 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixi: Unified Software Development and Distribution for Robotics and AI
Nov 06, 2025The reproducibility crisis in scientific computing constrains robotics research. Existing studies reveal that up to 70% of robotics algorithms cannot be reproduced by independent teams, while many others fail to reach deployment because creating shareable software environments remains prohibitively complex. These challenges stem from fragmented, multi-language, and hardware-software toolchains that lead to dependency hell. We present Pixi, a unified package-management framework that addresses these issues by capturing exact dependency states in project-level lockfiles, ensuring bit-for-bit reproducibility across platforms. Its high-performance SAT solver achieves up to 10x faster dependency resolution than comparable tools, while integration of the conda-forge and PyPI ecosystems removes the need for multiple managers. Adopted in over 5,300 projects since 2023, Pixi reduces setup times from hours to minutes and lowers technical barriers for researchers worldwide. By enabling scalable, reproducible, collaborative research infrastructure, Pixi accelerates progress in robotics and AI.
Are All Marine Species Created Equal? Performance Disparities in Underwater Object Detection
Aug 26, 2025



Underwater object detection is critical for monitoring marine ecosystems but poses unique challenges, including degraded image quality, imbalanced class distribution, and distinct visual characteristics. Not every species is detected equally well, yet underlying causes remain unclear. We address two key research questions: 1) What factors beyond data quantity drive class-specific performance disparities? 2) How can we systematically improve detection of under-performing marine species? We manipulate the DUO dataset to separate the object detection task into localization and classification and investigate the under-performance of the scallop class. Localization analysis using YOLO11 and TIDE finds that foreground-background discrimination is the most problematic stage regardless of data quantity. Classification experiments reveal persistent precision gaps even with balanced data, indicating intrinsic feature-based challenges beyond data scarcity and inter-class dependencies. We recommend imbalanced distributions when prioritizing precision, and balanced distributions when prioritizing recall. Improving under-performing classes should focus on algorithmic advances, especially within localization modules. We publicly release our code and datasets.
Reducing Label Dependency for Underwater Scene Understanding: A Survey of Datasets, Techniques and Applications
Nov 18, 2024Underwater surveys provide long-term data for informing management strategies, monitoring coral reef health, and estimating blue carbon stocks. Advances in broad-scale survey methods, such as robotic underwater vehicles, have increased the range of marine surveys but generate large volumes of imagery requiring analysis. Computer vision methods such as semantic segmentation aid automated image analysis, but typically rely on fully supervised training with extensive labelled data. While ground truth label masks for tasks like street scene segmentation can be quickly and affordably generated by non-experts through crowdsourcing services like Amazon Mechanical Turk, ecology presents greater challenges. The complexity of underwater images, coupled with the specialist expertise needed to accurately identify species at the pixel level, makes this process costly, time-consuming, and heavily dependent on domain experts. In recent years, some works have performed automated analysis of underwater imagery, and a smaller number of studies have focused on weakly supervised approaches which aim to reduce the expert-provided labelled data required. This survey focuses on approaches which reduce dependency on human expert input, while reviewing the prior and related approaches to position these works in the wider field of underwater perception. Further, we offer an overview of coastal ecosystems and the challenges of underwater imagery. We provide background on weakly and self-supervised deep learning and integrate these elements into a taxonomy that centres on the intersection of underwater monitoring, computer vision, and deep learning, while motivating approaches for weakly supervised deep learning with reduced dependency on domain expert data annotations. Lastly, the survey examines available datasets and platforms, and identifies gaps, barriers, and opportunities for automating underwater surveys.
