 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferences between Two Maximal Principal Strain Rate Calculation Schemes in Traumatic Brain Analysis with in-vivo and in-silico Datasets
Sep 12, 2024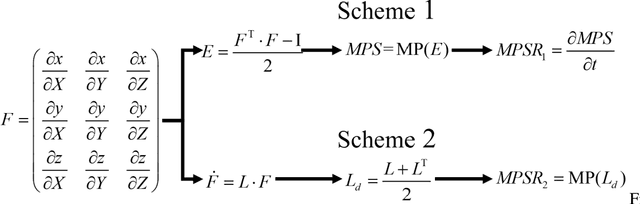
Brain deformation caused by a head impact leads to traumatic brain injury (TBI). The maximum principal strain (MPS) was used to measure the extent of brain deformation and predict injury, and the recent evidence has indicated that incorporating the maximum principal strain rate (MPSR) and the product of MPS and MPSR, denoted as MPSxSR, enhances the accuracy of TBI prediction. However, ambiguities have arisen about the calculation of MPSR. Two schemes have been utilized: one (MPSR1) is to use the time derivative of MPS, and another (MPSR2) is to use the first eigenvalue of the strain rate tensor. Both MPSR1 and MPSR2 have been applied in previous studies to predict TBI. To quantify the discrepancies between these two methodologies, we conducted a comparison of these two MPSR methodologies across nine in-vivo and in-silico head impact datasets and found that 95MPSR1 was 5.87% larger than 95MPSR2, and 95MPSxSR1 was 2.55% larger than 95MPSxSR2. Across every element in all head impacts, MPSR1 was 8.28% smaller than MPSR2, and MPSxSR1 was 8.11% smaller than MPSxSR2. Furthermore, logistic regression models were trained to predict TBI based on the MPSR (or MPSxSR), and no significant difference was observed in the predictability across different variables. The consequence of misuse of MPSR and MPSxSR thresholds (i.e. compare threshold of 95MPSR1 with value from 95MPSR2 to determine if the impact is injurious) was investigated, and the resulting false rates were found to be around 1%. The evidence suggested that these two methodologies were not significantly different in detecting TBI.
Benchmarking Neural Decoding Backbones towards Enhanced On-edge iBCI Applications
Jun 08, 2024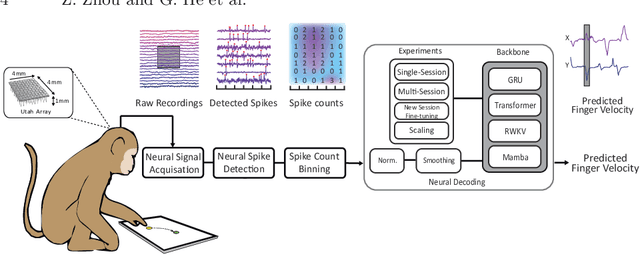
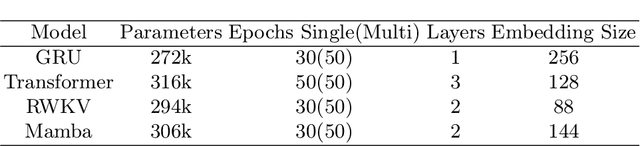
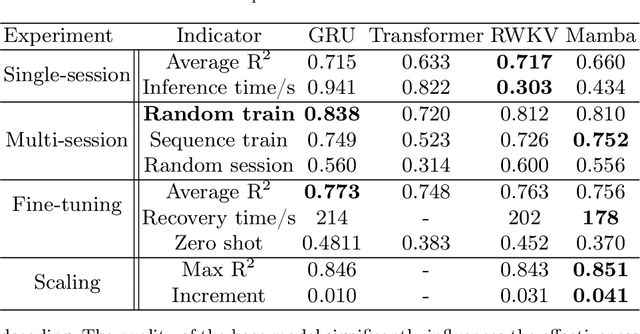
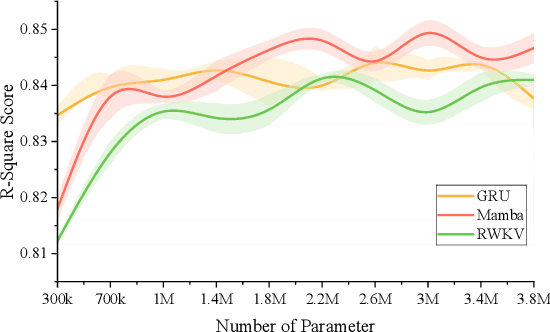
Traditional invasive Brain-Computer Interfaces (iBCIs) typically depend on neural decoding processes conducted on workstations within laboratory settings, which prevents their everyday usage. Implementing these decoding processes on edge devices, such as the wearables, introduces considerable challenges related to computational demands, processing speed, and maintaining accuracy. This study seeks to identify an optimal neural decoding backbone that boasts robust performance and swift inference capabilities suitable for edge deployment. We executed a series of neural decoding experiments involving nonhuman primates engaged in random reaching tasks, evaluating four prospective models, Gated Recurrent Unit (GRU), Transformer, Receptance Weighted Key Value (RWKV), and Selective State Space model (Mamba), across several metrics: single-session decoding, multi-session decoding, new session fine-tuning, inference speed, calibration speed, and scalability. The findings indicate that although the GRU