 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Label Dependency for Underwater Scene Understanding: A Survey of Datasets, Techniques and Applications
Nov 18, 2024Underwater surveys provide long-term data for informing management strategies, monitoring coral reef health, and estimating blue carbon stocks. Advances in broad-scale survey methods, such as robotic underwater vehicles, have increased the range of marine surveys but generate large volumes of imagery requiring analysis. Computer vision methods such as semantic segmentation aid automated image analysis, but typically rely on fully supervised training with extensive labelled data. While ground truth label masks for tasks like street scene segmentation can be quickly and affordably generated by non-experts through crowdsourcing services like Amazon Mechanical Turk, ecology presents greater challenges. The complexity of underwater images, coupled with the specialist expertise needed to accurately identify species at the pixel level, makes this process costly, time-consuming, and heavily dependent on domain experts. In recent years, some works have performed automated analysis of underwater imagery, and a smaller number of studies have focused on weakly supervised approaches which aim to reduce the expert-provided labelled data required. This survey focuses on approaches which reduce dependency on human expert input, while reviewing the prior and related approaches to position these works in the wider field of underwater perception. Further, we offer an overview of coastal ecosystems and the challenges of underwater imagery. We provide background on weakly and self-supervised deep learning and integrate these elements into a taxonomy that centres on the intersection of