Human-in-the-Loop Segmentation of Multi-species Coral Imagery
Apr 16, 2024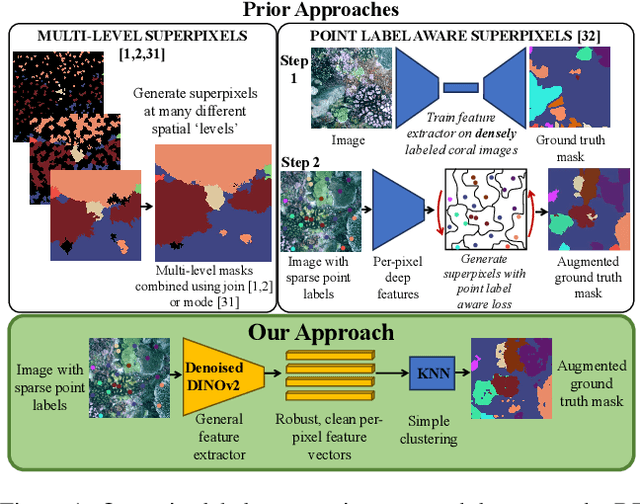
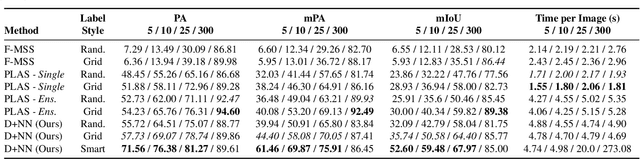
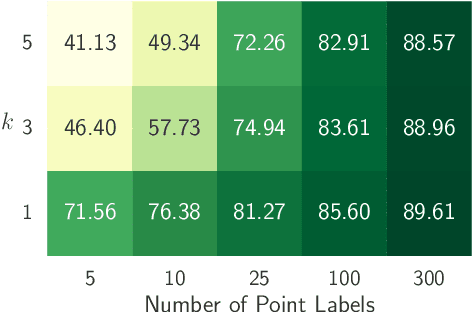

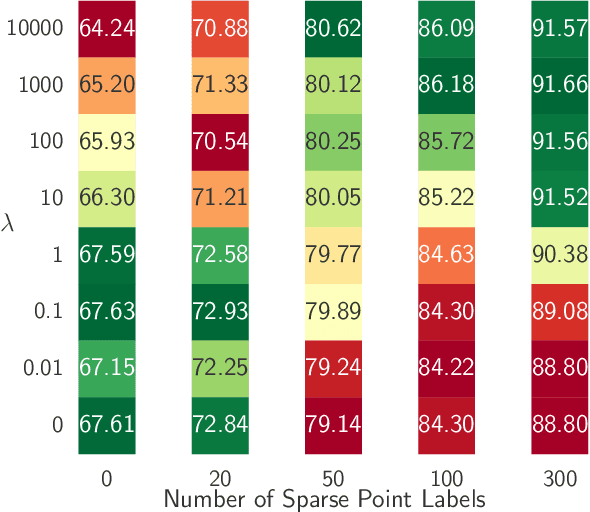
Broad-scale marine surveys performed by underwater vehicles significantly increase the availability of coral reef imagery, however it is costly and time-consuming for domain experts to label images. Point label propagation is an approach used to leverage existing image data labeled with sparse point labels. The resulting augmented ground truth generated is then used to train a semantic segmentation model. Here, we first demonstrate that recent advances in foundation models enable generation of multi-species coral augmented ground truth masks using denoised DINOv2 features and K-Nearest Neighbors (KNN), without the need for any pre-training or custom-designed algorithms. For extremely sparsely labeled images, we propose a labeling regime based on human-in-the-loop principles, resulting in significant improvement in annotation efficiency: If only 5 point labels per image are available, our proposed human-in-the-loop approach improves on the state-of-the-art by 17.3% for pixel accuracy and 22.6% for mIoU; and by 10.6% and 19.1% when 10 point labels per image are available. Even if the human-in-the-loop labeling regime is not used, the denoised DINOv2 features with a KNN outperforms the prior state-of-the-art by 3.5% for pixel accuracy and 5.7% for mIoU (5 grid points). We also provide a detailed analysis of how point labeling style and the quantity of points per image affects the point label propagation quality and provide general recommendations on maximizing point label efficiency.
