 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightLLM: A Versatile Large Language Model for Predictive Light Sensing
Nov 20, 2024



We propose LightLLM, a model that fine tunes pre-trained large language models (LLMs) for light-based sensing tasks. It integrates a sensor data encoder to extract key features, a contextual prompt to provide environmental information, and a fusion layer to combine these inputs into a unified representation. This combined input is then processed by the pre-trained LLM, which remains frozen while being fine-tuned through the addition of lightweight, trainable components, allowing the model to adapt to new tasks without altering its original parameters. This approach enables flexible adaptation of LLM to specialized light sensing tasks with minimal computational overhead and retraining effort. We have implemented LightLLM for three light sensing tasks: light-based localization, outdoor solar forecasting, and indoor solar estimation. Using real-world experimental datasets, we demonstrate that LightLLM significantly outperforms state-of-the-art methods, achieving 4.4x improvement in localization accuracy and 3.4x improvement in indoor solar estimation when tested in previously unseen environments. We further demonstrate that LightLLM outperforms ChatGPT-4 with direct prompting, highlighting the advantages of LightLLM's specialized architecture for sensor data fusion with textual prompts.
Human-in-the-Loop Segmentation of Multi-species Coral Imagery
Apr 16, 2024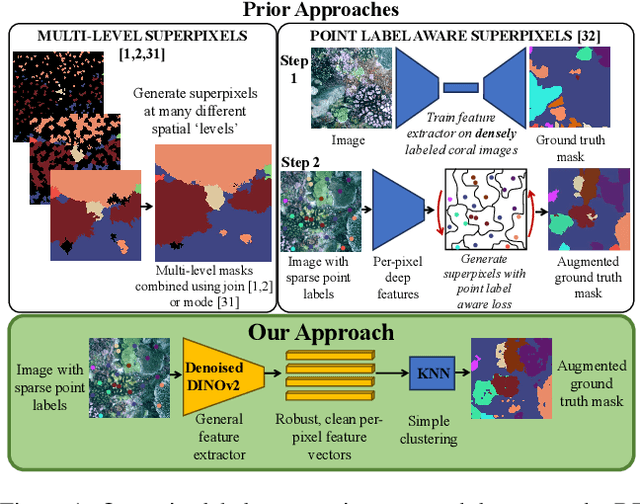
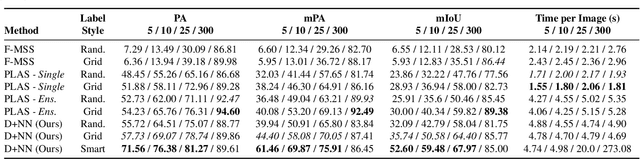
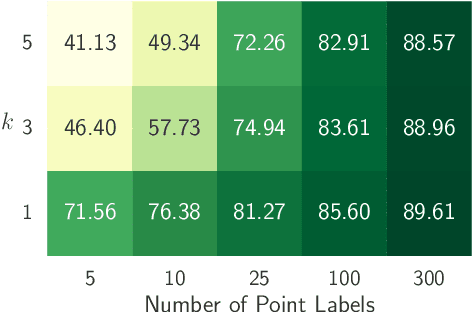

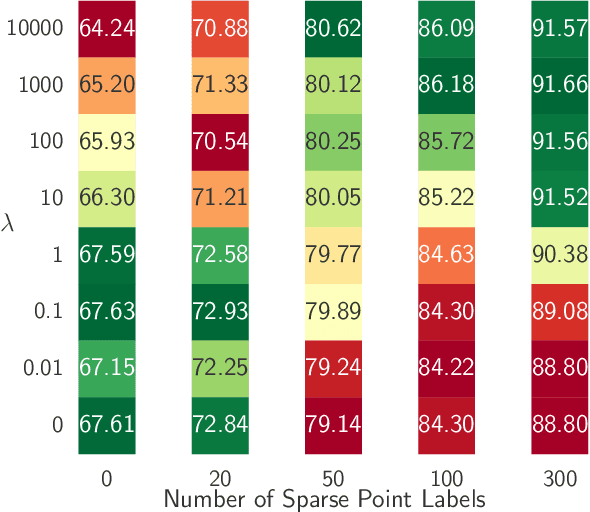
Broad-scale marine surveys performed by underwater vehicles significantly increase the availability of coral reef imagery, however it is costly and time-consuming for domain experts to label images. Point label propagation is an approach used to leverage existing image data labeled with sparse point labels. The resulting augmented ground truth generated is then used to train a semantic segmentation model. Here, we first demonstrate that recent advances in foundation models enable generation of multi-species coral augmented ground truth masks using denoised DINOv2 features and K-Nearest Neighbors (KNN), without the need for any pre-training or custom-designed algorithms. For extremely sparsely labeled images, we propose a labeling regime based on human-in-the-loop principles, resulting in significant improvement in annotation efficiency: If only 5 point labels per image are available, our proposed human-in-the-loop approach improves on the state-of-the-art by 17.3% for pixel accuracy and 22.6% for mIoU; and by 10.6% and 19.1% when 10 point labels per image are available. Even if the human-in-the-loop labeling regime is not used, the denoised DINOv2 features with a KNN outperforms the prior state-of-the-art by 3.5% for pixel accuracy and 5.7% for mIoU (5 grid points). We also provide a detailed analysis of how point labeling style and the quantity of points per image affects the point label propagation quality and provide general recommendations on maximizing point label efficiency.