underwater monitoring, computer vision, and deep learning, while motivating approaches for weakly supervised deep learning with reduced dependency on domain expert data annotations. Lastly, the survey examines available datasets and platforms, and identifies gaps, barriers, and opportunities for automating underwater surveys.
Temporal Attention for Cross-View Sequential Image Localization
Aug 28, 2024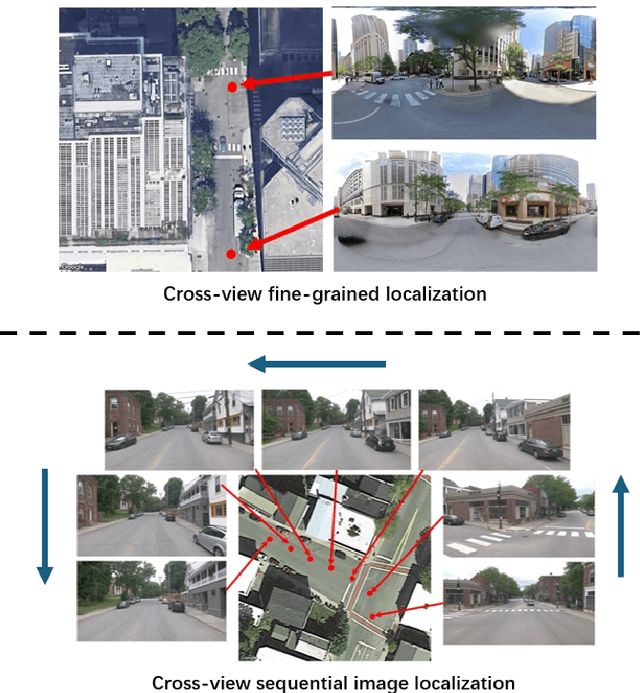
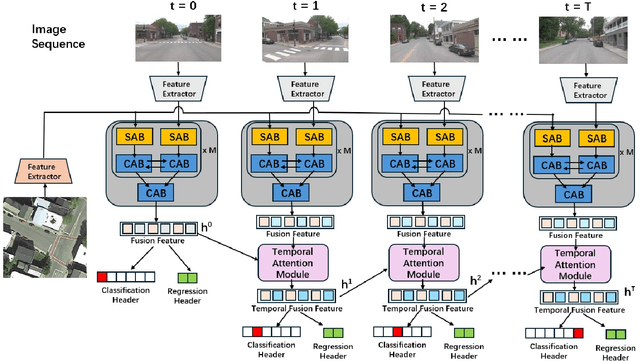
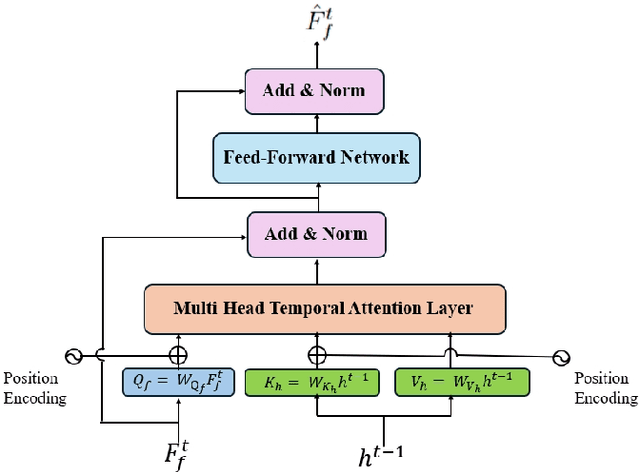

This paper introduces a novel approach to enhancing cross-view localization, focusing on the fine-grained, sequential localization of street-view images within a single known satellite image patch, a significant departure from traditional one-to-one image retrieval methods. By expanding to sequential image fine-grained localization, our model, equipped with a novel Temporal Attention Module (TAM), leverages contextual information to significantly improve sequential image localization accuracy. Our method shows substantial reductions in both mean and median localization errors on the Cross-View Image Sequence (CVIS) dataset, outperforming current state-of-the-art single-image localization techniques. Additionally, by adapting the KITTI-CVL dataset into sequential image sets, we not only offer a more realistic dataset for future research but also demonstrate our model's robust generalization capabilities across varying times and areas, evidenced by a 75.3% reduction in mean distance error in cross-view sequential image localization.
Human-in-the-Loop Segmentation of Multi-species Coral Imagery
Apr 16, 2024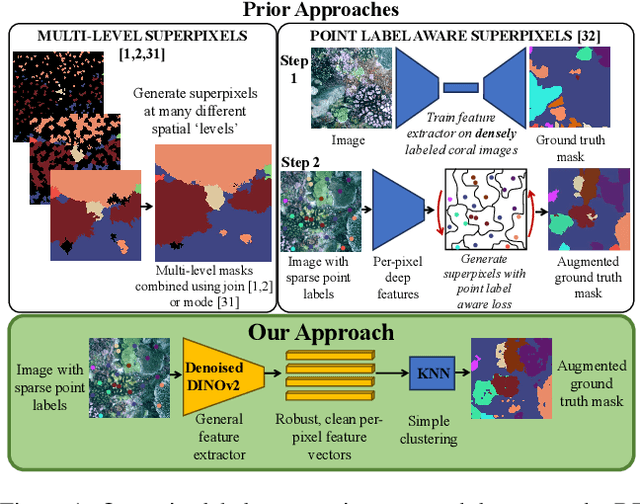
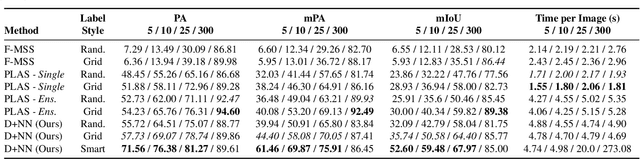
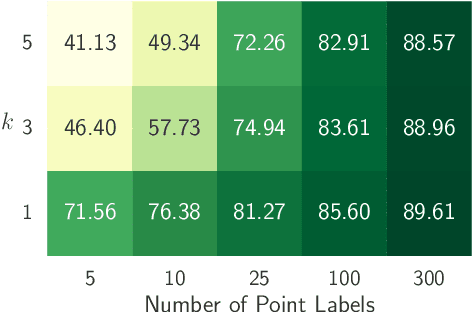