model delivers sufficient accuracy, the RWKV and Mamba models are preferable due to their superior inference and calibration speeds. Additionally, RWKV and Mamba comply with the scaling law, demonstrating improved performance with larger data sets and increased model sizes, whereas GRU shows less pronounced scalability, and the Transformer model requires computational resources that scale prohibitively. This paper presents a thorough comparative analysis of the four models in various scenarios. The results are pivotal in pinpointing an optimal backbone that can handle increasing data volumes and is viable for edge implementation. This analysis provides essential insights for ongoing research and practical applications in the field.
Exposing Text-Image Inconsistency Using Diffusion Models
Apr 28, 2024



In the battle against widespread online misinformation, a growing problem is text-image inconsistency, where images are misleadingly paired with texts with different intent or meaning. Existing classification-based methods for text-image inconsistency can identify contextual inconsistencies but fail to provide explainable justifications for their decisions that humans can understand. Although more nuanced, human evaluation is impractical at scale and susceptible to errors. To address these limitations, this study introduces D-TIIL (Diffusion-based Text-Image Inconsistency Localization), which employs text-to-image diffusion models to localize semantic inconsistencies in text and image pairs. These models, trained on large-scale datasets act as ``omniscient" agents that filter out irrelevant information and incorporate background knowledge to identify inconsistencies. In addition, D-TIIL uses text embeddings and modified image regions to visualize these inconsistencies. To evaluate D-TIIL's efficacy, we introduce a new TIIL dataset containing 14K consistent and inconsistent text-image pairs. Unlike existing datasets, TIIL enables assessment at the level of individual words and image regions and is carefully designed to represent various inconsistencies. D-TIIL offers a scalable and evidence-based approach to identifying and localizing text-image inconsistency, providing a robust framework for future research combating misinformation.
Kinematic Analysis and Design of a Novel -DoF Parallel Robot with Fixed Actuators
Apr 24, 2023A novel kinematically redundant (6+3)-DoF parallel robot is presented in this paper. Three identical 3-DoF RU/2-RUS legs are attached to a configurable platform through spherical joints. With the selected leg mechanism, the motors are mounted at the base, reducing the reflected inertia. The robot is intended to be actuated with direct-drive motors in order to perform intuitive physical human-robot interaction. The design of the leg mechanism maximizes the workspace in which the end-effector of the leg can have a 2g acceleration in all directions. All singularities of the leg mechanism are identified under a simplifying assumption. A CAD model of the (6+3)-DoF robot is presented in order to illustrate the preliminary design of the robot.
