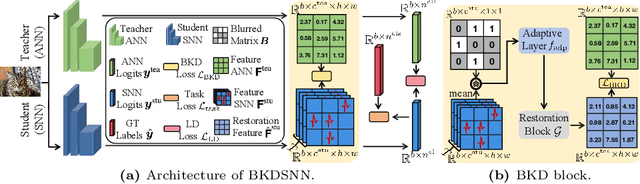

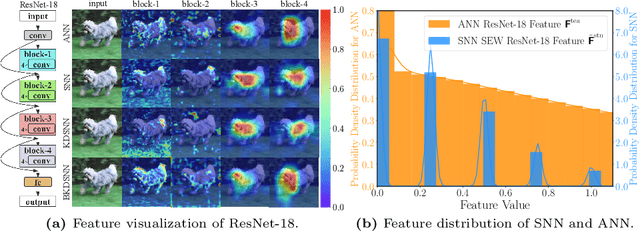
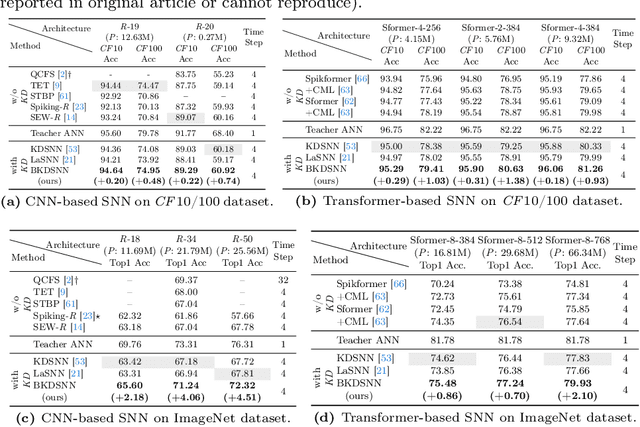
Spiking neural networks (SNNs), which mimic biological neural system to convey information via discrete spikes, are well known as brain-inspired models with excellent computing efficiency. By utilizing the surrogate gradient estimation for discrete spikes, learning-based SNN training methods that can achieve ultra-low inference latency (number of time-step) emerge recently. Nevertheless, due to the difficulty in deriving precise gradient estimation for discrete spikes using learning-based method, a distinct accuracy gap persists between SNN and its artificial neural networks (ANNs) counterpart. To address the aforementioned issue, we propose a blurred knowledge distillation (BKD) technique, which leverages random blurred SNN feature to restore and imitate the ANN feature. Note that, our BKD is applied upon the feature map right before the last layer of SNN, which can also mix with prior logits-based knowledge distillation for maximized accuracy boost. To our best knowledge, in the category of learning-based methods, our work achieves state-of-the-art performance for training SNNs on both static and neuromorphic datasets. On ImageNet dataset, BKDSNN outperforms prior best results by 4.51% and 0.93% with the network topology of CNN and Transformer respectively.