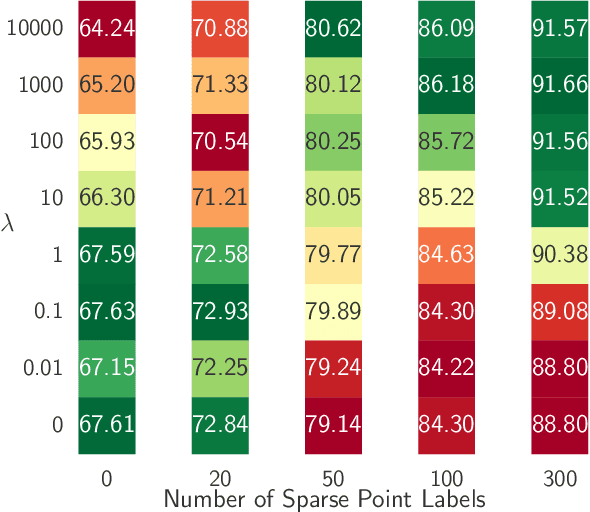
Broad-scale marine surveys performed by underwater vehicles significantly increase the availability of coral reef imagery, however it is costly and time-consuming for domain experts to label images. Point label propagation is an approach used to leverage existing image data labeled with sparse point labels. The resulting augmented ground truth generated is then used to train a semantic segmentation model. Here, we first demonstrate that recent advances in foundation models enable generation of multi-species coral augmented ground truth masks using denoised DINOv2 features and K-Nearest Neighbors (KNN), without the need for any pre-training or custom-designed algorithms. For extremely sparsely labeled images, we propose a labeling regime based on human-in-the-loop principles, resulting in significant improvement in annotation efficiency: If only 5 point labels per image are available, our proposed human-in-the-loop approach improves on the state-of-the-art by 17.3% for pixel accuracy and 22.6% for mIoU; and by 10.6% and 19.1% when 10 point labels per image are available. Even if the human-in-the-loop labeling regime is not used, the denoised DINOv2 features with a KNN outperforms the prior state-of-the-art by 3.5% for pixel accuracy and 5.7% for mIoU (5 grid points). We also provide a detailed analysis of how point labeling style and the quantity of points per image affects the point label propagation quality and provide general recommendations on maximizing point label efficiency.
Reducing Object Detection Uncertainty from RGB and Thermal Data for UAV Outdoor Surveillance
Aug 21, 2023

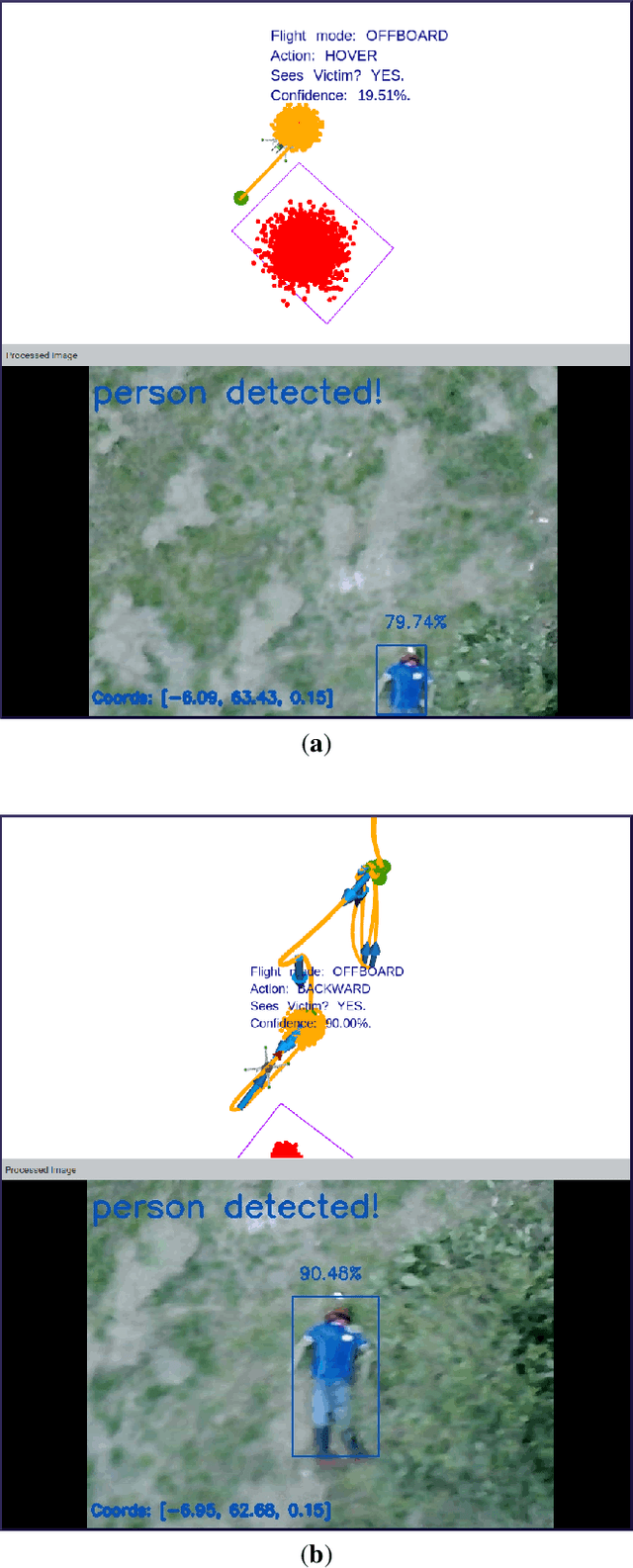
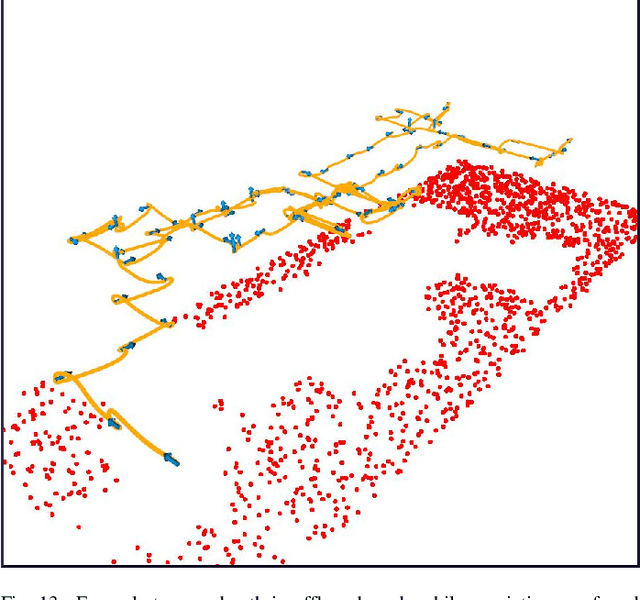
