 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtiFixer: Enhancing and Extending 3D Reconstruction with Auto-Regressive Diffusion Models
Feb 28, 2026Per-scene optimization methods such as 3D Gaussian Splatting provide state-of-the-art novel view synthesis quality but extrapolate poorly to under-observed areas. Methods that leverage generative priors to correct artifacts in these areas hold promise but currently suffer from two shortcomings. The first is scalability, as existing methods use image diffusion models or bidirectional video models that are limited in the number of views they can generate in a single pass (and thus require a costly iterative distillation process for consistency). The second is quality itself, as generators used in prior work tend to produce outputs that are inconsistent with existing scene content and fail entirely in completely unobserved regions. To solve these, we propose a two-stage pipeline that leverages two key insights. First, we train a powerful bidirectional generative model with a novel opacity mixing strategy that encourages consistency with existing observations while retaining the model's ability to extrapolate novel content in unseen areas. Second, we distill it into a causal auto-regressive model that generates hundreds of frames in a single pass. This model can directly produce novel views or serve as pseudo-supervision to improve the underlying 3D representation in a simple and highly efficient manner. We evaluate our method extensively and demonstrate that it can generate plausible reconstructions in scenarios where existing approaches fail completely. When measured on commonly benchmarked datasets, we outperform existing all existing baselines by a wide margin, exceeding prior state-of-the-art methods by 1-3 dB PSNR.
Automatic Map Density Selection for Locally-Performant Visual Place Recognition
Feb 25, 2026A key challenge in translating Visual Place Recognition (VPR) from the lab to long-term deployment is ensuring a priori that a system can meet user-specified performance requirements across different parts of an environment, rather than just on average globally. A critical mechanism for controlling local VPR performance is the density of the reference mapping database, yet this factor is largely neglected in existing work, where benchmark datasets with fixed, engineering-driven (sensors, storage, GPS frequency) sampling densities are typically used. In this paper, we propose a dynamic VPR mapping approach that uses pairs of reference traverses from the target environment to automatically select an appropriate map density to satisfy two user-defined requirements: (1) a target Local Recall@1 level, and (2) the proportion of the operational environment over which this requirement must be met or exceeded, which we term the Recall Achievement Rate (RAR). Our approach is based on the hypothesis that match patterns between multiple reference traverses, evaluated across different map densities, can be modelled to predict the density required to meet these performance targets on unseen deployment data. Through extensive experiments across multiple VPR methods and the Nordland and Oxford RobotCar benchmarks, we show that our system consistently achieves or exceeds the specified local recall level over at least the user-specified proportion of the environment. Comparisons with alternative baselines demonstrate that our approach reliably selects the correct operating point in map density, avoiding unnecessary over-densification. Finally, ablation studies and analysis evaluate sensitivity to reference map choice and local space definitions, and reveal that conventional global Recall@1 is a poor predictor of the often more operationally meaningful RAR metric.
Long-Term Multi-Session 3D Reconstruction Under Substantial Appearance Change
Feb 24, 2026Long-term environmental monitoring requires the ability to reconstruct and align 3D models across repeated site visits separated by months or years. However, existing Structure-from-Motion (SfM) pipelines implicitly assume near-simultaneous image capture and limited appearance change, and therefore fail when applied to long-term monitoring scenarios such as coral reef surveys, where substantial visual and structural change is common. In this paper, we show that the primary limitation of current approaches lies in their reliance on post-hoc alignment of independently reconstructed sessions, which is insufficient under large temporal appearance change. We address this limitation by enforcing cross-session correspondences directly within a joint SfM reconstruction. Our approach combines complementary handcrafted and learned visual features to robustly establish correspondences across large temporal gaps, enabling the reconstruction of a single coherent 3D model from imagery captured years apart, where standard independent and joint SfM pipelines break down. We evaluate our method on long-term coral reef datasets exhibiting significant real-world change, and demonstrate consistent joint reconstruction across sessions in cases where existing methods fail to produce coherent reconstructions. To ensure scalability to large datasets, we further restrict expensive learned feature matching to a small set of likely cross-session image pairs identified via visual place recognition, which reduces computational cost and improves alignment robustness.