AutoSplice: A Text-prompt Manipulated Image Dataset for Media Forensics
Apr 14, 2023



Recent advancements in language-image models have led to the development of highly realistic images that can be generated from textual descriptions. However, the increased visual quality of these generated images poses a potential threat to the field of media forensics. This paper aims to investigate the level of challenge that language-image generation models pose to media forensics. To achieve this, we propose a new approach that leverages the DALL-E2 language-image model to automatically generate and splice masked regions guided by a text prompt. To ensure the creation of realistic manipulations, we have designed an annotation platform with human checking to verify reasonable text prompts. This approach has resulted in the creation of a new image dataset called AutoSplice, containing 5,894 manipulated and authentic images. Specifically, we have generated a total of 3,621 images by locally or globally manipulating real-world image-caption pairs, which we believe will provide a valuable resource for developing generalized detection methods in this area. The dataset is evaluated under two media forensic tasks: forgery detection and localization. Our extensive experiments show that most media forensic models struggle to detect the AutoSplice dataset as an unseen manipulation. However, when fine-tuned models are used, they exhibit improved performance in both tasks.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
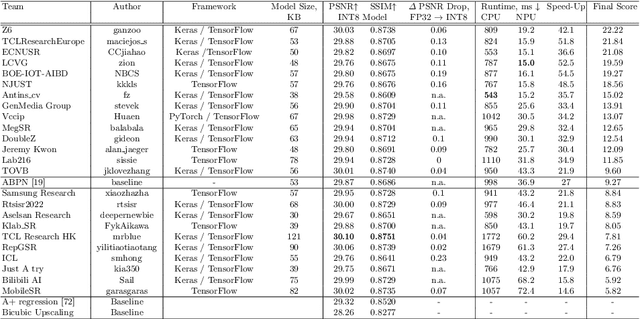
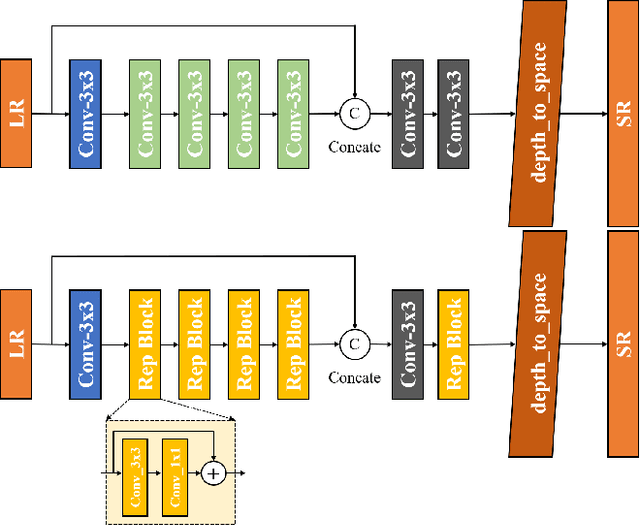
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
RC-Struct: A Structure-based Neural Network Approach for MIMO-OFDM Detection
Oct 03, 2021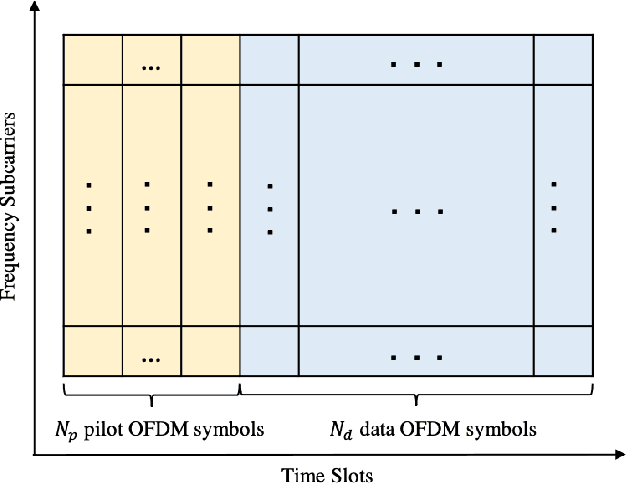
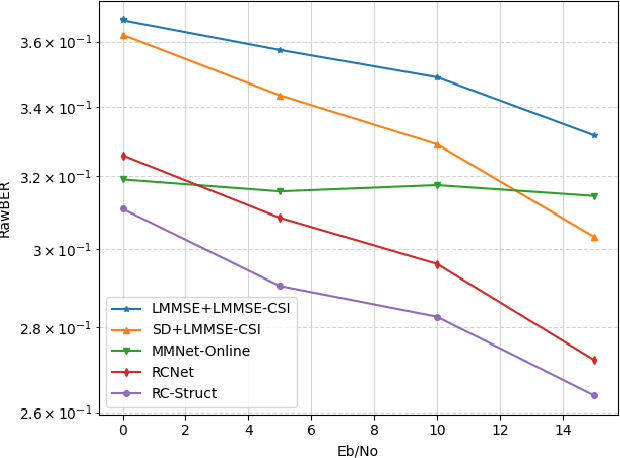
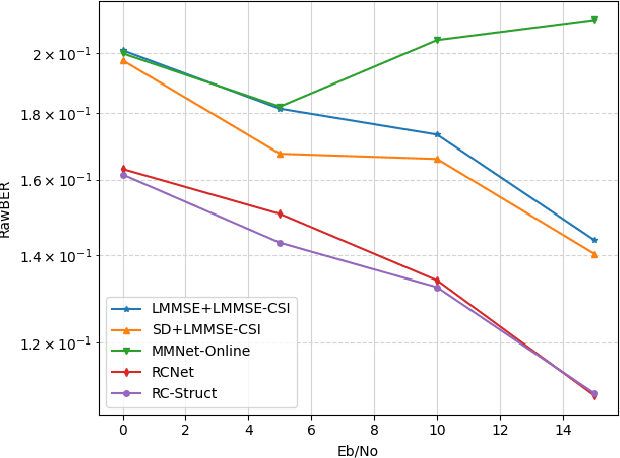
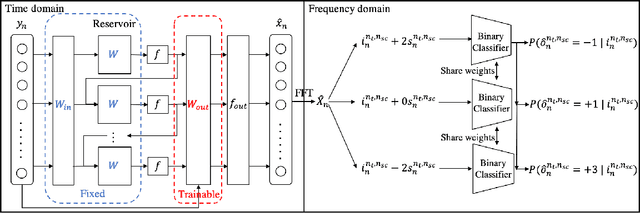
In this paper, we introduce a structure-based neural network architecture, namely RC-Struct, for MIMO-OFDM symbol detection. The RC-Struct exploits the temporal structure of the MIMO-OFDM signals through reservoir computing (RC). A binary classifier leverages the repetitive constellation structure in the system to perform multi-class detection. The incorporation of RC allows the RC-Struct to be learned in a purely online fashion with extremely limited pilot symbols in each OFDM subframe. The binary classifier enables the efficient utilization of the precious online training symbols and allows an easy extension to high-order modulations without a substantial increase in complexity. Experiments show that the introduced RC-Struct outperforms both the conventional model-based symbol detection approaches and the state-of-the-art learning-based strategies in terms of bit error rate (BER). The advantages of RC-Struct over existing methods become more significant when rank and link adaptation are adopted. The introduced RC-Struct sheds light on combining communication domain knowledge and learning-based receive processing for 5G and 5G Beyond.