Recent advances in Unmanned Aerial Vehicles (UAVs) have resulted in their quick adoption for wide a range of civilian applications, including precision agriculture, biosecurity, disaster monitoring and surveillance. UAVs offer low-cost platforms with flexible hardware configurations, as well as an increasing number of autonomous capabilities, including take-off, landing, object tracking and obstacle avoidance. However, little attention has been paid to how UAVs deal with object detection uncertainties caused by false readings from vision-based detectors, data noise, vibrations, and occlusion. In most situations, the relevance and understanding of these detections are delegated to human operators, as many UAVs have limited cognition power to interact autonomously with the environment. This paper presents a framework for autonomous navigation under uncertainty in outdoor scenarios for small UAVs using a probabilistic-based motion planner. The framework is evaluated with real flight tests using a sub 2 kg quadrotor UAV and illustrated in victim finding Search and Rescue (SAR) case study in a forest/bushland. The navigation problem is modelled using a Partially Observable Markov Decision Process (POMDP), and solved in real time onboard the small UAV using Augmented Belief Trees (ABT) and the TAPIR toolkit. Results from experiments using colour and thermal imagery show that the proposed motion planner provides accurate victim localisation coordinates, as the UAV has the flexibility to interact with the environment and obtain clearer visualisations of any potential victims compared to the baseline motion planner. Incorporating this system allows optimised UAV surveillance operations by diminishing false positive readings from vision-based object detectors.