Learning Visual Conditioning Tokens to Correct Domain Shift for Fully Test-time Adaptation
Jun 27, 2024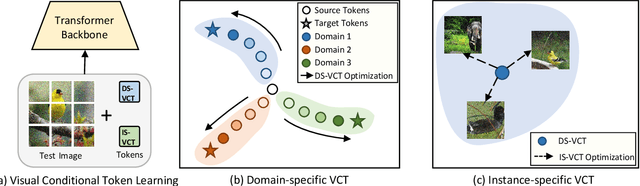
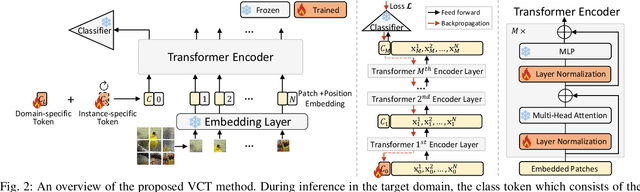
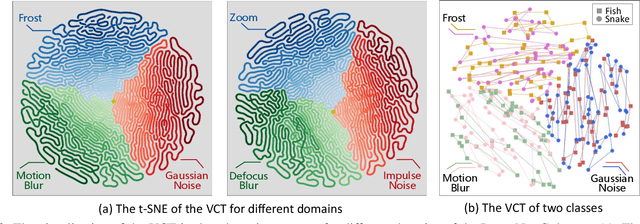
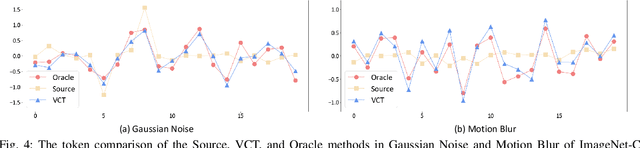
Fully test-time adaptation aims to adapt the network model based on sequential analysis of input samples during the inference stage to address the cross-domain performance degradation problem of deep neural networks. This work is based on the following interesting finding: in transformer-based image classification, the class token at the first transformer encoder layer can be learned to capture the domain-specific characteristics of target samples during test-time adaptation. This learned token, when combined with input image patch embeddings, is able to gradually remove the domain-specific information from the feature representations of input samples during the transformer encoding process, thereby significantly improving the test-time adaptation performance of the source model across different domains. We refer to this class token as visual conditioning token (VCT). To successfully learn the VCT, we propose a bi-level learning approach to capture the long-term variations of domain-specific characteristics while accommodating local variations of instance-specific characteristics. Experimental results on the benchmark datasets demonstrate that our proposed bi-level visual conditioning token learning method is able to achieve significantly improved test-time adaptation performance by up to 1.9%.
Evolutionary Spiking Neural Networks: A Survey
Jun 18, 2024Spiking neural networks (SNNs) are gaining increasing attention as potential computationally efficient alternatives to traditional artificial neural networks(ANNs). However, the unique information propagation mechanisms and the complexity of SNN neuron models pose challenges for adopting traditional methods developed for ANNs to SNNs. These challenges include both weight learning and architecture design. While surrogate gradient learning has shown some success in addressing the former challenge, the latter remains relatively unexplored. Recently, a novel paradigm utilizing evolutionary computation methods has emerged to tackle these challenges. This approach has resulted in the development of a variety of energy-efficient and high-performance SNNs across a wide range of machine learning benchmarks. In this paper, we present a survey of these works and initiate discussions on potential challenges ahead.
Benchmarking Neural Decoding Backbones towards Enhanced On-edge iBCI Applications
Jun 08, 2024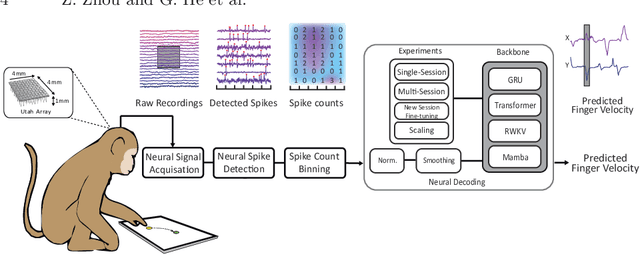
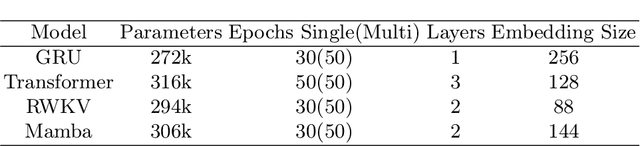
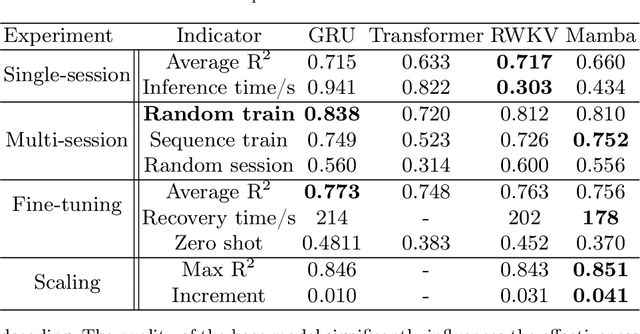
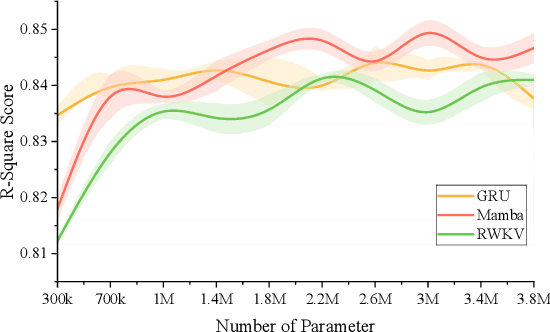