Quantile Transfer for Reliable Operating Point Selection in Visual Place Recognition
Feb 04, 2026Visual Place Recognition (VPR) is a key component for localisation in GNSS-denied environments, but its performance critically depends on selecting an image matching threshold (operating point) that balances precision and recall. Thresholds are typically hand-tuned offline for a specific environment and fixed during deployment, leading to degraded performance under environmental change. We propose a method that, given a user-defined precision requirement, automatically selects the operating point of a VPR system to maximise recall. The method uses a small calibration traversal with known correspondences and transfers thresholds to deployment via quantile normalisation of similarity score distributions. This quantile transfer ensures that thresholds remain stable across calibration sizes and query subsets, making the method robust to sampling variability. Experiments with multiple state-of-the-art VPR techniques and datasets show that the proposed approach consistently outperforms the state-of-the-art, delivering up to 25% higher recall in high-precision operating regimes. The method eliminates manual tuning by adapting to new environments and generalising across operating conditions. Our code will be released upon acceptance.
Robust Scene Coordinate Regression via Geometrically-Consistent Global Descriptors
Dec 19, 2025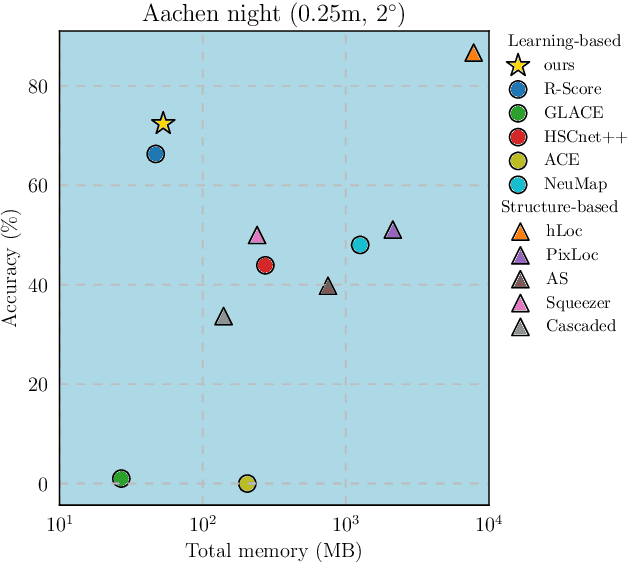
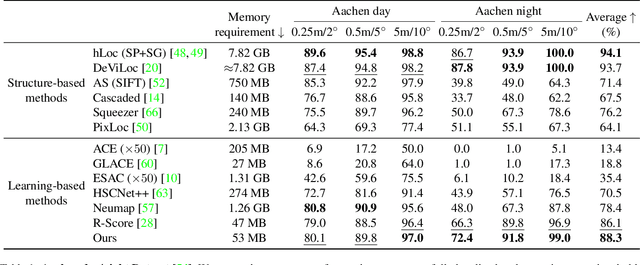
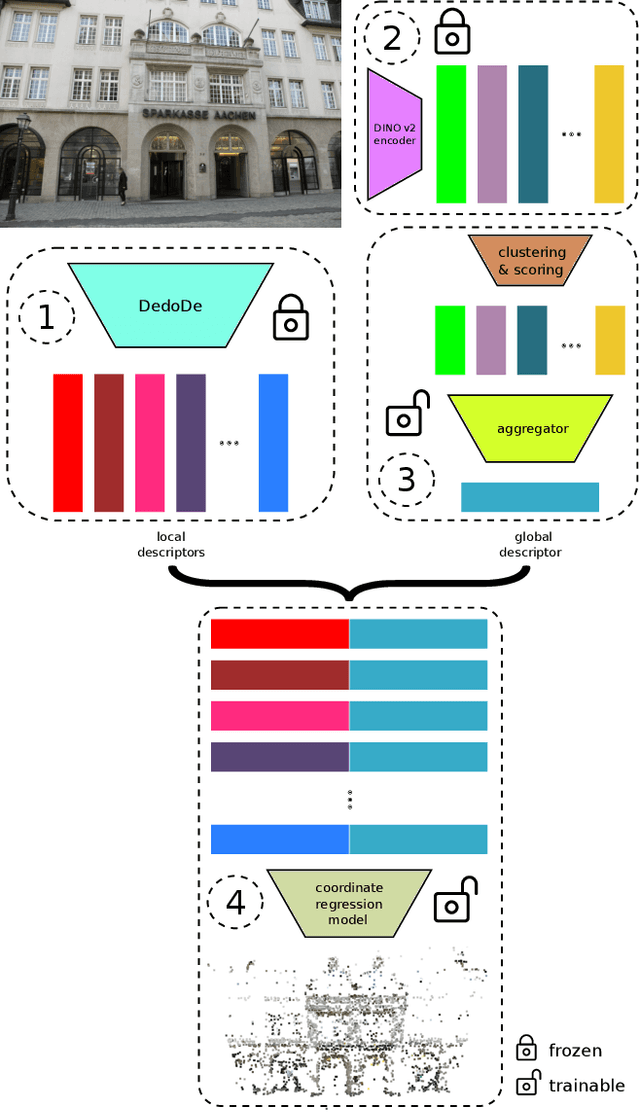
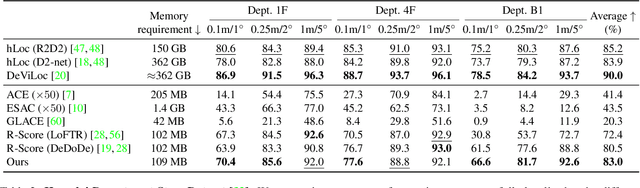
Recent learning-based visual localization methods use global descriptors to disambiguate visually similar places, but existing approaches often derive these descriptors from geometric cues alone (e.g., covisibility graphs), limiting their discriminative power and reducing robustness in the presence of noisy geometric constraints. We