Understanding the Effects of Projectors in Knowledge Distillation
Oct 26, 2023



Conventionally, during the knowledge distillation process (e.g. feature distillation), an additional projector is often required to perform feature transformation due to the dimension mismatch between the teacher and the student networks. Interestingly, we discovered that even if the student and the teacher have the same feature dimensions, adding a projector still helps to improve the distillation performance. In addition, projectors even improve logit distillation if we add them to the architecture too. Inspired by these surprising findings and the general lack of understanding of the projectors in the knowledge distillation process from existing literature, this paper investigates the implicit role that projectors play but so far have been overlooked. Our empirical study shows that the student with a projector (1) obtains a better trade-off between the training accuracy and the testing accuracy compared to the student without a projector when it has the same feature dimensions as the teacher, (2) better preserves its similarity to the teacher beyond shallow and numeric resemblance, from the view of Centered Kernel Alignment (CKA), and (3) avoids being over-confident as the teacher does at the testing phase. Motivated by the positive effects of projectors, we propose a projector ensemble-based feature distillation method to further improve distillation performance. Despite the simplicity of the proposed strategy, empirical results from the evaluation of classification tasks on benchmark datasets demonstrate the superior classification performance of our method on a broad range of teacher-student pairs and verify from the aspects of CKA and model calibration that the student's features are of improved quality with the projector ensemble design.
Object Detection Difficulty: Suppressing Over-aggregation for Faster and Better Video Object Detection
Aug 22, 2023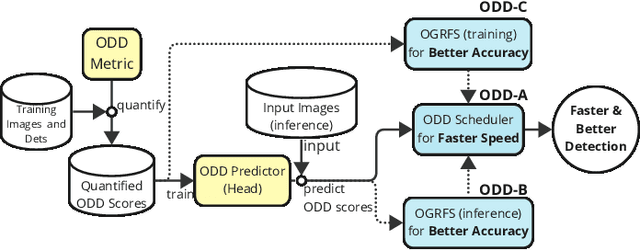
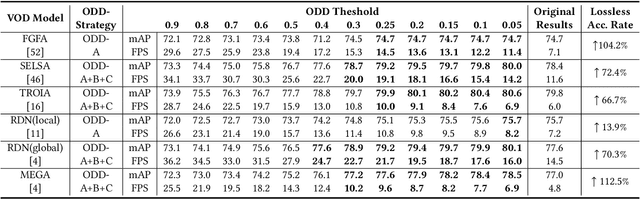

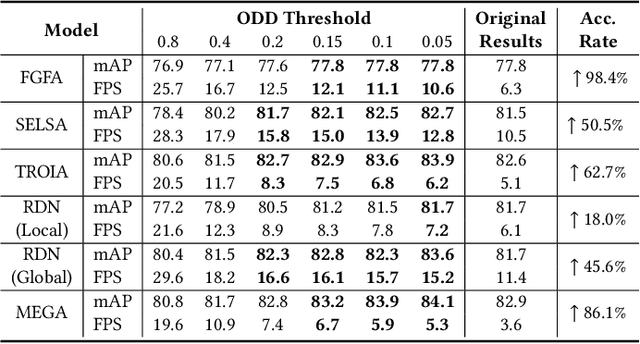
