 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDichroGAN: Towards Restoration of in-air Colours of Seafloor from Satellite Imagery
Jan 01, 2026Recovering the in-air colours of seafloor from satellite imagery is a challenging task due to the exponential attenuation of light with depth in the water column. In this study, we present DichroGAN, a conditional generative adversarial network (cGAN) designed for this purpose. DichroGAN employs a two-steps simultaneous training: first, two generators utilise a hyperspectral image cube to estimate diffuse and specular reflections, thereby obtaining atmospheric scene radiance. Next, a third generator receives as input the generated scene radiance containing the features of each spectral band, while a fourth generator estimates the underwater light transmission. These generators work together to remove the effects of light absorption and scattering, restoring the in-air colours of seafloor based on the underwater image formation equation. DichroGAN is trained on a compact dataset derived from PRISMA satellite imagery, comprising RGB images paired with their corresponding spectral bands and masks. Extensive experiments on both satellite and underwater datasets demonstrate that DichroGAN achieves competitive performance compared to state-of-the-art underwater restoration techniques.
StraightPCF: Straight Point Cloud Filtering
May 14, 2024Point cloud filtering is a fundamental 3D vision task, which aims to remove noise while recovering the underlying clean surfaces. State-of-the-art methods remove noise by moving noisy points along stochastic trajectories to the clean surfaces. These methods often require regularization within the training objective and/or during post-processing, to ensure fidelity. In this paper, we introduce StraightPCF, a new deep learning based method for point cloud filtering. It works by moving noisy points along straight paths, thus reducing discretization errors while ensuring faster convergence to the clean surfaces. We model noisy patches as intermediate states between high noise patch variants and their clean counterparts, and design the VelocityModule to infer a constant flow velocity from the former to the latter. This constant flow leads