 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRL meets DSA Networks: Convergence Analysis and Its Application to System Design
May 18, 2023



In dynamic spectrum access (DSA) networks, secondary users (SUs) need to opportunistically access primary users' (PUs) radio spectrum without causing significant interference. Since the interaction between the SU and the PU systems are limited, deep reinforcement learning (DRL) has been introduced to help SUs to conduct spectrum access. Specifically, deep recurrent Q network (DRQN) has been utilized in DSA networks for SUs to aggregate the information from the recent experiences to make spectrum access decisions. DRQN is notorious for its sample efficiency in the sense that it needs a rather large number of training data samples to tune its parameters which is a computationally demanding task. In our recent work, deep echo state network (DEQN) has been introduced to DSA networks to address the sample efficiency issue of DRQN. In this paper, we analytically show that DEQN comparatively requires less amount of training samples than DRQN to converge to the best policy. Furthermore, we introduce a method to determine the right hyperparameters for the DEQN providing system design guidance for DEQN-based DSA networks. Extensive performance evaluation confirms that DEQN-based DSA strategy is the superior choice with regard to computational power while outperforming DRQN-based DSA strategies.
Federated Dynamic Spectrum Access
Jun 28, 2021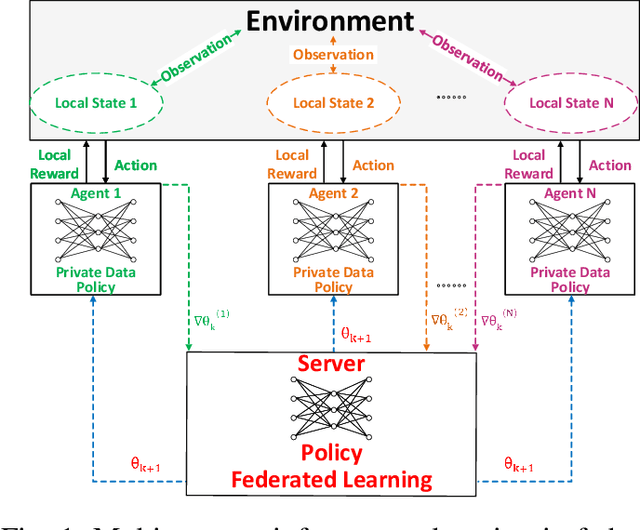
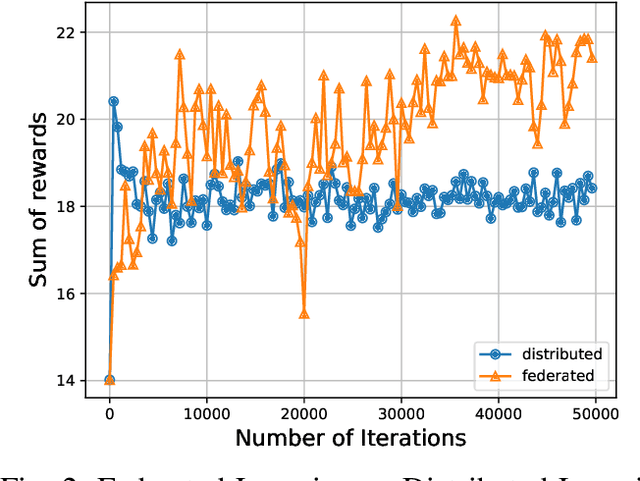
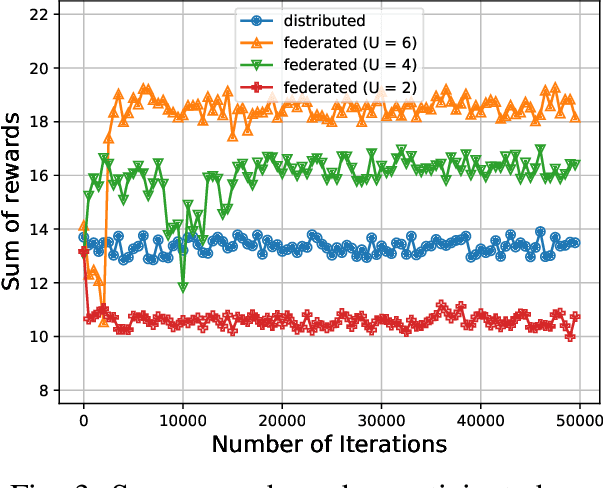
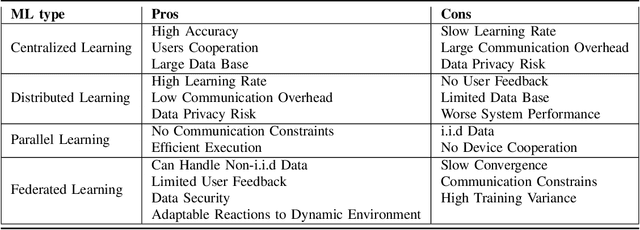
