 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAT: Task-Adaptive Transformer for All-in-One Medical Image Restoration
Dec 16, 2025Medical image restoration (MedIR) aims to recover high-quality medical images from their low-quality counterparts. Recent advancements in MedIR have focused on All-in-One models capable of simultaneously addressing multiple different MedIR tasks. However, due to significant differences in both modality and degradation types, using a shared model for these diverse tasks requires careful consideration of two critical inter-task relationships: task interference, which occurs when conflicting gradient update directions arise across tasks on the same parameter, and task imbalance, which refers to uneven optimization caused by varying learning difficulties inherent to each task. To address these challenges, we propose a task-adaptive Transformer (TAT), a novel framework that dynamically adapts to different tasks through two key innovations. First, a task-adaptive weight generation strategy is introduced to mitigate task interference by generating task-specific weight parameters for each task, thereby eliminating potential gradient conflicts on shared weight parameters. Second, a task-adaptive loss balancing strategy is introduced to dynamically adjust loss weights based on task-specific learning difficulties, preventing task domination or undertraining. Extensive experiments demonstrate that our proposed TAT achieves state-of-the-art performance in three MedIR tasks--PET synthesis, CT denoising, and MRI super-resolution--both in task-specific and All-in-One settings. Code is available at https://github.com/Yaziwel/TAT.
STEP Planner: Constructing cross-hierarchical subgoal tree as an embodied long-horizon task planner
Jun 26, 2025The ability to perform reliable long-horizon task planning is crucial for deploying robots in real-world environments. However, directly employing Large Language Models (LLMs) as action sequence generators often results in low success rates due to their limited reasoning ability for long-horizon embodied tasks. In the STEP framework, we construct a subgoal tree through a pair of closed-loop models: a subgoal decomposition model and a leaf node termination model. Within this framework, we develop a hierarchical tree structure that spans from coarse to fine resolutions. The subgoal decomposition model leverages a foundation LLM to break down complex goals into manageable subgoals, thereby spanning the subgoal tree. The leaf node termination model provides real-time feedback based on environmental states, determining when to terminate the tree spanning and ensuring each leaf node can be directly converted into a primitive action. Experiments conducted in both the VirtualHome WAH-NL benchmark and on real robots demonstrate that STEP achieves long-horizon embodied task completion with success rates up to 34% (WAH-NL) and 25% (real robot) outperforming SOTA methods.
A Plug-and-Play Learning-based IMU Bias Factor for Robust Visual-Inertial Odometry
Mar 16, 2025



The bias of low-cost Inertial Measurement Units (IMU) is a critical factor affecting the performance of Visual-Inertial Odometry (VIO). In particular, when visual tracking encounters errors, the optimized bias results may deviate significantly from the true values, adversely impacting the system's stability and localization precision. In this paper, we propose a novel plug-and-play framework featuring the Inertial Prior Network (IPNet), which is designed to accurately estimate IMU bias. Recognizing the substantial impact of initial bias errors in low-cost inertial devices on system performance, our network directly leverages raw IMU data to estimate the mean bias, eliminating the dependency on historical estimates in traditional recursive predictions and effectively preventing error propagation. Furthermore, we introduce an iterative approach to calculate the mean value of the bias for network training, addressing the lack of bias labels in many visual-inertial datasets. The framework is evaluated on two public datasets and one self-collected dataset. Extensive experiments demonstrate that our method significantly enhances both localization precision and robustness, with the ATE-RMSE metric improving on average by 46\%. The source code and video will be available at \textcolor{red}{https://github.com/yiyscut/VIO-IPNet.git}.
All-In-One Medical Image Restoration via Task-Adaptive Routing
May 30, 2024



Although single-task medical image restoration (MedIR) has witnessed remarkable success, the limited generalizability of these methods poses a substantial obstacle to wider application. In this paper, we focus on the task of all-in-one medical image restoration, aiming to address multiple distinct MedIR tasks with a single universal model. Nonetheless, due to significant differences between different MedIR tasks, training a universal model often encounters task interference issues, where different tasks with shared parameters may conflict with each other in the gradient update direction. This task interference leads to deviation of the model update direction from the optimal path, thereby affecting the model's performance. To tackle this issue, we propose a task-adaptive routing strategy, allowing conflicting tasks to select different network paths in spatial and channel dimensions, thereby mitigating task interference. Experimental results demonstrate that our proposed \textbf{A}ll-in-one \textbf{M}edical \textbf{I}mage \textbf{R}estoration (\textbf{AMIR}) network achieves state-of-the-art performance in three MedIR tasks: MRI super-resolution, CT denoising, and PET synthesis, both in single-task and all-in-one settings. The code and data will be available at \href{https://github.com/Yaziwel/All-In-One-Medical-Image-Restoration-via-Task-Adaptive-Routing.git}{https://github.com/Yaziwel/AMIR}.