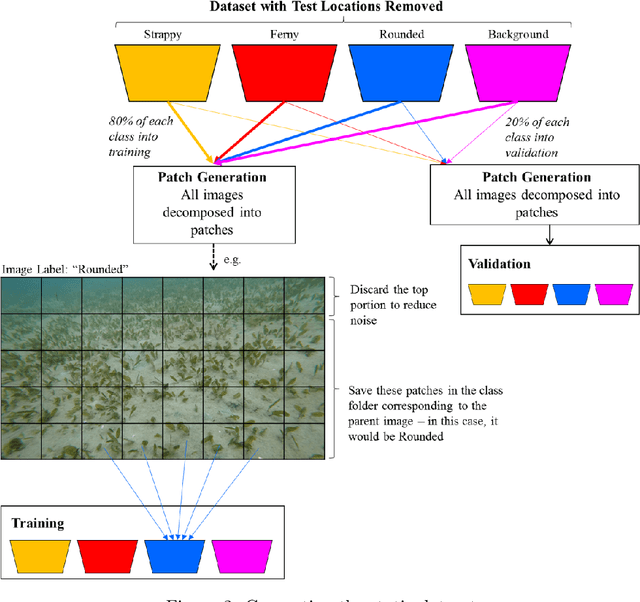
Image Labels Are All You Need for Coarse Seagrass Segmentation
Mar 02, 2023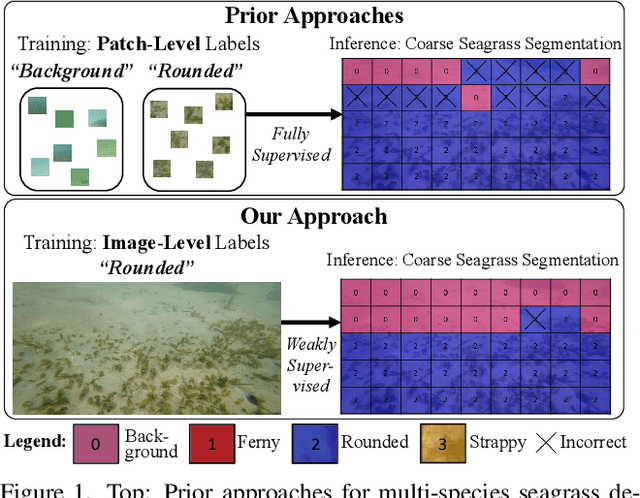
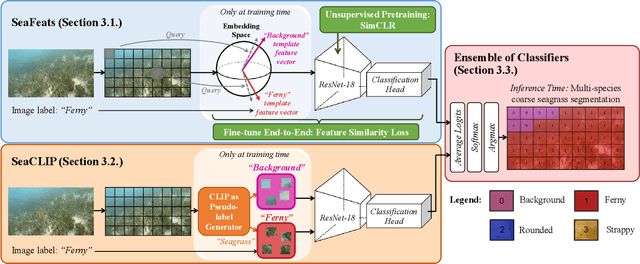
Seagrass meadows serve as critical carbon sinks, but accurately estimating the amount of carbon they store requires knowledge of the seagrass species present. Using underwater and surface vehicles equipped with machine learning algorithms can help to accurately estimate the composition and extent of seagrass meadows at scale. However, previous approaches for seagrass detection and classification have required full supervision from patch-level labels. In this paper, we reframe seagrass classification as a weakly supervised coarse segmentation problem where image-level labels are used during training (25 times fewer labels compared to patch-level labeling) and patch-level outputs are obtained at inference time. To this end, we introduce SeaFeats, an architecture that uses unsupervised contrastive pretraining and feature similarity to separate background and seagrass patches, and SeaCLIP, a model that showcases the effectiveness of large language models as a supervisory signal in domain-specific applications. We demonstrate that an ensemble of SeaFeats and SeaCLIP leads to highly robust performance, with SeaCLIP conservatively predicting the background class to avoid false seagrass misclassifications in blurry or dark patches. Our method outperforms previous approaches that require patch-level labels on the multi-species 'DeepSeagrass' dataset by 6.8% (absolute) for the class-weighted F1 score, and by 12.1% (absolute) F1 score for seagrass presence/absence on the 'Global Wetlands' dataset. We also present two case studies for real-world deployment: outlier detection on the Global Wetlands dataset, and application of our method on imagery collected by FloatyBoat, an autonomous surface vehicle.