to straight filtering trajectories. In addition, we introduce a DistanceModule that scales the straight trajectory using an estimated distance scalar to attain convergence near the clean surface. Our network is lightweight and only has $\sim530K$ parameters, being 17% of IterativePFN (a most recent point cloud filtering network). Extensive experiments on both synthetic and real-world data show our method achieves state-of-the-art results. Our method also demonstrates nice distributions of filtered points without the need for regularization. The implementation code can be found at: https://github.com/ddsediri/StraightPCF.
Weighted Point Cloud Normal Estimation
May 06, 2023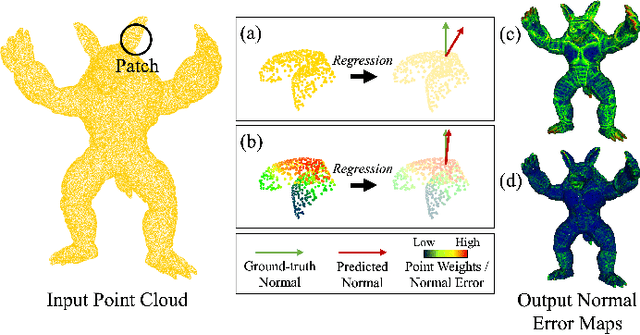
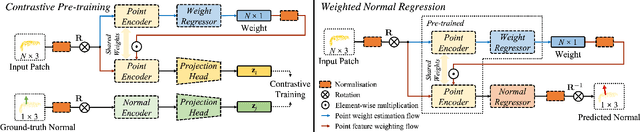
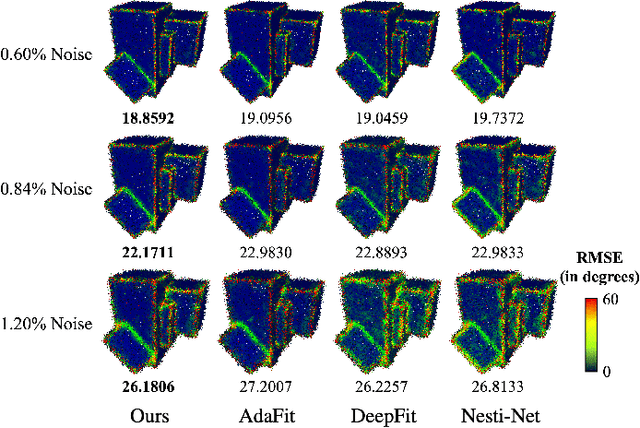
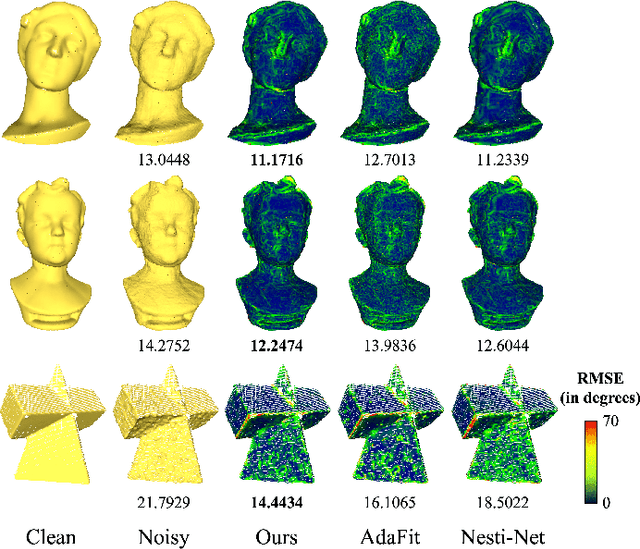
Existing normal estimation methods for point clouds are often less robust to severe noise and complex geometric structures. Also, they usually ignore the contributions of different neighbouring points during normal estimation, which leads to less accurate results. In this paper, we introduce a weighted normal estimation method for 3D point cloud data. We innovate in two key points: 1) we develop a novel weighted normal regression technique that predicts point-wise weights from local point patches and use them for robust, feature-preserving normal regression; 2) we propose to conduct contrastive learning between point patches and the corresponding ground-truth normals of the patches' central points as a pre-training process to facilitate normal regression. Comprehensive experiments demonstrate that our method can robustly handle noisy and complex point clouds, achieving state-of-the-art performance on both synthetic and real-world datasets.
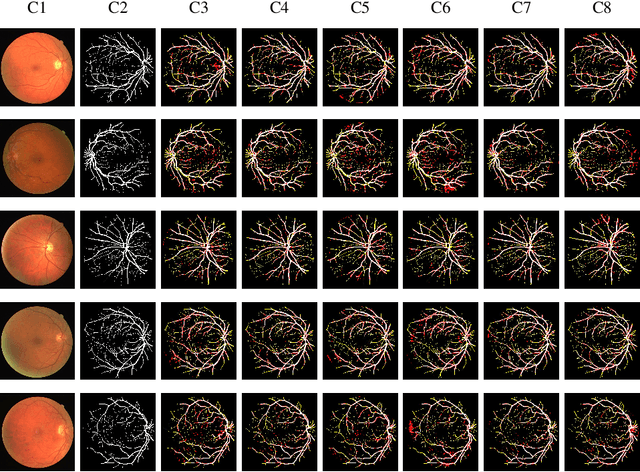
Retinal Vessel Segmentation via a Multi-resolution Contextual Network and Adversarial Learning
Apr 25, 2023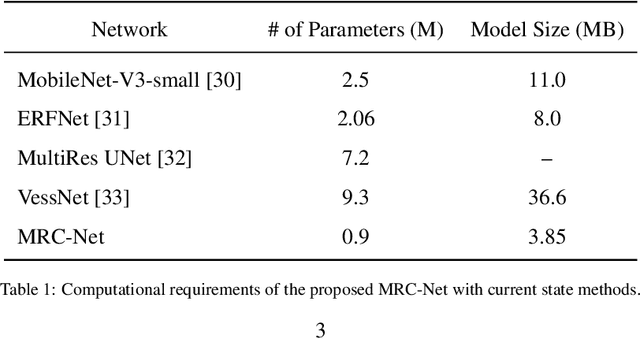
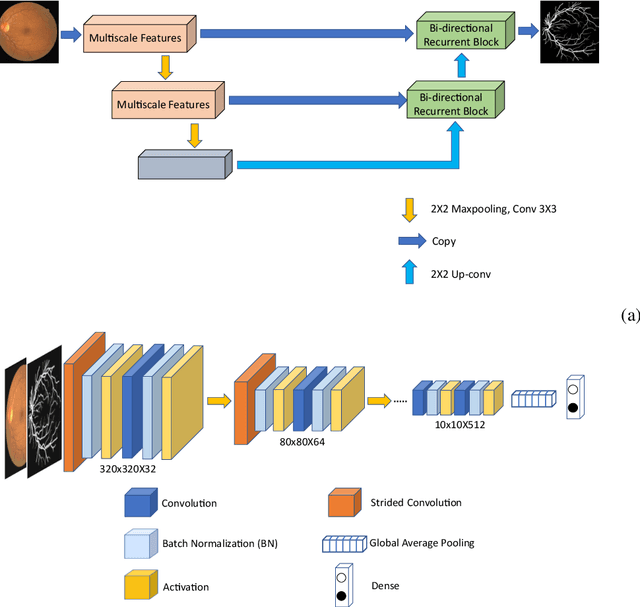
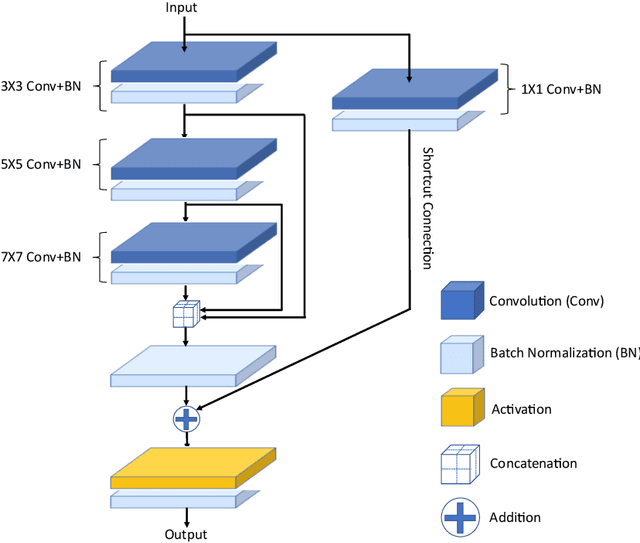
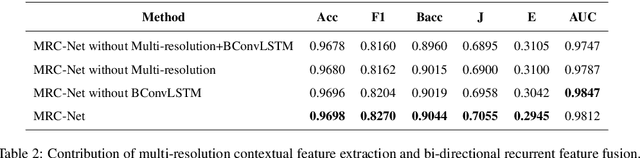