Improving Drumming Robot Via Attention Transformer Network
Oct 04, 2023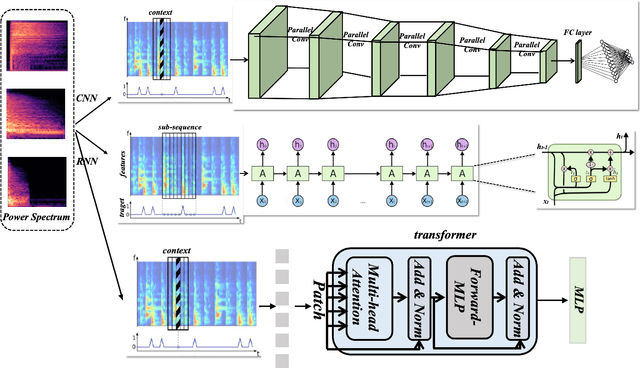

Robotic technology has been widely used in nowadays society, which has made great progress in various fields such as agriculture, manufacturing and entertainment. In this paper, we focus on the topic of drumming robots in entertainment. To this end, we introduce an improving drumming robot that can automatically complete music transcription based on the popular vision transformer network based on the attention mechanism. Equipped with the attention transformer network, our method can efficiently handle the sequential audio embedding input and model their global long-range dependencies. Massive experimental results demonstrate that the improving algorithm can help the drumming robot promote drum classification performance, which can also help the robot to enjoy a variety of smart applications and services.
Analogical Inference Enhanced Knowledge Graph Embedding
Jan 03, 2023



Knowledge graph embedding (KGE), which maps entities and relations in a knowledge graph into continuous vector spaces, has achieved great success in predicting missing links in knowledge graphs. However, knowledge graphs often contain incomplete triples that are difficult to inductively infer by KGEs. To address this challenge, we resort to analogical inference and propose a novel and general self-supervised framework AnKGE to enhance KGE models with analogical inference capability. We propose an analogical object retriever that retrieves appropriate analogical objects from entity-level, relation-level, and triple-level. And in AnKGE, we train an analogy function for each level of analogical inference with the original element embedding from a well-trained KGE model as input, which outputs the analogical object embedding. In order to combine inductive inference capability from the original KGE model and analogical inference capability enhanced by AnKGE, we interpolate the analogy score with the base model score and introduce the adaptive weights in the score function for prediction. Through extensive experiments on FB15k-237 and WN18RR datasets, we show that AnKGE achieves competitive results on link prediction task and well performs analogical inference.