Point Label Aware Superpixels for Multi-species Segmentation of Underwater Imagery
Feb 27, 2022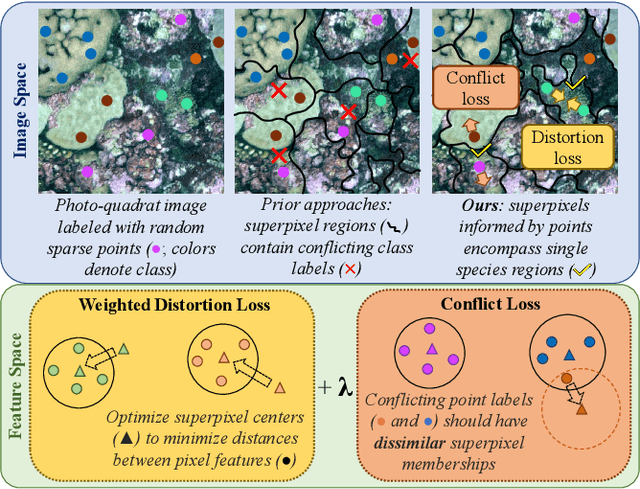
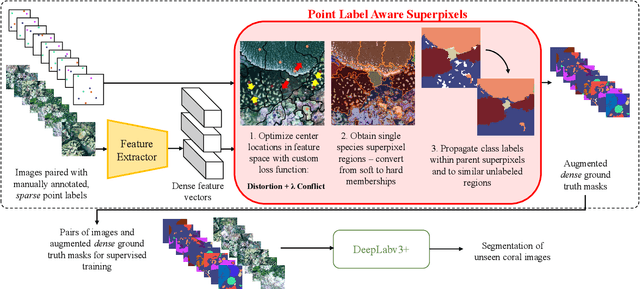
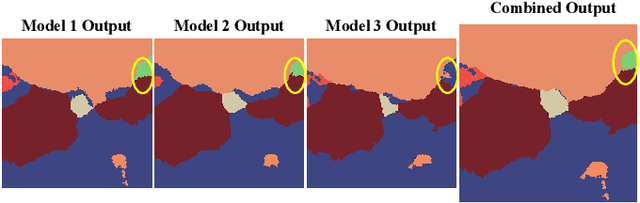
Monitoring coral reefs using underwater vehicles increases the range of marine surveys and availability of historical ecological data by collecting significant quantities of images. Analysis of this imagery can be automated using a model trained to perform semantic segmentation, however it is too costly and time-consuming to densely label images for training supervised models. In this letter, we leverage photo-quadrat imagery labeled by ecologists with sparse point labels. We propose a point label aware method for propagating labels within superpixel regions to obtain augmented ground truth for training a semantic segmentation model. Our point label aware superpixel method utilizes the sparse point labels, and clusters pixels using learned features to accurately generate single-species segments in cluttered, complex coral images. Our method outperforms prior methods on the UCSD Mosaics dataset by 3.62% for pixel accuracy and 8.35% for mean IoU for the label propagation task. Furthermore, our approach reduces computation time reported by previous approaches by 76%. We train a DeepLabv3+ architecture and outperform state-of-the-art for semantic segmentation by 2.91% for pixel accuracy and 9.65% for mean IoU on the UCSD Mosaics dataset and by 4.19% for pixel accuracy and 14.32% mean IoU for the Eilat dataset.