Image Labels Are All You Need for Coarse Seagrass Segmentation
Mar 02, 2023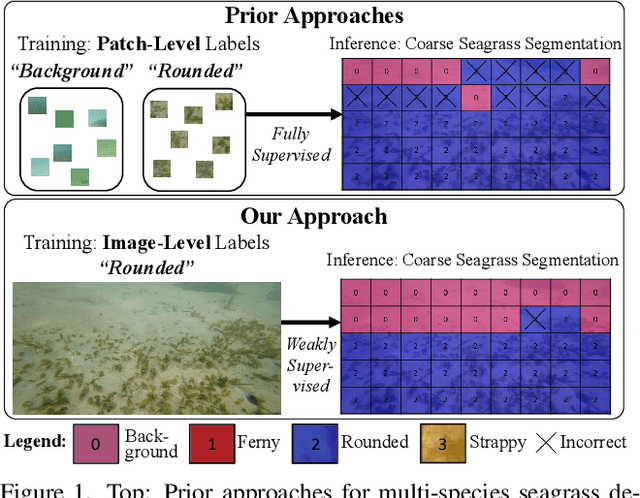
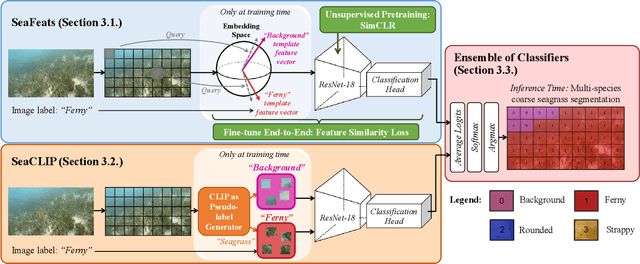
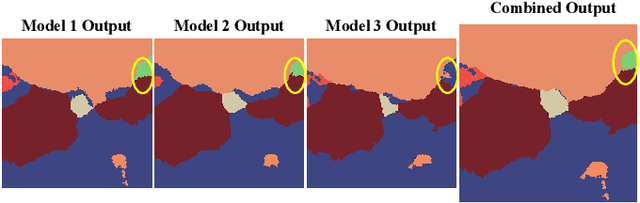
Seagrass meadows serve as critical carbon sinks, but accurately estimating the amount of carbon they store requires knowledge of the seagrass species present. Using underwater and surface vehicles equipped with machine learning algorithms can help to accurately estimate the composition and extent of seagrass meadows at scale. However, previous approaches for seagrass detection and classification have required full supervision from patch-level labels. In this paper, we reframe seagrass classification as a weakly supervised coarse segmentation problem where image-level labels are used during training (25 times fewer labels compared to patch-level labeling) and patch-level outputs are obtained at inference time. To this end, we introduce SeaFeats, an architecture that uses unsupervised contrastive pretraining and feature similarity to separate background and seagrass patches, and SeaCLIP, a model that showcases the effectiveness of large language models as a supervisory signal in domain-specific applications. We demonstrate that an ensemble of SeaFeats and SeaCLIP leads to highly robust performance, with SeaCLIP conservatively predicting the background class to avoid false seagrass misclassifications in blurry or dark patches. Our method outperforms previous approaches that require patch-level labels on the multi-species 'DeepSeagrass' dataset by 6.8% (absolute) for the class-weighted F1 score, and by 12.1% (absolute) F1 score for seagrass presence/absence on the 'Global Wetlands' dataset. We also present two case studies for real-world deployment: outlier detection on the Global Wetlands dataset, and application of our method on imagery collected by FloatyBoat, an autonomous surface vehicle.