Graph Classification via Discriminative Edge Feature Learning
Oct 05, 2022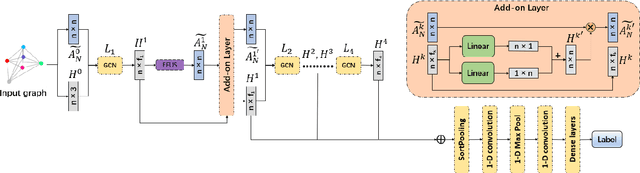
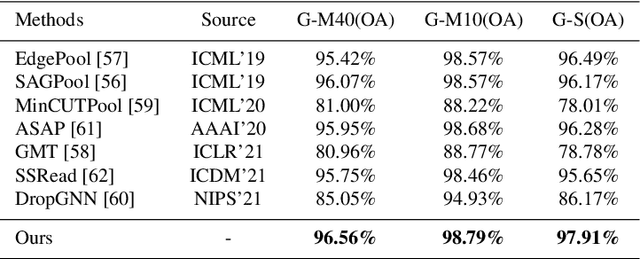
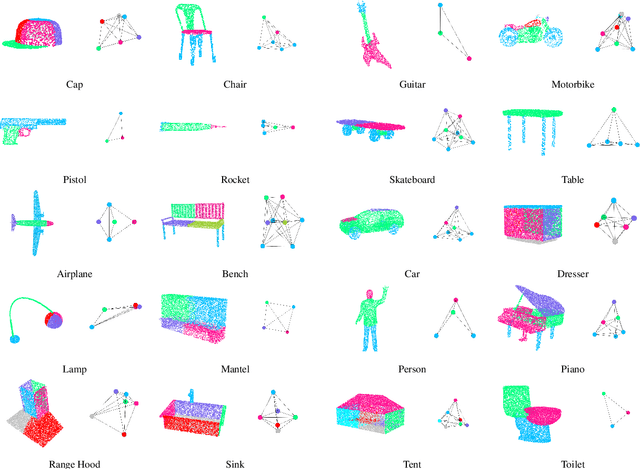
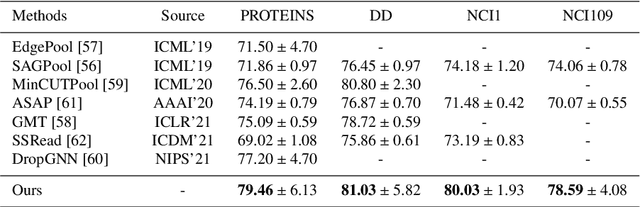
Spectral graph convolutional neural networks (GCNNs) have been producing encouraging results in graph classification tasks. However, most spectral GCNNs utilize fixed graphs when aggregating node features, while omitting edge feature learning and failing to get an optimal graph structure. Moreover, many existing graph datasets do not provide initialized edge features, further restraining the ability of learning edge features via spectral GCNNs. In this paper, we try to address this issue by designing an edge feature scheme and an add-on layer between every two stacked graph convolution layers in GCNN. Both are lightweight while effective in filling the gap between edge feature learning and performance enhancement of graph classification. The edge feature scheme makes edge features adapt to node representations at different graph convolution layers. The add-on layers help adjust the edge features to an optimal graph structure. To test the effectiveness of our method, we take Euclidean positions as initial node features and extract graphs with semantic information from point cloud objects. The node features of our extracted graphs are more scalable for edge feature learning than most existing graph datasets (in one-hot encoded label format). Three new graph datasets are constructed based on ModelNet40, ModelNet10 and ShapeNet Part datasets. Experimental results show that our method outperforms state-of-the-art graph classification methods on the new datasets by reaching 96.56% overall accuracy on Graph-ModelNet40, 98.79% on Graph-ModelNet10 and 97.91% on Graph-ShapeNet Part. The constructed graph datasets will be released to the community.
Making Intelligent Reflecting Surfaces More Intelligent: A Roadmap Through Reservoir Computing