Learning to Equalize OTFS
Jul 17, 2021

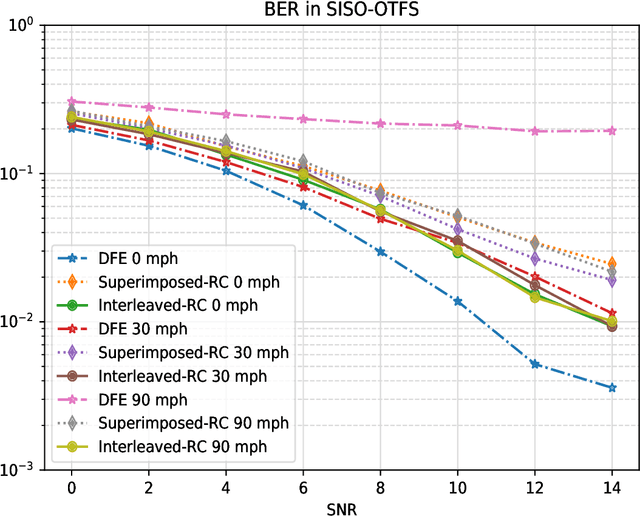
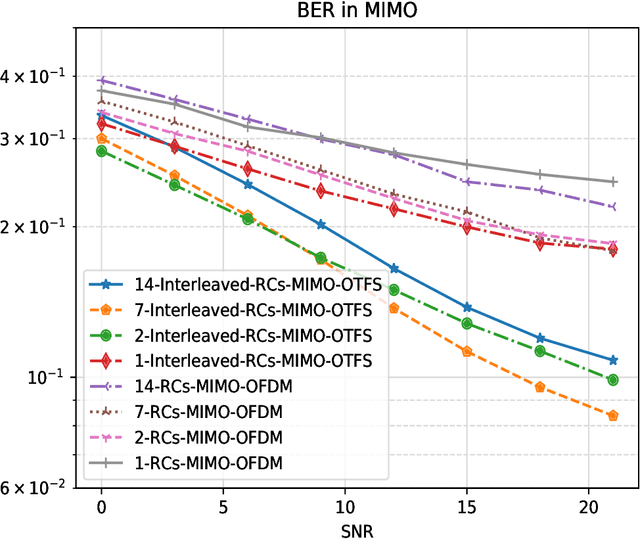
Orthogonal Time Frequency Space (OTFS) is a novel framework that processes modulation symbols via a time-independent channel characterized by the delay-Doppler domain. The conventional waveform, orthogonal frequency division multiplexing (OFDM), requires tracking frequency selective fading channels over the time, whereas OTFS benefits from full time-frequency diversity by leveraging appropriate equalization techniques. In this paper, we consider a neural network-based supervised learning framework for OTFS equalization. Learning of the introduced neural network is conducted in each OTFS frame fulfilling an online learning framework: the training and testing datasets are within the same OTFS-frame over the air. Utilizing reservoir computing, a special recurrent neural network, the resulting one-shot online learning is sufficiently flexible to cope with channel variations among different OTFS frames (e.g., due to the link/rank adaptation and user scheduling in cellular networks). The proposed method does not require explicit channel state information (CSI) and simulation results demonstrate a lower bit error rate (BER) than conventional equalization methods in the low signal-to-noise (SNR) regime under large Doppler spreads. When compared with its neural network-based counterparts for OFDM, the introduced approach for OTFS will lead to a better tradeoff between the processing complexity and the equalization performance.