Current video object detection (VOD) models often encounter issues with over-aggregation due to redundant aggregation strategies, which perform feature aggregation on every frame. This results in suboptimal performance and increased computational complexity. In this work, we propose an image-level Object Detection Difficulty (ODD) metric to quantify the difficulty of detecting objects in a given image. The derived ODD scores can be used in the VOD process to mitigate over-aggregation. Specifically, we train an ODD predictor as an auxiliary head of a still-image object detector to compute the ODD score for each image based on the discrepancies between detection results and ground-truth bounding boxes. The ODD score enhances the VOD system in two ways: 1) it enables the VOD system to select superior global reference frames, thereby improving overall accuracy; and 2) it serves as an indicator in the newly designed ODD Scheduler to eliminate the aggregation of frames that are easy to detect, thus accelerating the VOD process. Comprehensive experiments demonstrate that, when utilized for selecting global reference frames, ODD-VOD consistently enhances the accuracy of Global-frame-based VOD models. When employed for acceleration, ODD-VOD consistently improves the frames per second (FPS) by an average of 73.3% across 8 different VOD models without sacrificing accuracy. When combined, ODD-VOD attains state-of-the-art performance when competing with many VOD methods in both accuracy and speed. Our work represents a significant advancement towards making VOD more practical for real-world applications.
CVB: A Video Dataset of Cattle Visual Behaviors
May 26, 2023

Existing image/video datasets for cattle behavior recognition are mostly small, lack well-defined labels, or are collected in unrealistic controlled environments. This limits the utility of machine learning (ML) models learned from them. Therefore, we introduce a new dataset, called Cattle Visual Behaviors (CVB), that consists of 502 video clips, each fifteen seconds long, captured in natural lighting conditions, and annotated with eleven visually perceptible behaviors of grazing cattle. We use the Computer Vision Annotation Tool (CVAT) to collect our annotations. To make the procedure more efficient, we perform an initial detection and tracking of cattle in the videos using appropriate pre-trained models. The results are corrected by domain experts along with cattle behavior labeling in CVAT. The pre-hoc detection and tracking step significantly reduces the manual annotation time and effort. Moreover, we convert CVB to the atomic visual action (AVA) format and train and evaluate the popular SlowFast action recognition model on it. The associated preliminary results confirm that we can localize the cattle and recognize their frequently occurring behaviors with confidence. By creating and sharing CVB, our aim is to develop improved models capable of recognizing all important behaviors accurately and to assist other researchers and practitioners in developing and evaluating new ML models for cattle behavior classification using video data.