Feb 06, 2021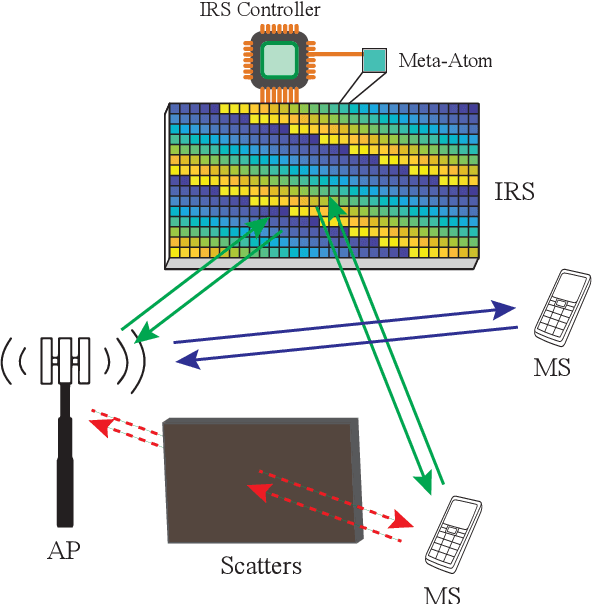
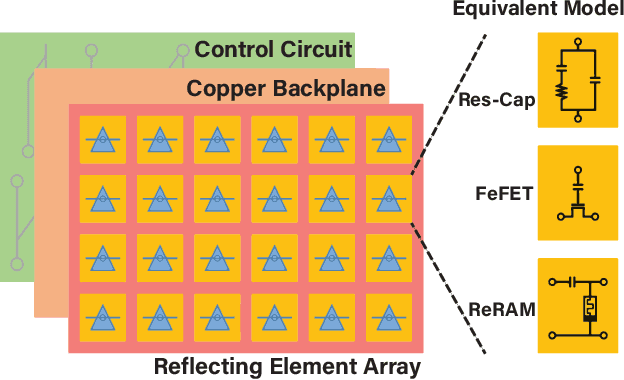
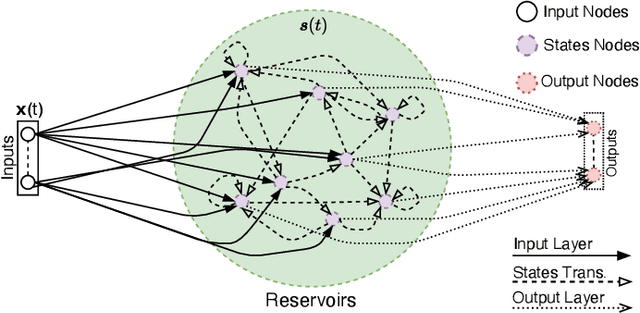
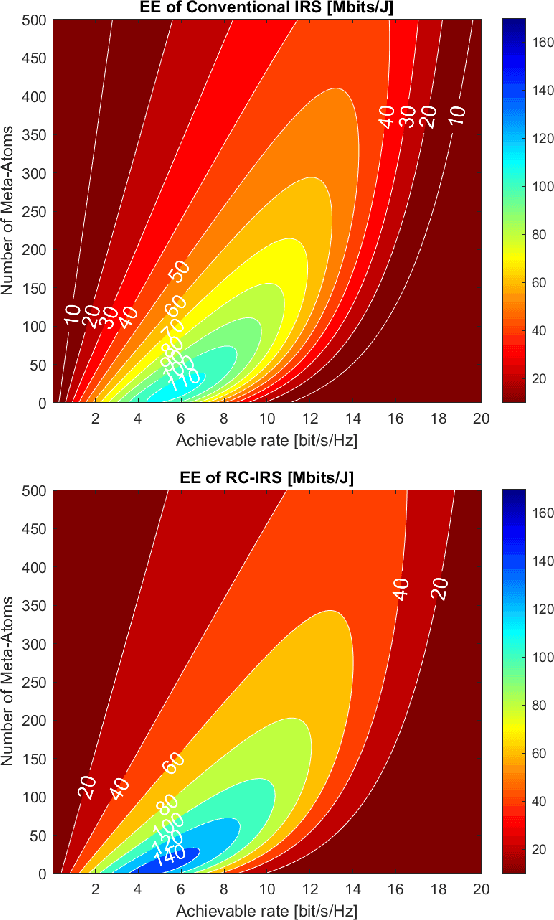
This article introduces a neural network-based signal processing framework for intelligent reflecting surface (IRS) aided wireless communications systems. By modeling radio-frequency (RF) impairments inside the "meta-atoms" of IRS (including nonlinearity and memory effects), we present an approach that generalizes the entire IRS-aided system as a reservoir computing (RC) system, an efficient recurrent neural network (RNN) operating in a state near the "edge of chaos". This framework enables us to take advantage of the nonlinearity of this "fabricated" wireless environment to overcome link degradation due to model mismatch. Accordingly, the randomness of the wireless channel and RF imperfections are naturally embedded into the RC framework, enabling the internal RC dynamics lying on the edge of chaos. Furthermore, several practical issues, such as channel state information acquisition, passive beamforming design, and physical layer reference signal design, are discussed.
Differential Privacy Meets Federated Learning under Communication Constraints
Jan 28, 2021
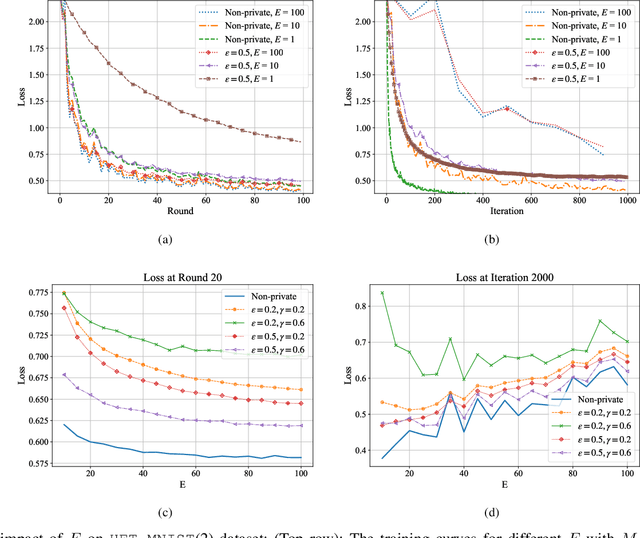

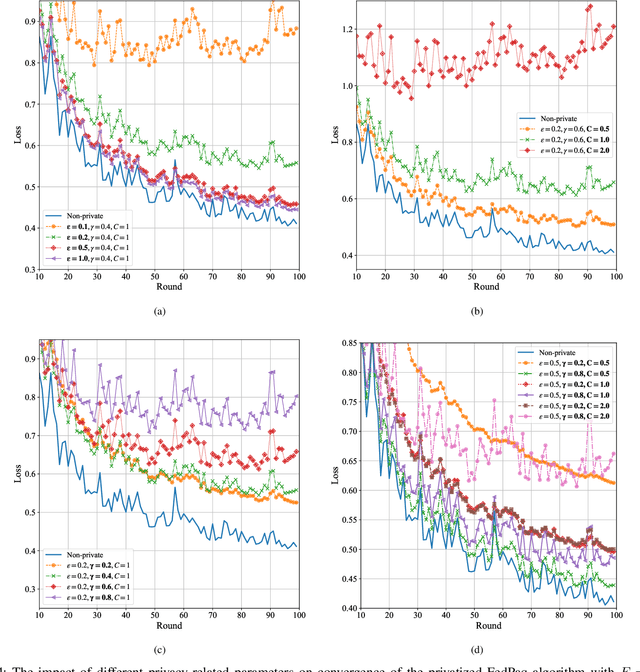
The performance of federated learning systems is bottlenecked by communication costs and training variance. The communication overhead problem is usually addressed by three communication-reduction techniques, namely, model compression, partial device participation, and periodic aggregation, at the cost of increased training variance. Different from traditional distributed learning systems, federated learning suffers from data heterogeneity (since the devices sample their data from possibly different distributions), which induces additional variance among devices during training. Various variance-reduced training algorithms have been introduced to combat the effects of data heterogeneity, while they usually cost additional communication resources to deliver necessary control information. Additionally, data privacy remains