Federated Dynamic Spectrum Access
Jun 28, 2021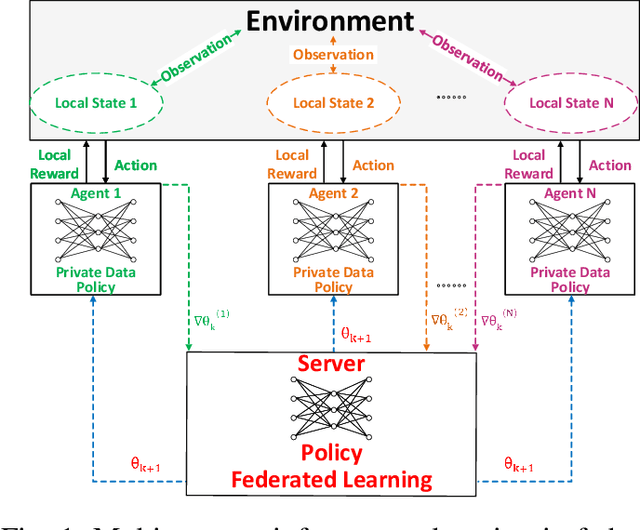
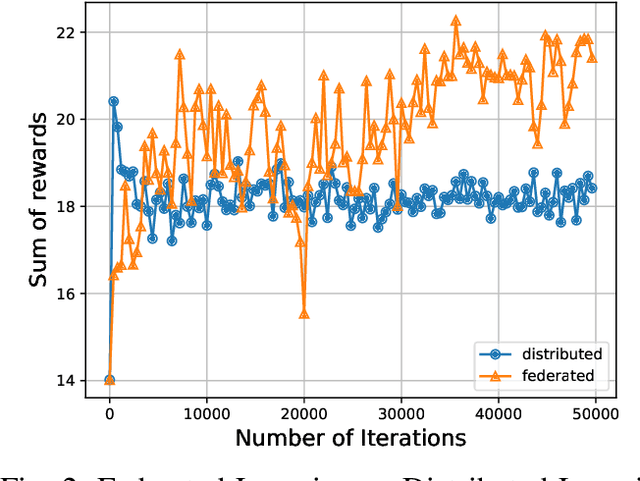
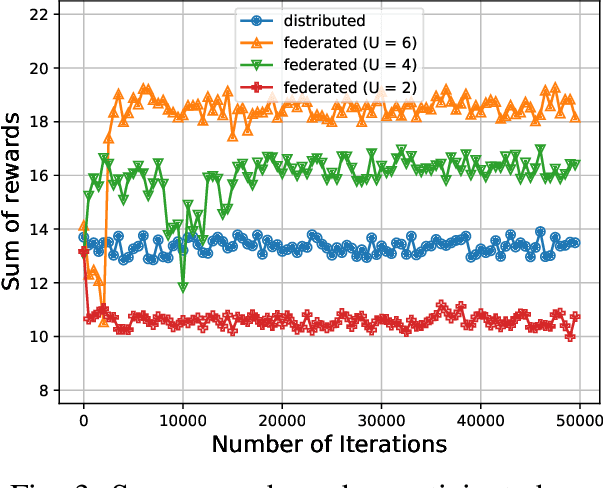
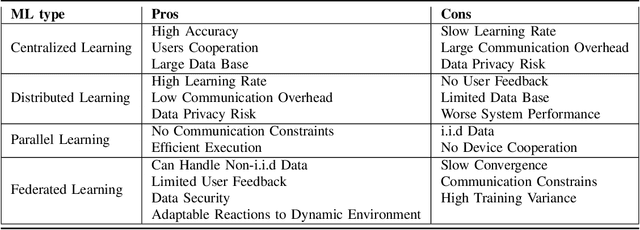
Due to the growing volume of data traffic produced by the surge of Internet of Things (IoT) devices, the demand for radio spectrum resources is approaching their limitation defined by Federal Communications Commission (FCC). To this end, Dynamic Spectrum Access (DSA) is considered as a promising technology to handle this spectrum scarcity. However, standard DSA techniques often rely on analytical modeling wireless networks, making its application intractable in under-measured network environments. Therefore, utilizing neural networks to approximate the network dynamics is an alternative approach. In this article, we introduce a Federated Learning (FL) based framework for the task of DSA, where FL is a distributive machine learning framework that can reserve the privacy of network terminals under heterogeneous data distributions. We discuss the opportunities, challenges, and opening problems of this framework. To evaluate its feasibility, we implement a Multi-Agent Reinforcement Learning (MARL)-based FL as a realization associated with its initial evaluation results.