propose an aggregator module that learns global descriptors consistent with both geometrical structure and visual similarity, ensuring that images are close in descriptor space only when they are visually similar and spatially connected. This corrects erroneous associations caused by unreliable overlap scores. Using a batch-mining strategy based solely on the overlap scores and a modified contrastive loss, our method trains without manual place labels and generalizes across diverse environments. Experiments on challenging benchmarks show substantial localization gains in large-scale environments while preserving computational and memory efficiency. Code is available at \href{https://github.com/sontung/robust\_scr}{github.com/sontung/robust\_scr}.
ReMoSPLAT: Reactive Mobile Manipulation Control on a Gaussian Splat
Dec 10, 2025
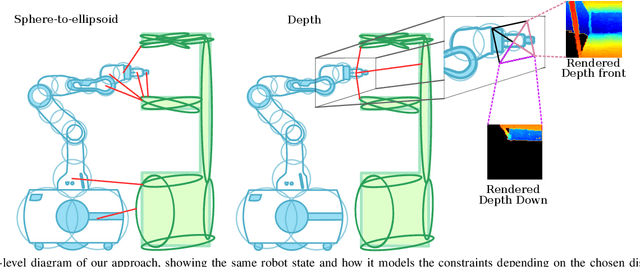

Reactive control can gracefully coordinate the motion of the base and the arm of a mobile manipulator. However, incorporating an accurate representation of the environment to avoid obstacles without involving costly planning remains a challenge. In this work, we present ReMoSPLAT, a reactive controller based on a quadratic program formulation for mobile manipulation that leverages a Gaussian Splat representation for collision avoidance. By integrating additional constraints and costs into the optimisation formulation, a mobile manipulator platform can reach its intended end effector pose while avoiding obstacles, even in cluttered scenes. We investigate the trade-offs of two methods for efficiently calculating robot-obstacle distances, comparing a purely geometric approach with a rasterisation-based approach. Our experiments in simulation on both synthetic and real-world scans demonstrate the feasibility of our method, showing that the proposed approach achieves performance comparable to controllers that rely on perfect ground-truth information.
