 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Photometric Uncertainty in Gaussian Splatting for Novel View Synthesis
Mar 24, 2026Recent advances in 3D Gaussian Splatting have enabled impressive photorealistic novel view synthesis. However, to transition from a pure rendering engine to a reliable spatial map for autonomous agents and safety-critical applications, knowing where the representation is uncertain is as important as the rendering fidelity itself. We bridge this critical gap by introducing a lightweight, plug-and-play framework for pixel-wise, view-dependent predictive uncertainty estimation. Our post-hoc method formulates uncertainty as a Bayesian-regularized linear least-squares optimization over reconstruction residuals. This architecture-agnostic approach extracts a per-primitive uncertainty channel without modifying the underlying scene representation or degrading baseline visual fidelity. Crucially, we demonstrate that providing this actionable reliability signal successfully translates 3D Gaussian splatting into a trustworthy spatial map, further improving state-of-the-art performance across three critical downstream perception tasks: active view selection, pose-agnostic scene change detection, and pose-agnostic anomaly detection.
ReMoSPLAT: Reactive Mobile Manipulation Control on a Gaussian Splat
Dec 10, 2025
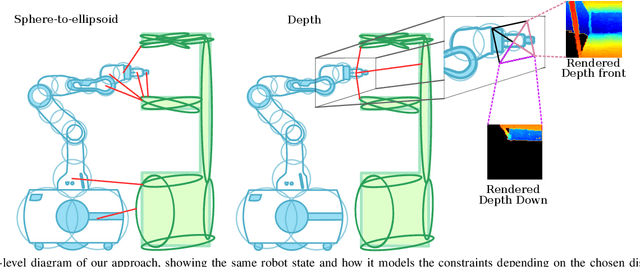

Reactive control can gracefully coordinate the motion of the base and the arm of a mobile manipulator. However, incorporating an accurate representation of the environment to avoid obstacles without involving costly planning remains a challenge. In this work, we present ReMoSPLAT, a reactive controller based on a quadratic program formulation for mobile manipulation that leverages a Gaussian Splat representation for collision avoidance. By integrating additional constraints and costs into the optimisation formulation, a mobile manipulator platform can reach its intended end effector pose while avoiding obstacles, even in cluttered scenes. We investigate the trade-offs of two methods for efficiently calculating robot-obstacle distances, comparing a purely geometric approach with a rasterisation-based approach. Our experiments in simulation on both synthetic and real-world scans demonstrate the feasibility of our method, showing that the proposed approach achieves performance comparable to controllers that rely on perfect ground-truth information.
IMLE Policy: Fast and Sample Efficient Visuomotor Policy Learning via Implicit Maximum Likelihood Estimation
Feb 17, 2025



Recent advances in imitation learning, particularly using generative modelling techniques like diffusion, have enabled policies to capture complex multi-modal action distributions. However, these methods often require large datasets and multiple inference steps for action generation, posing challenges in robotics where the cost for data collection is high and computation resources are limited. To address this, we introduce IMLE Policy, a novel behaviour cloning approach based on Implicit Maximum Likelihood Estimation (IMLE). IMLE Policy excels in low-data regimes, effectively learning from minimal demonstrations and requiring 38\% less data on average to match the performance of baseline methods in learning complex multi-modal behaviours. Its simple generator-based architecture enables single-step action generation, improving inference speed by 97.3\% compared to Diffusion Policy, while outperforming single-step Flow Matching. We validate our approach across diverse manipulation tasks in simulated and real-world environments, showcasing its ability to capture complex behaviours under data constraints. Videos and code are provided on our project page: https://imle-policy.github.io/.
Multi-View Pose-Agnostic Change Localization with Zero Labels
Dec 05, 2024Autonomous agents often require accurate methods for detecting and localizing changes in their environment, particularly when observations are captured from unconstrained and inconsistent viewpoints. We propose a novel label-free, pose-agnostic change detection method that integrates information from multiple viewpoints to construct a change-aware 3D Gaussian Splatting (3DGS) representation of the scene. With as few as 5 images of the post-change scene, our approach can learn additional change channels in a 3DGS and produce change masks that outperform single-view techniques. Our change-aware 3D scene representation additionally enables the generation of accurate change masks for unseen viewpoints. Experimental results demonstrate state-of-the-art performance in complex multi-object scenes, achieving a 1.7$\times$ and 1.6$\times$ improvement in Mean Intersection Over Union and F1 score respectively over other baselines. We also contribute a new real-world dataset to benchmark change detection in diverse challenging scenes in the presence of lighting variations.