Timely and affordable computer-aided diagnosis of retinal diseases is pivotal in precluding blindness. Accurate retinal vessel segmentation plays an important role in disease progression and diagnosis of such vision-threatening diseases. To this end, we propose a Multi-resolution Contextual Network (MRC-Net) that addresses these issues by extracting multi-scale features to learn contextual dependencies between semantically different features and using bi-directional recurrent learning to model former-latter and latter-former dependencies. Another key idea is training in adversarial settings for foreground segmentation improvement through optimization of the region-based scores. This novel strategy boosts the performance of the segmentation network in terms of the Dice score (and correspondingly Jaccard index) while keeping the number of trainable parameters comparatively low. We have evaluated our method on three benchmark datasets, including DRIVE, STARE, and CHASE, demonstrating its superior performance as compared with competitive approaches elsewhere in the literature.
IterativePFN: True Iterative Point Cloud Filtering
Apr 04, 2023



The quality of point clouds is often limited by noise introduced during their capture process. Consequently, a fundamental 3D vision task is the removal of noise, known as point cloud filtering or denoising. State-of-the-art learning based methods focus on training neural networks to infer filtered displacements and directly shift noisy points onto the underlying clean surfaces. In high noise conditions, they iterate the filtering process. However, this iterative filtering is only done at test time and is less effective at ensuring points converge quickly onto the clean surfaces. We propose IterativePFN (iterative point cloud filtering network), which consists of multiple IterationModules that model the true iterative filtering process internally, within a single network. We train our IterativePFN network using a novel loss function that utilizes an adaptive ground truth target at each iteration to capture the relationship between intermediate filtering results during training. This ensures that the filtered results converge faster to the clean surfaces. Our method is able to obtain better performance compared to state-of-the-art methods. The source code can be found at: https://github.com/ddsediri/IterativePFN.