Classification of head impacts based on the spectral density of measurable kinematics
Apr 19, 2021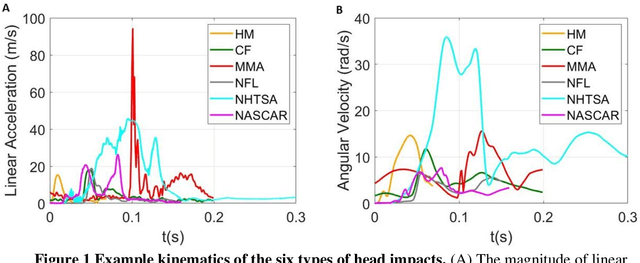
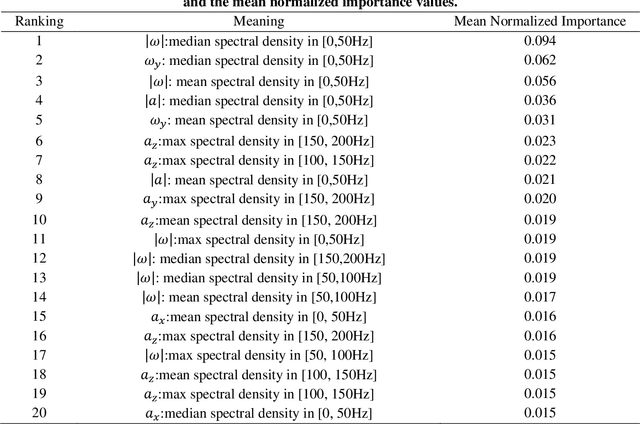
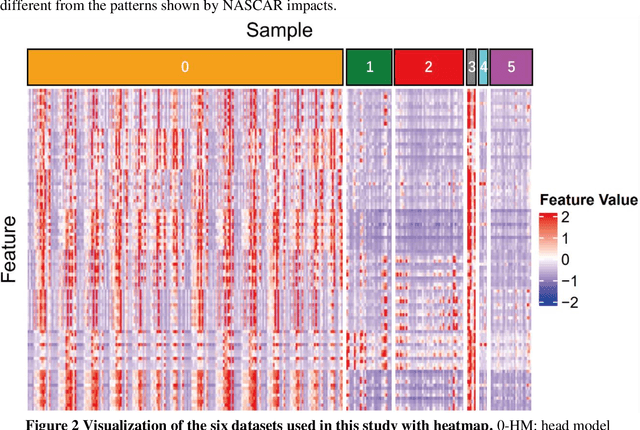
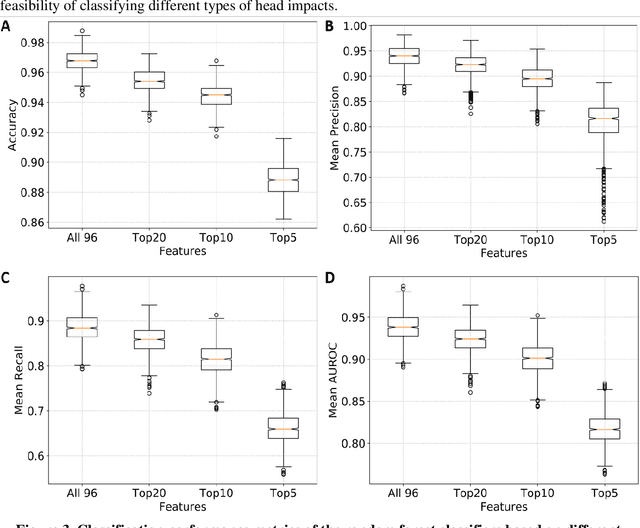
Traumatic brain injury can be caused by head impacts, but many brain injury risk estimation models are less accurate across the variety of impacts that patients may undergo. In this study, we investigated the spectral characteristics of different head impact types with kinematics classification. Data was analyzed from 3262 head impacts from head model simulations, on-field data from American football and mixed martial arts (MMA) using our instrumented mouthguard, and publicly available car crash data. A random forest classifier with spectral densities of linear acceleration and angular velocity was built to classify different types of head impacts (e.g., football, MMA), reaching a median accuracy of 96% over 1000 random partitions of training and test sets. Furthermore, to test the classifier on data from different measurement devices, another 271 lab-reconstructed impacts were obtained from 5 other instrumented mouthguards with the classifier reaching over 96% accuracy from these devices. The most important features in classification included both low-frequency and high-frequency features, both linear acceleration features and angular velocity features. It was found that different head impact types had different distributions of spectral densities in low-frequency and high-frequency ranges (e.g., the spectral densities of MMA impacts were higher in high-frequency range than in the low-frequency range). Finally, with head impact classification, type-specific, nearest-neighbor regression models were built for 95th percentile maximum principal strain, 95th percentile maximum principal strain in corpus callosum, and cumulative strain damage (15th percentile). This showed a generally higher R^2-value than baseline models without classification.