Going Places: Place Recognition in Artificial and Natural Systems
Nov 18, 2025

Place recognition, the ability to identify previously visited locations, is critical for both biological navigation and autonomous systems. This review synthesizes findings from robotic systems, animal studies, and human research to explore how different systems encode and recall place. We examine the computational and representational strategies employed across artificial systems, animals, and humans, highlighting convergent solutions such as topological mapping, cue integration, and memory management. Animal systems reveal evolved mechanisms for multimodal navigation and environmental adaptation, while human studies provide unique insights into semantic place concepts, cultural influences, and introspective capabilities. Artificial systems showcase scalable architectures and data-driven models. We propose a unifying set of concepts by which to consider and develop place recognition mechanisms and identify key challenges such as generalization, robustness, and environmental variability. This review aims to foster innovations in artificial localization by connecting future developments in artificial place recognition systems to insights from both animal navigation research and human spatial cognition studies.
Pixi: Unified Software Development and Distribution for Robotics and AI
Nov 06, 2025The reproducibility crisis in scientific computing constrains robotics research. Existing studies reveal that up to 70% of robotics algorithms cannot be reproduced by independent teams, while many others fail to reach deployment because creating shareable software environments remains prohibitively complex. These challenges stem from fragmented, multi-language, and hardware-software toolchains that lead to dependency hell. We present Pixi, a unified package-management framework that addresses these issues by capturing exact dependency states in project-level lockfiles, ensuring bit-for-bit reproducibility across platforms. Its high-performance SAT solver achieves up to 10x faster dependency resolution than comparable tools, while integration of the conda-forge and PyPI ecosystems removes the need for multiple managers. Adopted in over 5,300 projects since 2023, Pixi reduces setup times from hours to minutes and lowers technical barriers for researchers worldwide. By enabling scalable, reproducible, collaborative research infrastructure, Pixi accelerates progress in robotics and AI.
Event-LAB: Towards Standardized Evaluation of Neuromorphic Localization Methods
Sep 18, 2025Event-based localization research and datasets are a rapidly growing area of interest, with a tenfold increase in the cumulative total number of published papers on this topic over the past 10 years. Whilst the rapid expansion in the field is exciting, it brings with it an associated challenge: a growth in the variety of required code and package dependencies as well as data formats, making comparisons difficult and cumbersome for researchers to implement reliably. To address this challenge, we present Event-LAB: a new and unified framework for running several event-based localization methodologies across multiple datasets. Event-LAB is implemented using the Pixi package and dependency manager, that enables a single command-line installation and invocation for combinations of localization methods and datasets. To demonstrate the capabilities of the framework, we implement two common event-based localization pipelines: Visual Place Recognition (VPR) and Simultaneous Localization and Mapping (SLAM). We demonstrate the ability of the framework to systematically visualize and analyze the results of multiple methods and datasets, revealing key insights such as the association of parameters that control event collection counts and window sizes for frame generation to large variations in performance. The results and analysis demonstrate the importance of fairly comparing methodologies with consistent event image generation parameters. Our Event-LAB framework provides this ability for the research community, by contributing a streamlined workflow for easily setting up multiple conditions.
Are All Marine Species Created Equal? Performance Disparities in Underwater Object Detection
Aug 26, 2025



Underwater object detection is critical for monitoring marine ecosystems but poses unique challenges, including degraded image quality, imbalanced class distribution, and distinct visual characteristics. Not every species is detected equally well, yet underlying causes remain unclear. We address two key research questions: 1) What factors beyond data quantity drive class-specific performance disparities? 2) How can we systematically improve detection of under-performing marine species? We manipulate the DUO dataset to separate the object detection task into localization and classification and investigate the under-performance of the scallop class. Localization analysis using YOLO11 and TIDE finds that foreground-background discrimination is the most problematic stage regardless of data quantity. Classification experiments reveal persistent precision gaps even with balanced data, indicating intrinsic feature-based challenges beyond data scarcity and inter-class dependencies. We recommend imbalanced distributions when prioritizing precision, and balanced distributions when prioritizing recall. Improving under-performing classes should focus on algorithmic advances, especially within localization modules. We publicly release our code and datasets.