a critical issue in FL, and thus there have been attempts at bringing Differential Privacy to this framework as a mediator between utility and privacy requirements. This paper investigates the trade-offs between communication costs and training variance under a resource-constrained federated system theoretically and experimentally, and how communication reduction techniques interplay in a differentially private setting. The results provide important insights into designing practical privacy-aware federated learning systems.
Deep Echo State Q-Network and Its Application in Dynamic Spectrum Sharing for 5G and Beyond
Oct 12, 2020


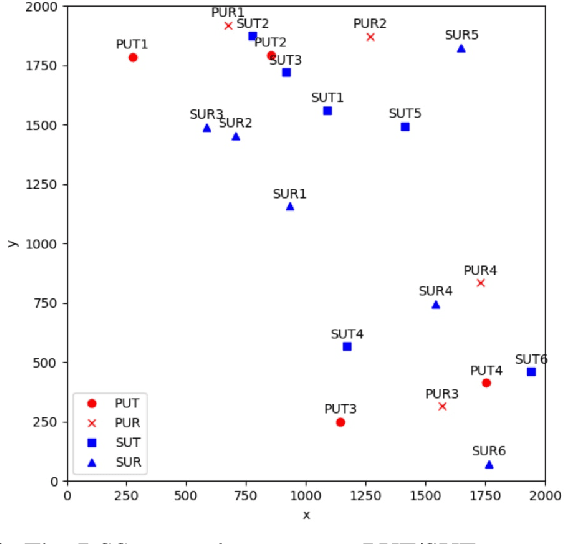
Deep reinforcement learning (DRL) has been shown to be successful in many application domains. Combining recurrent neural networks (RNNs) and DRL further enables DRL to be applicable in non-Markovian environments by capturing temporal information. However, training of both DRL and RNNs is known to be challenging requiring a large amount of training data to achieve convergence. In many targeted applications, such as those used in the fifth generation (5G) cellular communication, the environment is highly dynamic while the available training data is very limited. Therefore, it is extremely important to develop DRL strategies that are capable of capturing the temporal correlation of the dynamic environment requiring limited training overhead. In this paper, we introduce the deep echo state Q-network (DEQN) that can adapt to the highly dynamic environment in a short period of time with limited training data. We evaluate the performance of the introduced DEQN method under the dynamic spectrum sharing (DSS) scenario, which is a promising technology in 5G and future 6G networks to increase the spectrum utilization. Compared to conventional spectrum management policy that grants a fixed spectrum band to a single system for exclusive access, DSS allows the secondary system to share the spectrum with the primary system. Our work sheds light on the application of an efficient DRL framework in highly dynamic environments with limited available training data.