Reducing Label Dependency for Underwater Scene Understanding: A Survey of Datasets, Techniques and Applications
Nov 18, 2024Underwater surveys provide long-term data for informing management strategies, monitoring coral reef health, and estimating blue carbon stocks. Advances in broad-scale survey methods, such as robotic underwater vehicles, have increased the range of marine surveys but generate large volumes of imagery requiring analysis. Computer vision methods such as semantic segmentation aid automated image analysis, but typically rely on fully supervised training with extensive labelled data. While ground truth label masks for tasks like street scene segmentation can be quickly and affordably generated by non-experts through crowdsourcing services like Amazon Mechanical Turk, ecology presents greater challenges. The complexity of underwater images, coupled with the specialist expertise needed to accurately identify species at the pixel level, makes this process costly, time-consuming, and heavily dependent on domain experts. In recent years, some works have performed automated analysis of underwater imagery, and a smaller number of studies have focused on weakly supervised approaches which aim to reduce the expert-provided labelled data required. This survey focuses on approaches which reduce dependency on human expert input, while reviewing the prior and related approaches to position these works in the wider field of underwater perception. Further, we offer an overview of coastal ecosystems and the challenges of underwater imagery. We provide background on weakly and self-supervised deep learning and integrate these elements into a taxonomy that centres on the intersection of underwater monitoring, computer vision, and deep learning, while motivating approaches for weakly supervised deep learning with reduced dependency on domain expert data annotations. Lastly, the survey examines available datasets and platforms, and identifies gaps, barriers, and opportunities for automating underwater surveys.
Affordance-Centric Policy Learning: Sample Efficient and Generalisable Robot Policy Learning using Affordance-Centric Task Frames
Oct 15, 2024



Affordances are central to robotic manipulation, where most tasks can be simplified to interactions with task-specific regions on objects. By focusing on these key regions, we can abstract away task-irrelevant information, simplifying the learning process, and enhancing generalisation. In this paper, we propose an affordance-centric policy-learning approach that centres and appropriately \textit{orients} a \textit{task frame} on these affordance regions allowing us to achieve both \textbf{intra-category invariance} -- where policies can generalise across different instances within the same object category -- and \textbf{spatial invariance} -- which enables consistent performance regardless of object placement in the environment. We propose a method to leverage existing generalist large vision models to extract and track these affordance frames, and demonstrate that our approach can learn manipulation tasks using behaviour cloning from as little as 10 demonstrations, with equivalent generalisation to an image-based policy trained on 305 demonstrations. We provide video demonstrations on our project site: https://affordance-policy.github.io.