Traditional invasive Brain-Computer Interfaces (iBCIs) typically depend on neural decoding processes conducted on workstations within laboratory settings, which prevents their everyday usage. Implementing these decoding processes on edge devices, such as the wearables, introduces considerable challenges related to computational demands, processing speed, and maintaining accuracy. This study seeks to identify an optimal neural decoding backbone that boasts robust performance and swift inference capabilities suitable for edge deployment. We executed a series of neural decoding experiments involving nonhuman primates engaged in random reaching tasks, evaluating four prospective models, Gated Recurrent Unit (GRU), Transformer, Receptance Weighted Key Value (RWKV), and Selective State Space model (Mamba), across several metrics: single-session decoding, multi-session decoding, new session fine-tuning, inference speed, calibration speed, and scalability. The findings indicate that although the GRU model delivers sufficient accuracy, the RWKV and Mamba models are preferable due to their superior inference and calibration speeds. Additionally, RWKV and Mamba comply with the scaling law, demonstrating improved performance with larger data sets and increased model sizes, whereas GRU shows less pronounced scalability, and the Transformer model requires computational resources that scale prohibitively. This paper presents a thorough comparative analysis of the four models in various scenarios. The results are pivotal in pinpointing an optimal backbone that can handle increasing data volumes and is viable for edge implementation. This analysis provides essential insights for ongoing research and practical applications in the field.
SpikeZIP-TF: Conversion is All You Need for Transformer-based SNN
Jun 05, 2024



Spiking neural network (SNN) has attracted great attention due to its characteristic of high efficiency and accuracy. Currently, the ANN-to-SNN conversion methods can obtain ANN on-par accuracy SNN with ultra-low latency (8 time-steps) in CNN structure on computer vision (CV) tasks. However, as Transformer-based networks have achieved prevailing precision on both CV and natural language processing (NLP), the Transformer-based SNNs are still encounting the lower accuracy w.r.t the ANN counterparts. In this work, we introduce a novel ANN-to-SNN conversion method called SpikeZIP-TF, where ANN and SNN are exactly equivalent, thus incurring no accuracy degradation. SpikeZIP-TF achieves 83.82% accuracy on CV dataset (ImageNet) and 93.79% accuracy on NLP dataset (SST-2), which are higher than SOTA Transformer-based SNNs. The code is available in GitHub: https://github.com/Intelligent-Computing-Research-Group/SpikeZIP_transformer
When in Doubt, Think Slow: Iterative Reasoning with Latent Imagination
Feb 23, 2024



In an unfamiliar setting, a model-based reinforcement learning agent can be limited by the accuracy of its world model. In this work, we present a novel, training-free approach to improving the performance of such agents separately from planning and learning. We do so by applying iterative inference at decision-time, to fine-tune the inferred agent states based on the coherence of future state representations. Our approach achieves a consistent improvement in both reconstruction accuracy and task performance when applied to visual 3D navigation tasks. We go on to show that considering more future states further improves the performance of the agent in partially-observable environments, but not in a fully-observable one. Finally, we demonstrate that agents with less training pre-evaluation benefit most from our approach.