On the Behaviour of Pulsed Qubits and their Application to Feed Forward Networks
Feb 21, 2023In the last two decades, the combination of machine learning and quantum computing has been an ever-growing topic of interest but, to this date, the limitations of quantum computing hardware have somewhat restricted the use of complex multi-qubit operations for machine learning. In this paper, we capitalize on the cyclical nature of quantum state probabilities observed on pulsed qubits to propose a single-qubit feed forward block whose architecture allows for classical parameters to be used in a way similar to classical neural networks. To do this, we modulate the pulses exciting qubits to induce superimposed rotations around the Bloch Sphere. The approach presented here has the advantage of employing a single qubit per block. Thus, it is linear with respect to the number of blocks, not polynomial with respect to the number of neurons as opposed to the majority of methods elsewhere. Further, since it employs classical parameters, a large number of iterations and updates at training can be effected without dwelling on coherence times and the gradients can be reused and stored if necessary. We also show how an analogy can be drawn to neural networks using sine-squared activation functions and illustrate how the feed-forward block presented here may be used and implemented on pulse-enabled quantum computers.
DGD-cGAN: A Dual Generator for Image Dewatering and Restoration
Nov 18, 2022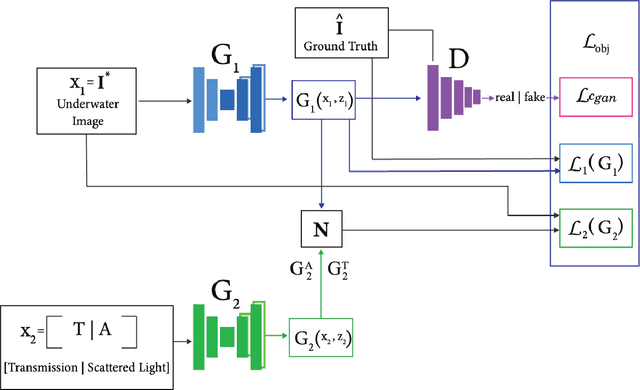
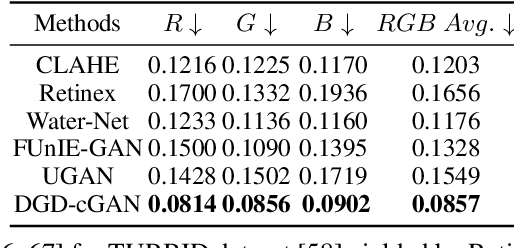
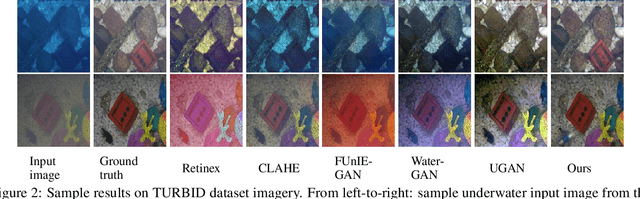
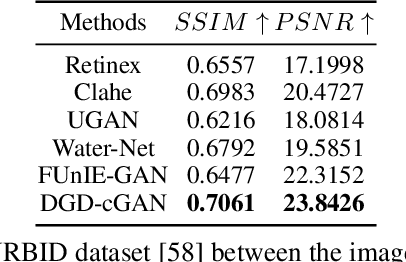
Underwater images are usually covered with a blue-greenish colour cast, making them distorted, blurry or low in contrast. This phenomenon occurs due to the light attenuation given by the scattering and absorption in the water column. In this paper, we present an image enhancement approach for dewatering which employs a conditional generative adversarial network (cGAN) with two generators. Our Dual Generator Dewatering cGAN (DGD-cGAN) removes the haze and colour cast induced by the water column and restores the true colours of underwater scenes whereby the effects of various attenuation and scattering phenomena that occur in underwater images are tackled by the two generators. The first generator takes at input the underwater image and predicts the dewatered scene, while the second generator learns the underwater image formation process by implementing a custom loss function based upon the transmission and the veiling light components of the image formation model. Our experiments show that DGD-cGAN consistently delivers a margin of improvement as compared with the state-of-the-art methods on several widely available datasets.