Image Labels Are All You Need for Coarse Seagrass Segmentation
Mar 02, 2023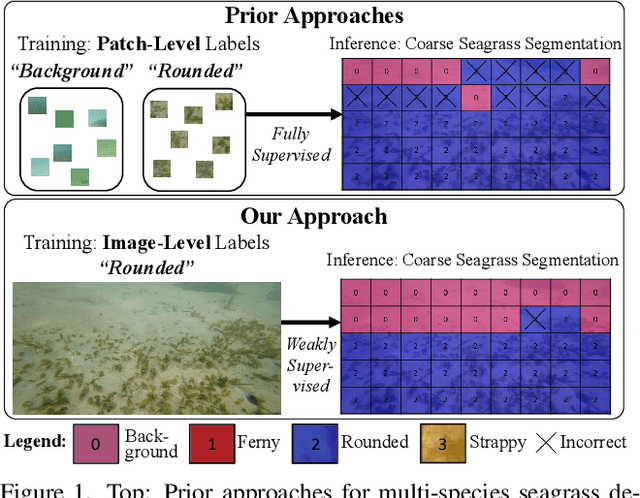
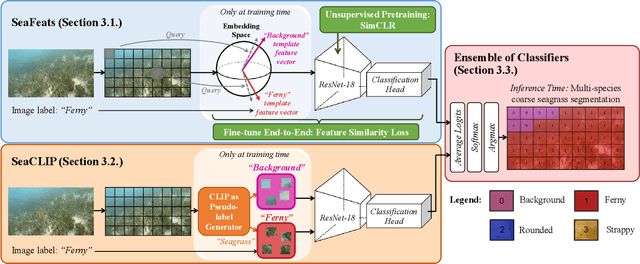
Seagrass meadows serve as critical carbon sinks, but accurately estimating the amount of carbon they store requires knowledge of the seagrass species present. Using underwater and surface vehicles equipped with machine learning algorithms can help to accurately estimate the composition and extent of seagrass meadows at scale. However, previous approaches for seagrass detection and classification have required full supervision from patch-level labels. In this paper, we reframe seagrass classification as a weakly supervised coarse segmentation problem where image-level labels are used during training (25 times fewer labels compared to patch-level labeling) and patch-level outputs are obtained at inference time. To this end, we introduce SeaFeats, an architecture that uses unsupervised contrastive pretraining and feature similarity to separate background and seagrass patches, and SeaCLIP, a model that showcases the effectiveness of large language models as a supervisory signal in domain-specific applications. We demonstrate that an ensemble of SeaFeats and SeaCLIP leads to highly robust performance, with SeaCLIP conservatively predicting the background class to avoid false seagrass misclassifications in blurry or dark patches. Our method outperforms previous approaches that require patch-level labels on the multi-species 'DeepSeagrass' dataset by 6.8% (absolute) for the class-weighted F1 score, and by 12.1% (absolute) F1 score for seagrass presence/absence on the 'Global Wetlands' dataset. We also present two case studies for real-world deployment: outlier detection on the Global Wetlands dataset, and application of our method on imagery collected by FloatyBoat, an autonomous surface vehicle.
A Capsule Network for Hierarchical Multi-Label Image Classification
Sep 13, 2022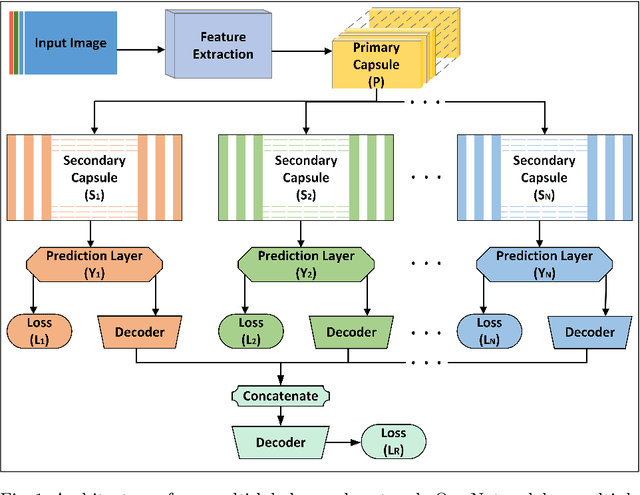
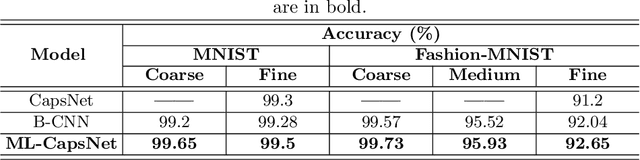
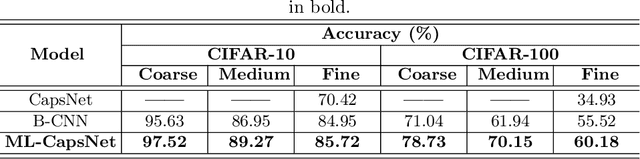
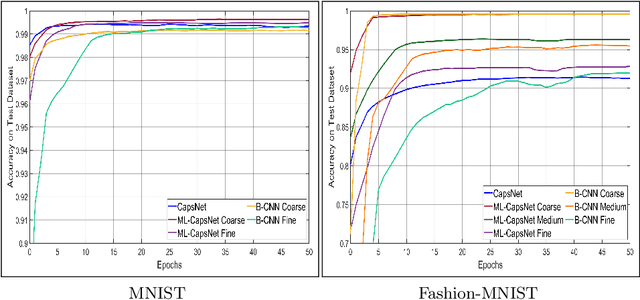