Due to the growing volume of data traffic produced by the surge of Internet of Things (IoT) devices, the demand for radio spectrum resources is approaching their limitation defined by Federal Communications Commission (FCC). To this end, Dynamic Spectrum Access (DSA) is considered as a promising technology to handle this spectrum scarcity. However, standard DSA techniques often rely on analytical modeling wireless networks, making its application intractable in under-measured network environments. Therefore, utilizing neural networks to approximate the network dynamics is an alternative approach. In this article, we introduce a Federated Learning (FL) based framework for the task of DSA, where FL is a distributive machine learning framework that can reserve the privacy of network terminals under heterogeneous data distributions. We discuss the opportunities, challenges, and opening problems of this framework. To evaluate its feasibility, we implement a Multi-Agent Reinforcement Learning (MARL)-based FL as a realization associated with its initial evaluation results.
Deep Echo State Q-Network and Its Application in Dynamic Spectrum Sharing for 5G and Beyond
Oct 12, 2020


Deep reinforcement learning (DRL) has been shown to be successful in many application domains. Combining recurrent neural networks (RNNs) and DRL further enables DRL to be applicable in non-Markovian environments by capturing temporal information. However, training of both DRL and RNNs is known to be challenging requiring a large amount of training data to achieve convergence. In many targeted applications, such as those used in the fifth generation (5G) cellular communication, the environment is highly dynamic while the available training data is very limited. Therefore, it is extremely important to develop DRL strategies that are capable of capturing the temporal correlation of the dynamic environment requiring limited training overhead. In this paper, we introduce the deep echo state Q-network (DEQN) that can adapt to the highly dynamic environment in a short period of time with limited training data. We evaluate the performance of the introduced DEQN method under the dynamic spectrum