MKIS-Net: A Light-Weight Multi-Kernel Network for Medical Image Segmentation
Oct 15, 2022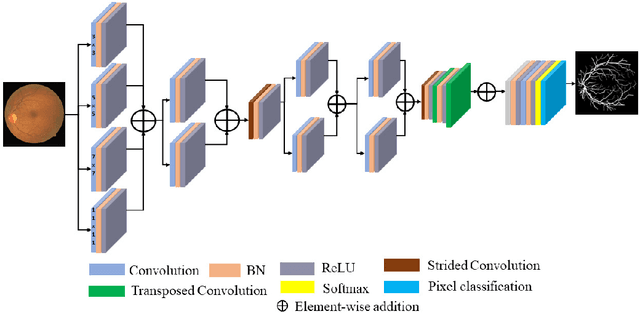

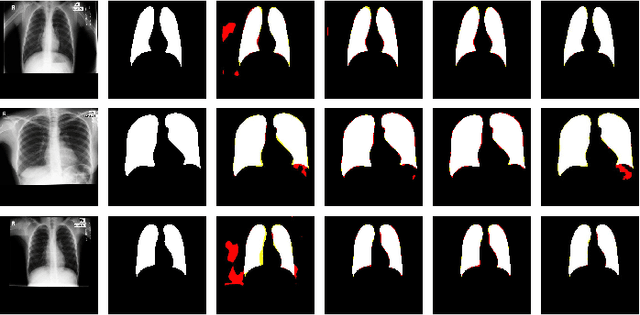

Image segmentation is an important task in medical imaging. It constitutes the backbone of a wide variety of clinical diagnostic methods, treatments, and computer-aided surgeries. In this paper, we propose a multi-kernel image segmentation net (MKIS-Net), which uses multiple kernels to create an efficient receptive field and enhance segmentation performance. As a result of its multi-kernel design, MKIS-Net is a light-weight architecture with a small number of trainable parameters. Moreover, these multi-kernel receptive fields also contribute to better segmentation results. We demonstrate the efficacy of MKIS-Net on several tasks including segmentation of retinal vessels, skin lesion segmentation, and chest X-ray segmentation. The performance of the proposed network is quite competitive, and often superior, in comparison to state-of-the-art methods. Moreover, in some cases MKIS-Net has more than an order of magnitude fewer trainable parameters than existing medical image segmentation alternatives and is at least four times smaller than other light-weight architectures.
Neural Network Compression by Joint Sparsity Promotion and Redundancy Reduction
Oct 14, 2022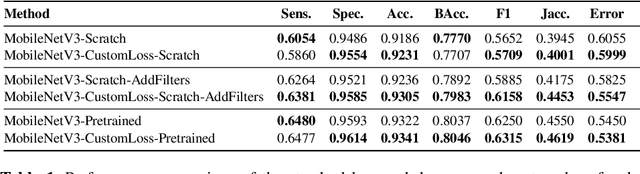
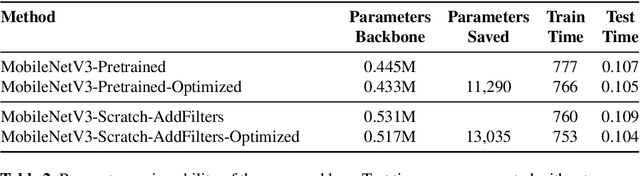

Compression of convolutional neural network models has recently been dominated by pruning approaches. A class of previous works focuses solely on pruning the unimportant filters to achieve network compression. Another important direction is the design of sparsity-inducing constraints which has also been explored in isolation. This paper presents a novel training scheme based on composite constraints that prune redundant filters and minimize their effect on overall network learning via sparsity promotion. Also, as opposed to prior works that employ pseudo-norm-based sparsity-inducing constraints, we propose a sparse scheme based on gradient counting in our framework. Our tests on several pixel-wise segmentation benchmarks show that the number of neurons and the memory footprint of networks in the test phase are significantly reduced without affecting performance. MobileNetV3 and UNet, two well-known architectures, are used to test the proposed scheme. Our network compression method not only results in reduced parameters but also achieves improved performance compared to MobileNetv3, which is an already optimized architecture.