RMMI: Enhanced Obstacle Avoidance for Reactive Mobile Manipulation using an Implicit Neural Map
Aug 29, 2024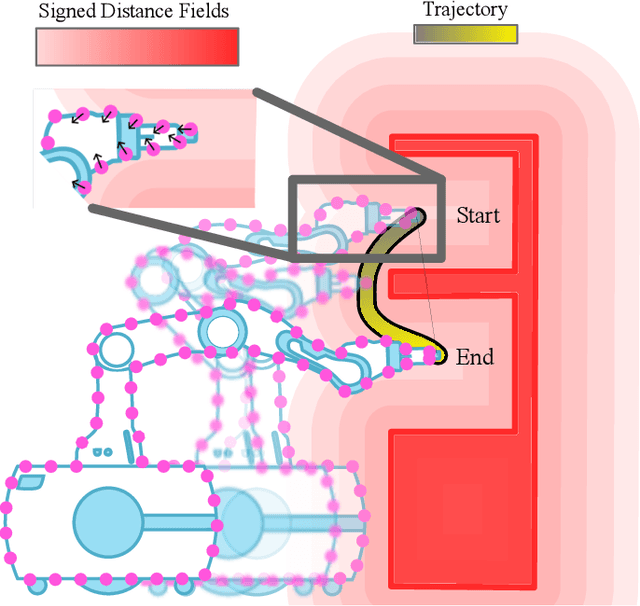
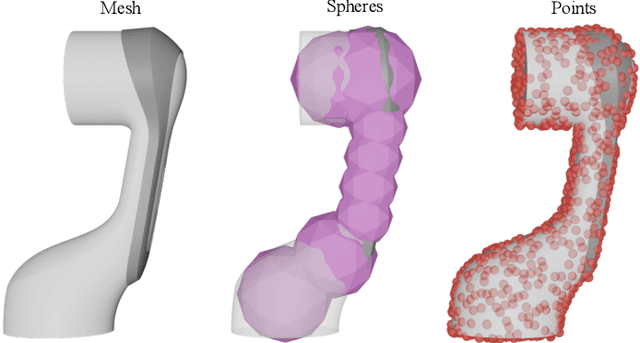
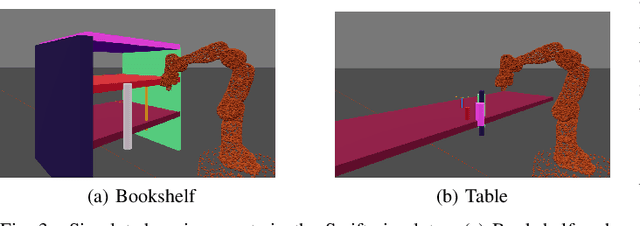
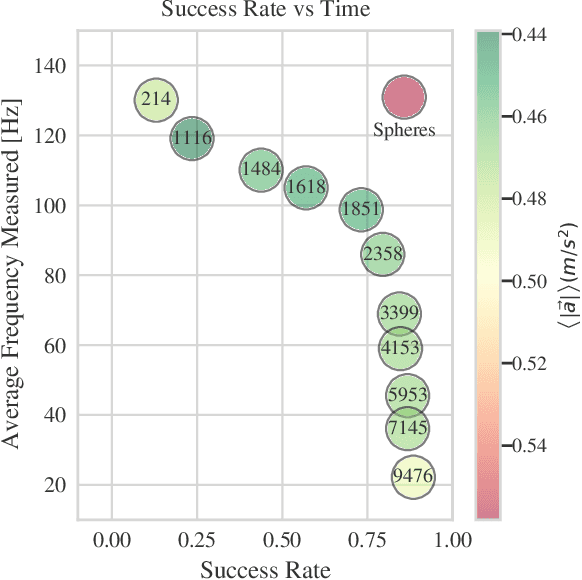
We introduce RMMI, a novel reactive control framework for mobile manipulators operating in complex, static environments. Our approach leverages a neural Signed Distance Field (SDF) to model intricate environment details and incorporates this representation as inequality constraints within a Quadratic Program (QP) to coordinate robot joint and base motion. A key contribution is the introduction of an active collision avoidance cost term that maximises the total robot distance to obstacles during the motion. We first evaluate our approach in a simulated reaching task, outperforming previous methods that rely on representing both the robot and the scene as a set of primitive geometries. Compared with the baseline, we improved the task success rate by 25% in total, which includes increases of 10% by using the active collision cost. We also demonstrate our approach on a real-world platform, showing its effectiveness in reaching target poses in cluttered and confined spaces using environment models built directly from sensor data. For additional details and experiment videos, visit https://rmmi.github.io/.
Open-Vocabulary Part-Based Grasping
Jun 10, 2024
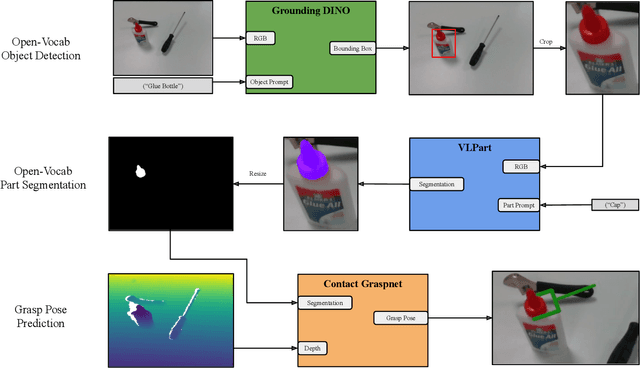

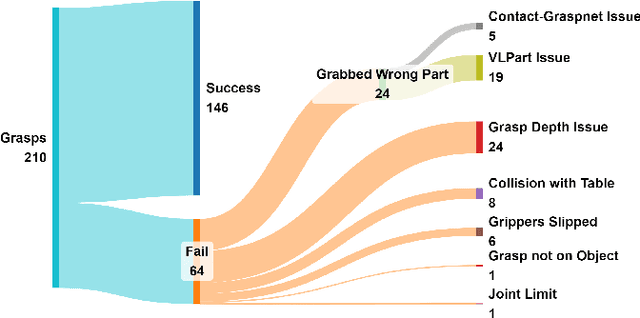
Many robotic applications require to grasp objects not arbitrarily but at a very specific object part. This is especially important for manipulation tasks beyond simple pick-and-place scenarios or in robot-human interactions, such as object handovers. We propose AnyPart, a practical system that combines open-vocabulary object detection, open-vocabulary part segmentation and 6DOF grasp pose prediction to infer a grasp pose on a specific part of an object in 800 milliseconds. We contribute two new datasets for the task of open-vocabulary part-based grasping, a hand-segmented dataset containing 1014 object-part segmentations, and a dataset of real-world scenarios gathered during our robot trials for individual objects and table-clearing tasks. We evaluate AnyPart on a mobile manipulator robot using a set of 28 common household objects over 360 grasping trials. AnyPart is capable of producing successful grasps 69.52 %, when ignoring robot-based grasp failures, AnyPart predicts a grasp location on the correct part 88.57 % of the time.