Point Label Aware Superpixels for Multi-species Segmentation of Underwater Imagery
Feb 27, 2022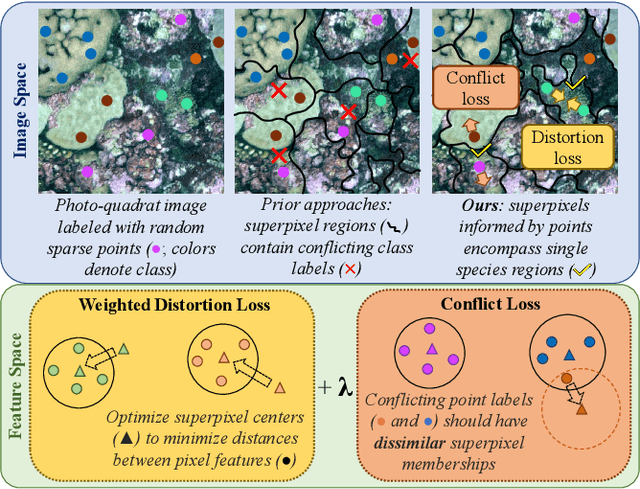
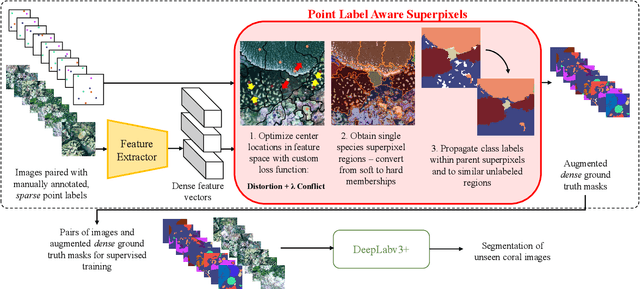
Monitoring coral reefs using underwater vehicles increases the range of marine surveys and availability of historical ecological data by collecting significant quantities of images. Analysis of this imagery can be automated using a model trained to perform semantic segmentation, however it is too costly and time-consuming to densely label images for training supervised models. In this letter, we leverage photo-quadrat imagery labeled by ecologists with sparse point labels. We propose a point label aware method for propagating labels within superpixel regions to obtain augmented ground truth for training a semantic segmentation model. Our point label aware superpixel method utilizes the sparse point labels, and clusters pixels using learned features to accurately generate single-species segments in cluttered, complex coral images. Our method outperforms prior methods on the UCSD Mosaics dataset by 3.62% for pixel accuracy and 8.35% for mean IoU for the label propagation task. Furthermore, our approach reduces computation time reported by previous approaches by 76%. We train a DeepLabv3+ architecture and outperform state-of-the-art for semantic segmentation by 2.91% for pixel accuracy and 9.65% for mean IoU on the UCSD Mosaics dataset and by 4.19% for pixel accuracy and 14.32% mean IoU for the Eilat dataset.
DeepSeagrass Dataset
Mar 09, 2021
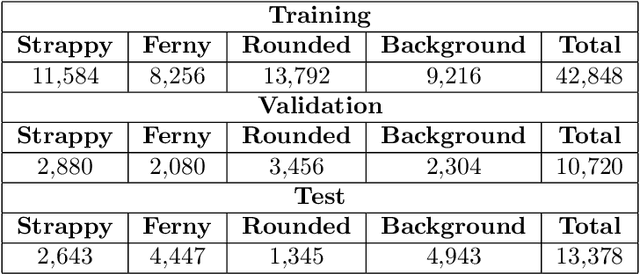
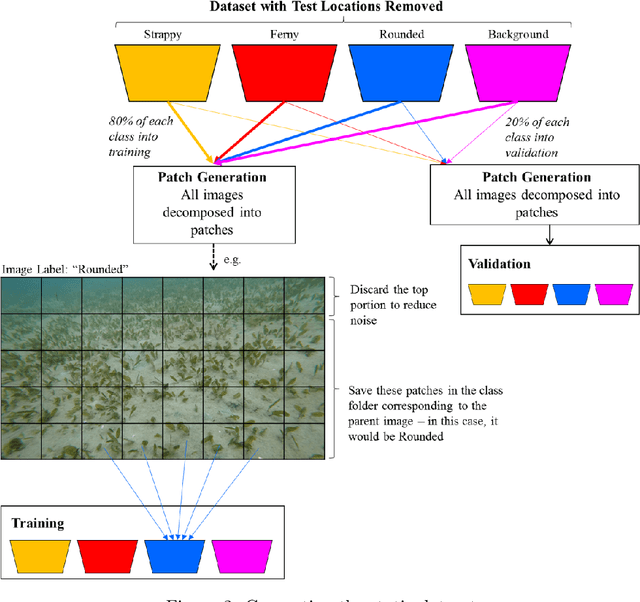

We introduce a dataset of seagrass images collected by a biologist snorkelling in Moreton Bay, Queensland, Australia, as described in our publication: arXiv:2009.09924. The images are labelled at the image-level by collecting images of the same morphotype in a folder hierarchy. We also release pre-trained models and training codes for detection and classification of seagrass species at the patch level at https://github.com/csiro-robotics/deepseagrass.