Image classification is one of the most important areas in computer vision. Hierarchical multi-label classification applies when a multi-class image classification problem is arranged into smaller ones based upon a hierarchy or taxonomy. Thus, hierarchical classification modes generally provide multiple class predictions on each instance, whereby these are expected to reflect the structure of image classes as related to one another. In this paper, we propose a multi-label capsule network (ML-CapsNet) for hierarchical classification. Our ML-CapsNet predicts multiple image classes based on a hierarchical class-label tree structure. To this end, we present a loss function that takes into account the multi-label predictions of the network. As a result, the training approach for our ML-CapsNet uses a coarse to fine paradigm while maintaining consistency with the structure in the classification levels in the label-hierarchy. We also perform experiments using widely available datasets and compare the model with alternatives elsewhere in the literature. In our experiments, our ML-CapsNet yields a margin of improvement with respect to these alternative methods.
A Real-time Edge-AI System for Reef Surveys
Aug 01, 2022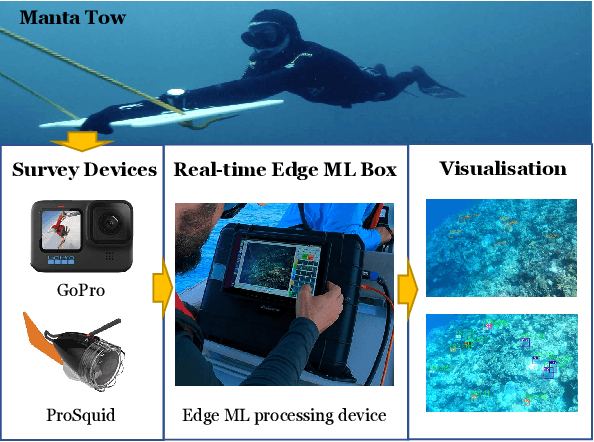
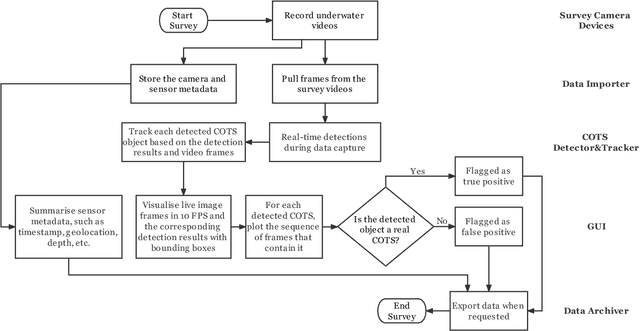
Crown-of-Thorn Starfish (COTS) outbreaks are a major cause of coral loss on the Great Barrier Reef (GBR) and substantial surveillance and control programs are ongoing to manage COTS populations to ecologically sustainable levels. In this paper, we present a comprehensive real-time machine learning-based underwater data collection and curation system on edge devices for COTS monitoring. In particular, we leverage the power of deep learning-based object detection techniques, and propose a resource-efficient COTS detector that performs detection inferences on the edge device to assist marine experts with COTS identification during the data collection phase. The preliminary results show that several strategies for improving computational efficiency (e.g., batch-wise processing, frame skipping, model input size) can be combined to run the proposed detection model on edge hardware with low resource consumption and low information loss.