Going Deeper into Semi-supervised Person Re-identification
Jul 24, 2021
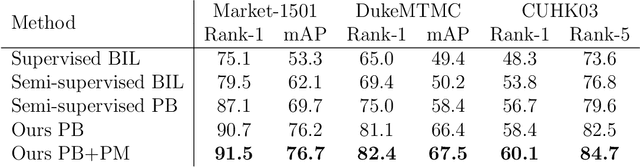
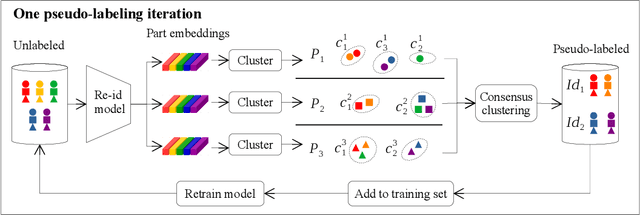

Person re-identification is the challenging task of identifying a person across different camera views. Training a convolutional neural network (CNN) for this task requires annotating a large dataset, and hence, it involves the time-consuming manual matching of people across cameras. To reduce the need for labeled data, we focus on a semi-supervised approach that requires only a subset of the training data to be labeled. We conduct a comprehensive survey in the area of person re-identification with limited labels. Existing works in this realm are limited in the sense that they utilize features from multiple CNNs and require the number of identities in the unlabeled data to be known. To overcome these limitations, we propose to employ part-based features from a single CNN without requiring the knowledge of the label space (i.e., the number of identities). This makes our approach more suitable for practical scenarios, and it significantly reduces the need for computational resources. We also propose a PartMixUp loss that improves the discriminative ability of learned part-based features for pseudo-labeling in semi-supervised settings. Our method outperforms the state-of-the-art results on three large-scale person re-id datasets and achieves the same level of performance as fully supervised methods with only one-third of labeled identities.
Learning and Executing Re-usable Behaviour Trees from Natural Language Instruction
Jun 03, 2021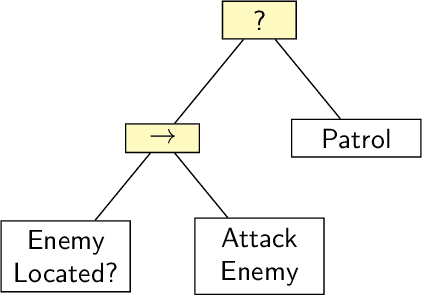


Domestic and service robots have the potential to transform industries such as health care and small-scale manufacturing, as well as the homes in which we live. However, due to the overwhelming variety of tasks these robots will be expected to complete, providing generic out-of-the-box solutions that meet the needs of every possible user is clearly intractable. To address this problem, robots must therefore not only be capable of learning how to complete novel tasks at run-time, but the solutions to these tasks must also be informed by the needs of the user. In this paper we demonstrate how behaviour trees, a well established control architecture in the fields of gaming and robotics, can be used in conjunction with natural language instruction to provide a robust and modular control architecture for instructing autonomous agents to learn and perform novel complex tasks. We also show how behaviour trees generated using our approach can be generalised to novel scenarios, and can be re-used in future learning episodes to create increasingly complex behaviours. We validate this work against an existing corpus of natural language instructions, demonstrate the application of our approach on both a simulated robot solving a toy problem, as well as two distinct real-world robot platforms which, respectively, complete a block sorting scenario, and a patrol scenario.