Human-in-the-Loop Segmentation of Multi-species Coral Imagery
Apr 16, 2024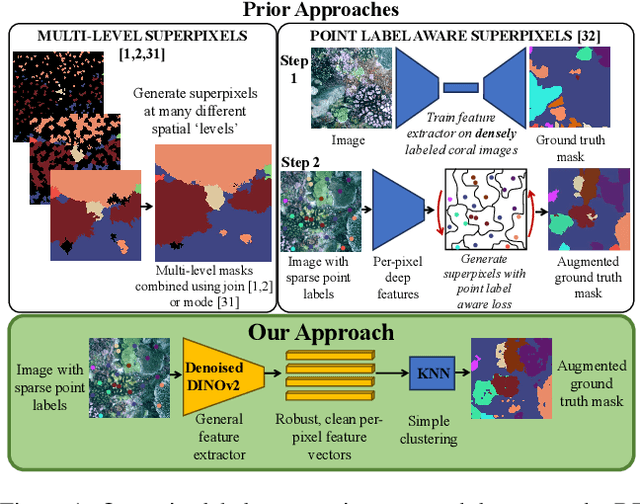
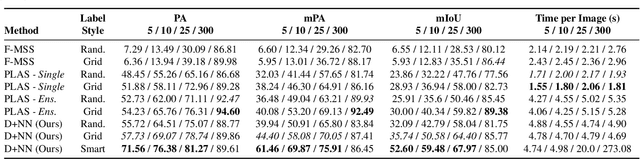
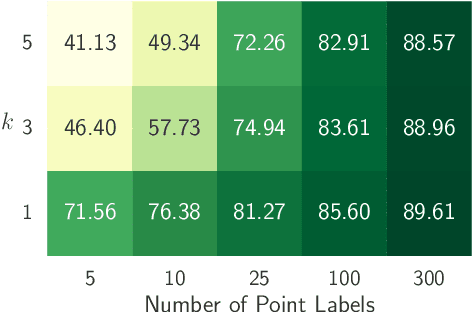

Broad-scale marine surveys performed by underwater vehicles significantly increase the availability of coral reef imagery, however it is costly and time-consuming for domain experts to label images. Point label propagation is an approach used to leverage existing image data labeled with sparse point labels. The resulting augmented ground truth generated is then used to train a semantic segmentation model. Here, we first demonstrate that recent advances in foundation models enable generation of multi-species coral augmented ground truth masks using denoised DINOv2 features and K-Nearest Neighbors (KNN), without the need for any pre-training or custom-designed algorithms. For extremely sparsely labeled images, we propose a labeling regime based on human-in-the-loop principles, resulting in significant improvement in annotation efficiency: If only 5 point labels per image are available, our proposed human-in-the-loop approach improves on the state-of-the-art by 17.3% for pixel accuracy and 22.6% for mIoU; and by 10.6% and 19.1% when 10 point labels per image are available. Even if the human-in-the-loop labeling regime is not used, the denoised DINOv2 features with a KNN outperforms the prior state-of-the-art by 3.5% for pixel accuracy and 5.7% for mIoU (5 grid points). We also provide a detailed analysis of how point labeling style and the quantity of points per image affects the point label propagation quality and provide general recommendations on maximizing point label efficiency.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.