sharing (DSS) scenario, which is a promising technology in 5G and future 6G networks to increase the spectrum utilization. Compared to conventional spectrum management policy that grants a fixed spectrum band to a single system for exclusive access, DSS allows the secondary system to share the spectrum with the primary system. Our work sheds light on the application of an efficient DRL framework in highly dynamic environments with limited available training data.
Learn to Demodulate: MIMO-OFDM Symbol Detection through Downlink Pilots
Jun 25, 2019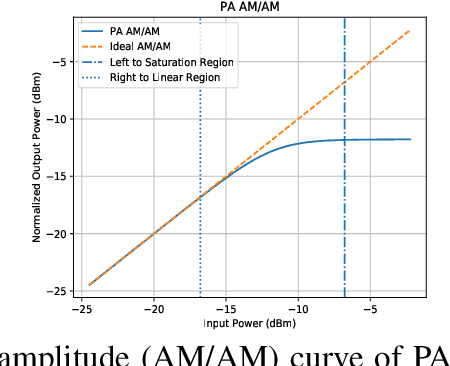
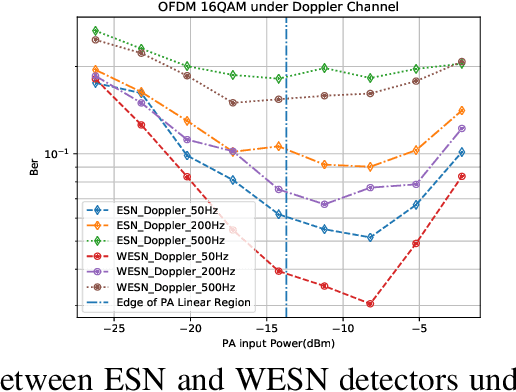
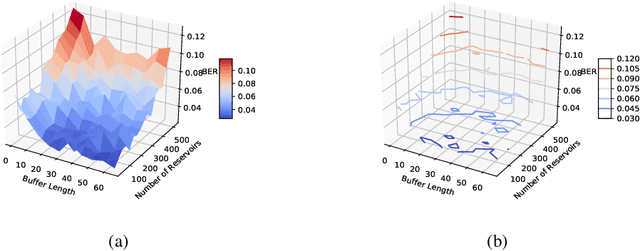
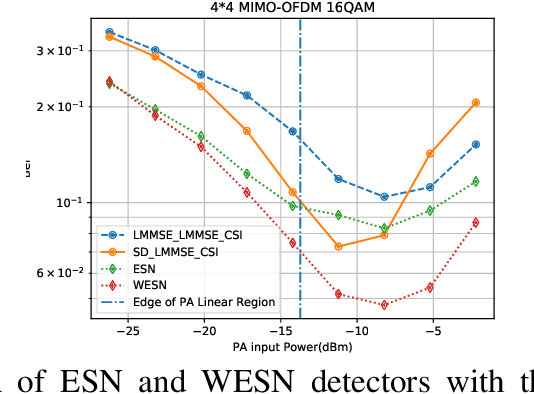
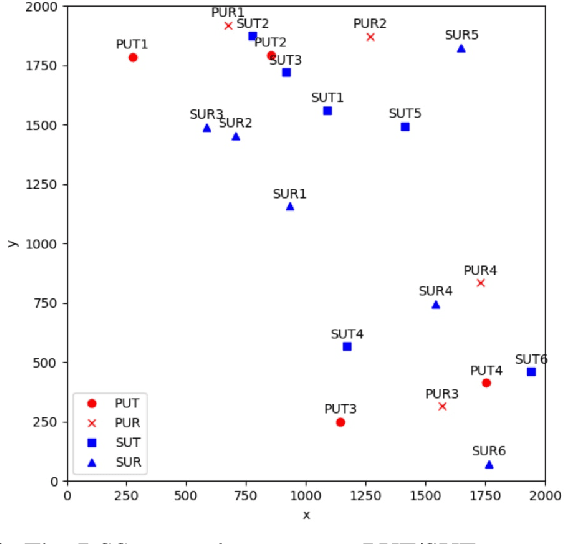
Reservoir computing (RC) is a special neural network which consists of a fixed high dimensional feature mapping and trained readout weights. In this paper, we consider a new RC structure for MIMO-OFDM symbol detection, namely windowed echo state network (WESN). It is introduced by adding buffers in input layers which brings an enhanced short-term memory (STM) of the underlying neural network through our theoretical proof. A unified training framework is developed for the WESN MIMO-OFDM symbol detector using both comb and scattered pilot patterns, where the utilized pilots are compatible with the structure adopted in 3GPP LTE/LTE-Advanced systems. Complexity analysis reveals the advantages of the WESN based symbol detector over the state-of-the-art symbol detectors such as the linear the minimum mean square error (LMMSE) detection and the sphere decoder when the system is employed with a large number of OFDM sub-carriers. Numerical evaluations corroborate that the improvement of the STM introduced by the WESN can significantly improve the symbol detection performance as well as effectively mitigate model mismatch effects as opposed to existing methods.