DeepSeagrass Dataset
Mar 09, 2021
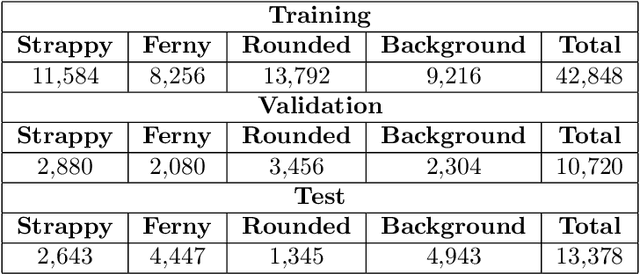

We introduce a dataset of seagrass images collected by a biologist snorkelling in Moreton Bay, Queensland, Australia, as described in our publication: arXiv:2009.09924. The images are labelled at the image-level by collecting images of the same morphotype in a folder hierarchy. We also release pre-trained models and training codes for detection and classification of seagrass species at the patch level at https://github.com/csiro-robotics/deepseagrass.
Semi-supervised Keypoint Localization
Jan 20, 2021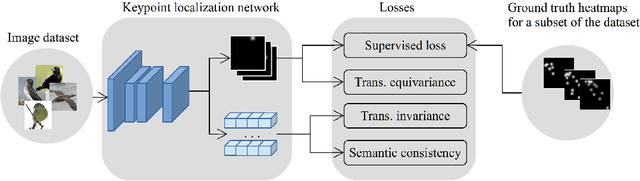
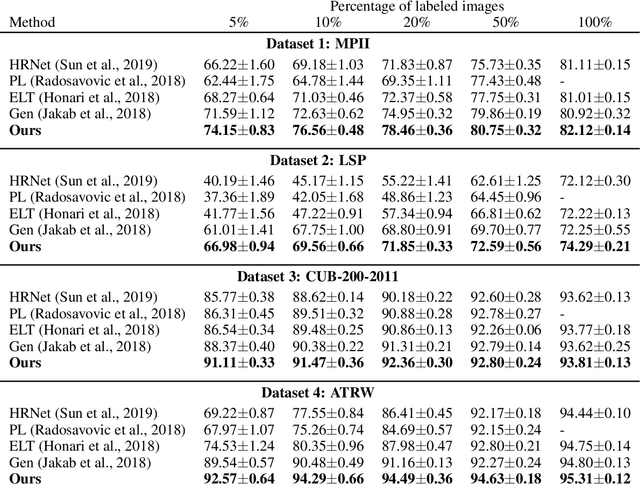
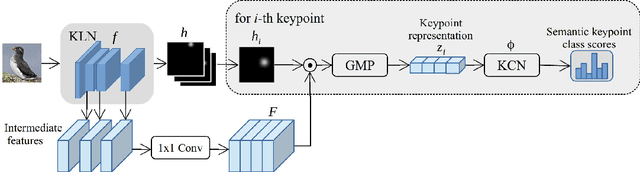
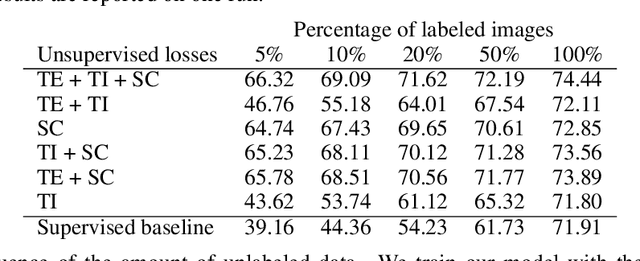
Knowledge about the locations of keypoints of an object in an image can assist in fine-grained classification and identification tasks, particularly for the case of objects that exhibit large variations in poses that greatly influence their visual appearance, such as wild animals. However, supervised training of a keypoint detection network requires annotating a large image dataset for each animal species, which is a labor-intensive task. To reduce the need for labeled data, we propose to learn simultaneously keypoint heatmaps and pose invariant keypoint representations in a semi-supervised manner using a small set of labeled images along with a larger set of unlabeled images. Keypoint representations are learnt with a semantic keypoint consistency constraint that forces the keypoint detection network to learn similar features for the same keypoint across the dataset. Pose invariance is achieved by making keypoint representations for the image and its augmented copies closer together in feature space. Our semi-supervised approach significantly outperforms previous methods on several benchmarks for human and animal body landmark localization.