Graph Classification via Discriminative Edge Feature Learning
Oct 05, 2022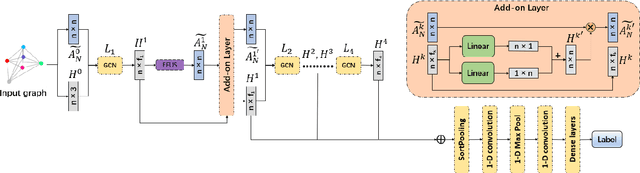
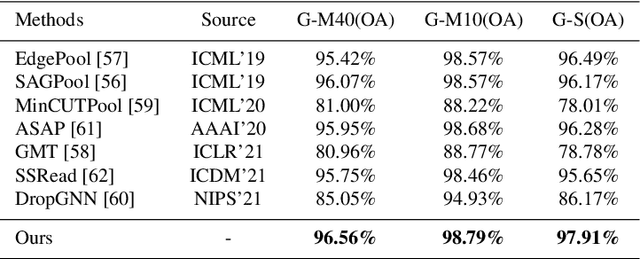
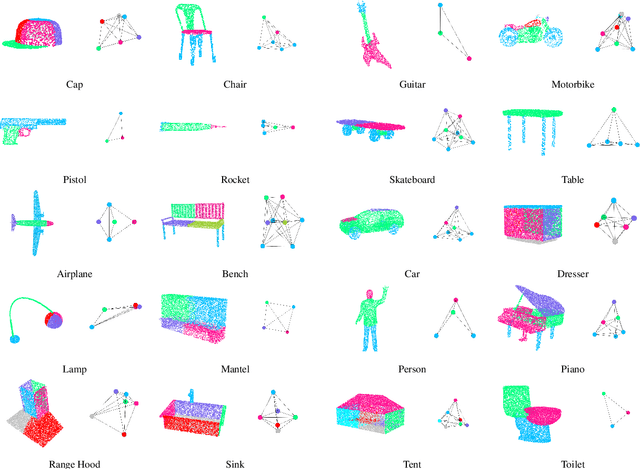
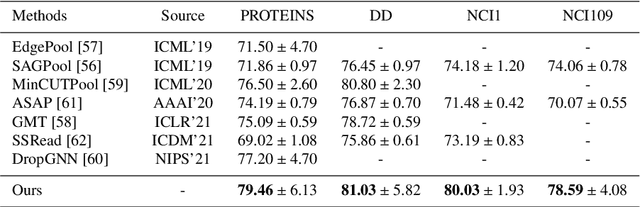
Spectral graph convolutional neural networks (GCNNs) have been producing encouraging results in graph classification tasks. However, most spectral GCNNs utilize fixed graphs when aggregating node features, while omitting edge feature learning and failing to get an optimal graph structure. Moreover, many existing graph datasets do not provide initialized edge features, further restraining the ability of learning edge features via spectral GCNNs. In this paper, we try to address this issue by designing an edge feature scheme and an add-on layer between every two stacked graph convolution layers in GCNN. Both are lightweight while effective in filling the gap between edge feature learning and performance enhancement of graph classification. The edge feature scheme makes edge features adapt to node representations at different graph convolution layers. The add-on layers help adjust the edge features to an optimal graph structure. To test the effectiveness of our method, we take Euclidean positions as initial node features and extract graphs with semantic information from point cloud objects. The node features of our extracted graphs are more scalable for edge feature learning than most existing graph datasets (in one-hot encoded label format). Three new graph datasets are constructed based on ModelNet40, ModelNet10 and ShapeNet Part datasets. Experimental results show that our method outperforms state-of-the-art graph classification methods on the new datasets by reaching 96.56% overall accuracy on Graph-ModelNet40, 98.79% on Graph-ModelNet10 and 97.91% on Graph-ShapeNet Part. The constructed graph datasets will be released to the community.