Distributive Dynamic Spectrum Access through Deep Reinforcement Learning: A Reservoir Computing Based Approach
Oct 28, 2018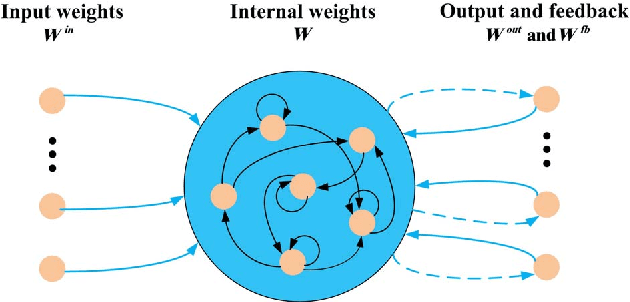
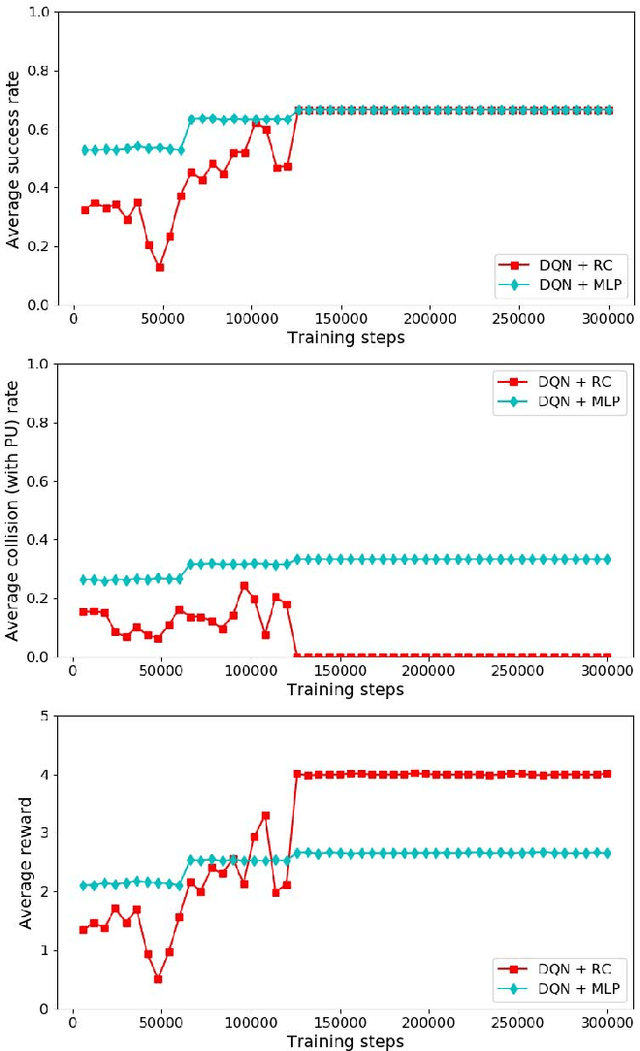

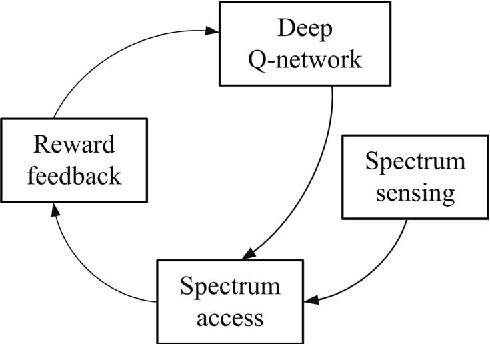
Dynamic spectrum access (DSA) is regarded as an effective and efficient technology to share radio spectrum among different networks. As a secondary user (SU), a DSA device will face two critical problems: avoiding causing harmful interference to primary users (PUs), and conducting effective interference coordination with other secondary users. These two problems become even more challenging for a distributed DSA network where there is no centralized controllers for SUs. In this paper, we investigate communication strategies of a distributive DSA network under the presence of spectrum sensing errors. To be specific, we apply the powerful machine learning tool, deep reinforcement learning (DRL), for SUs to learn "appropriate" spectrum access strategies in a distributed fashion assuming NO knowledge of the underlying system statistics. Furthermore, a special type of recurrent neural network (RNN), called the reservoir computing (RC), is utilized to realize DRL by taking advantage of the underlying temporal correlation of the DSA network. Using the introduced machine learning-based strategy, SUs could make spectrum access decisions distributedly relying only on their own current and past spectrum sensing outcomes. Through extensive experiments, our results suggest that the RC-based spectrum access strategy can help the SU to significantly reduce the chances of collision with PUs and other SUs. We also show that our scheme outperforms the myopic method which assumes the knowledge of system statistics, and converges faster than the Q-learning method when the number of channels is large.