Point Label Aware Superpixels for Multi-species Segmentation of Underwater Imagery
Feb 27, 2022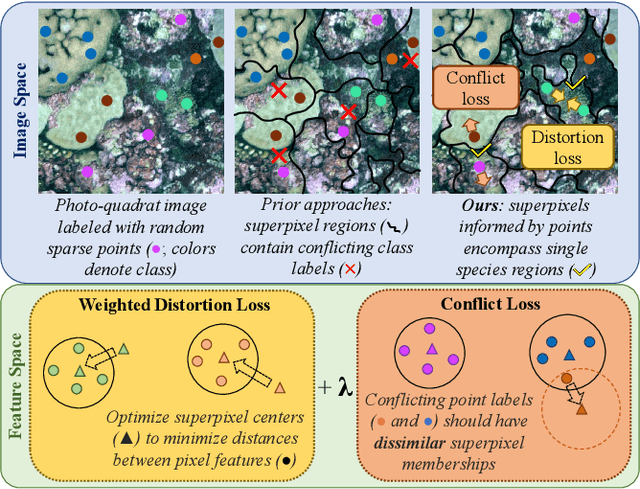
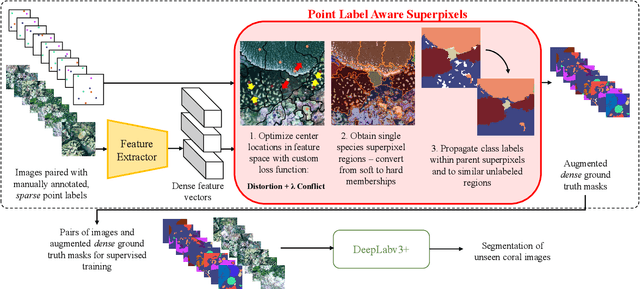
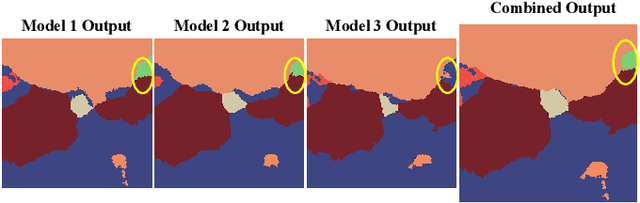
Monitoring coral reefs using underwater vehicles increases the range of marine surveys and availability of historical ecological data by collecting significant quantities of images. Analysis of this imagery can be automated using a model trained to perform semantic segmentation, however it is too costly and time-consuming to densely label images for training supervised models. In this letter, we leverage photo-quadrat imagery labeled by ecologists with sparse point labels. We propose a point label aware method for propagating labels within superpixel regions to obtain augmented ground truth for training a semantic segmentation model. Our point label aware superpixel method utilizes the sparse point labels, and clusters pixels using learned features to accurately generate single-species segments in cluttered, complex coral images. Our method outperforms prior methods on the UCSD Mosaics dataset by 3.62% for pixel accuracy and 8.35% for mean IoU for the label propagation task. Furthermore, our approach reduces computation time reported by previous approaches by 76%. We train a DeepLabv3+ architecture and outperform state-of-the-art for semantic segmentation by 2.91% for pixel accuracy and 9.65% for mean IoU on the UCSD Mosaics dataset and by 4.19% for pixel accuracy and 14.32% mean IoU for the Eilat dataset.
The CSIRO Crown-of-Thorn Starfish Detection Dataset
Nov 29, 2021
Crown-of-Thorn Starfish (COTS) outbreaks are a major cause of coral loss on the Great Barrier Reef (GBR) and substantial surveillance and control programs are underway in an attempt to manage COTS populations to ecologically sustainable levels. We release a large-scale, annotated underwater image dataset from a COTS outbreak area on the GBR, to encourage research on Machine Learning and AI-driven technologies to improve the detection, monitoring, and management of COTS populations at reef scale. The dataset is released and hosted in a Kaggle competition that challenges the international Machine Learning community with the task of COTS detection from these underwater images.