Multi-species Seagrass Detection and Classification from Underwater Images
Sep 18, 2020
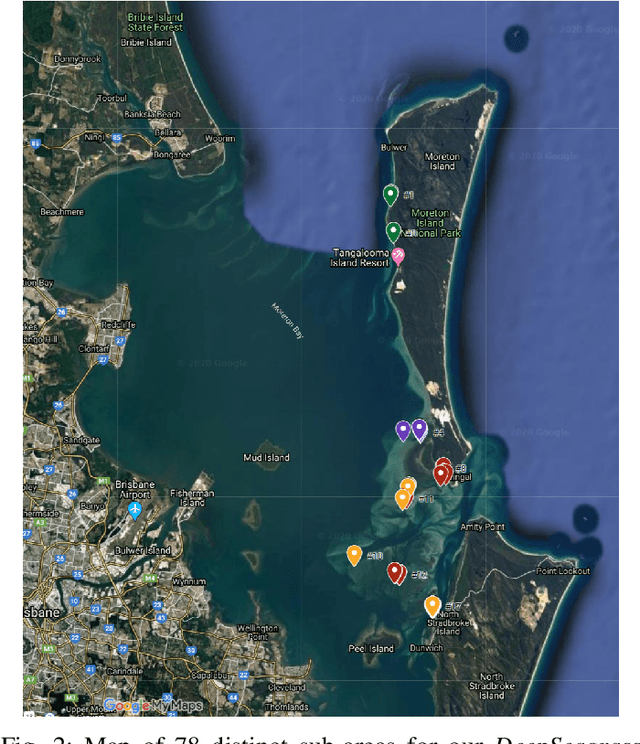
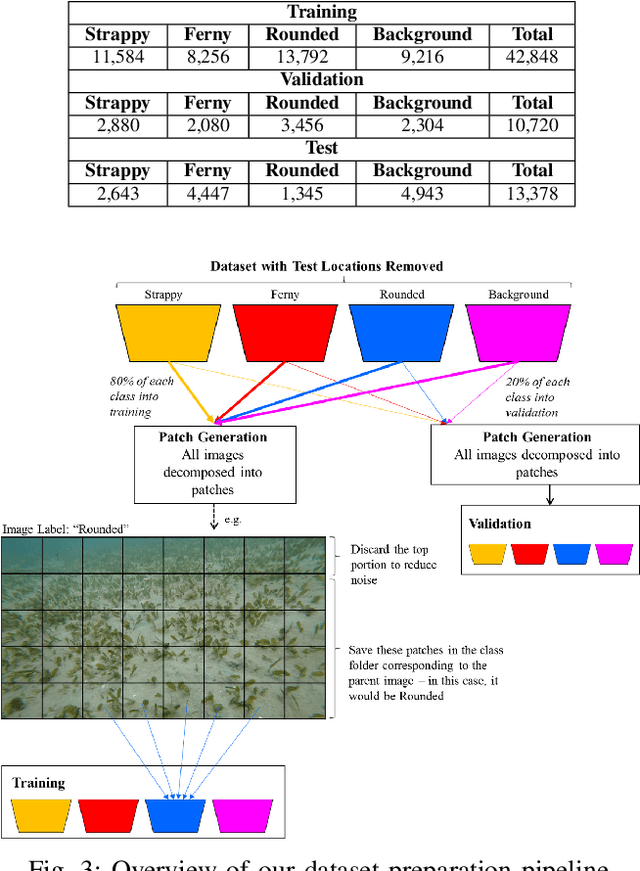

Underwater surveys conducted using divers or robots equipped with customized camera payloads can generate a large number of images. Manual review of these images to extract ecological data is prohibitive in terms of time and cost, thus providing strong incentive to automate this process using machine learning solutions. In this paper, we introduce a multi-species detector and classifier for seagrasses based on a deep convolutional neural network (achieved an overall accuracy of 92.4%). We also introduce a simple method to semi-automatically label image patches and therefore minimize manual labelling requirement. We describe and release publicly the dataset collected in this study as well as the code and pre-trained models to replicate our experiments at: https://github.com/csiro-robotics/deepseagrass