 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowR: Flowing from Sparse to Dense 3D Reconstructions
Apr 02, 2025



3D Gaussian splatting enables high-quality novel view synthesis (NVS) at real-time frame rates. However, its quality drops sharply as we depart from the training views. Thus, dense captures are needed to match the high-quality expectations of some applications, e.g. Virtual Reality (VR). However, such dense captures are very laborious and expensive to obtain. Existing works have explored using 2D generative models to alleviate this requirement by distillation or generating additional training views. These methods are often conditioned only on a handful of reference input views and thus do not fully exploit the available 3D information, leading to inconsistent generation results and reconstruction artifacts. To tackle this problem, we propose a multi-view, flow matching model that learns a flow to connect novel view renderings from possibly sparse reconstructions to renderings that we expect from dense reconstructions. This enables augmenting scene captures with novel, generated views to improve reconstruction quality. Our model is trained on a novel dataset of 3.6M image pairs and can process up to 45 views at 540x960 resolution (91K tokens) on one H100 GPU in a single forward pass. Our pipeline consistently improves NVS in sparse- and dense-view scenarios, leading to higher-quality reconstructions than prior works across multiple, widely-used NVS benchmarks.
Hardware-Rasterized Ray-Based Gaussian Splatting
Mar 24, 2025



We present a novel, hardware rasterized rendering approach for ray-based 3D Gaussian Splatting (RayGS), obtaining both fast and high-quality results for novel view synthesis. Our work contains a mathematically rigorous and geometrically intuitive derivation about how to efficiently estimate all relevant quantities for rendering RayGS models, structured with respect to standard hardware rasterization shaders. Our solution is the first enabling rendering RayGS models at sufficiently high frame rates to support quality-sensitive applications like Virtual and Mixed Reality. Our second contribution enables alias-free rendering for RayGS, by addressing MIP-related issues arising when rendering diverging scales during training and testing. We demonstrate significant performance gains, across different benchmark scenes, while retaining state-of-the-art appearance quality of RayGS.
A Recipe for Generating 3D Worlds From a Single Image
Mar 20, 2025

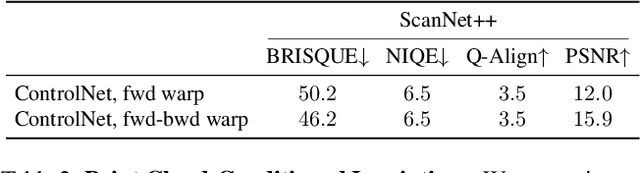

We introduce a recipe for generating immersive 3D worlds from a single image by framing the task as an in-context learning problem for 2D inpainting models. This approach requires minimal training and uses existing generative models. Our process involves two steps: generating coherent panoramas using a pre-trained diffusion model and lifting these into 3D with a metric depth estimator. We then fill unobserved regions by conditioning the inpainting model on rendered point clouds, requiring minimal fine-tuning. Tested on both synthetic and real images, our method produces high-quality 3D environments suitable for VR display. By explicitly modeling the 3D structure of the generated environment from the start, our approach consistently outperforms state-of-the-art, video synthesis-based methods along multiple quantitative image quality metrics. Project Page: https://katjaschwarz.github.io/worlds/
L3DG: Latent 3D Gaussian Diffusion
Oct 17, 2024
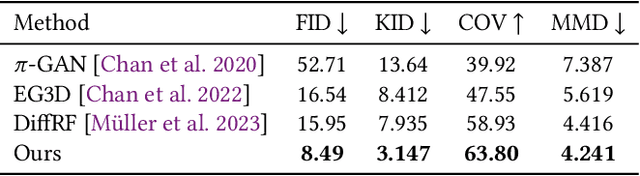
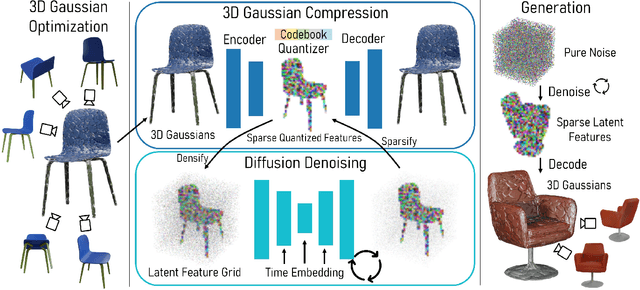
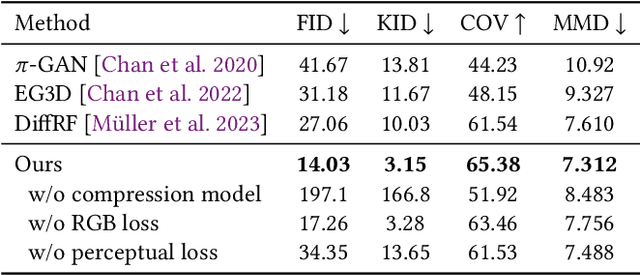
We propose L3DG, the first approach for generative 3D modeling of 3D Gaussians through a latent 3D Gaussian diffusion formulation. This enables effective generative 3D modeling, scaling to generation of entire room-scale scenes which can be very efficiently rendered. To enable effective synthesis of 3D Gaussians, we propose a latent diffusion formulation, operating in a compressed latent space of 3D Gaussians. This compressed latent space is learned by a vector-quantized variational autoencoder (VQ-VAE), for which we employ a sparse convolutional architecture to efficiently operate on room-scale scenes. This way, the complexity of the costly generation process via diffusion is substantially reduced, allowing higher detail on object-level generation, as well as scalability to large scenes. By leveraging the 3D Gaussian representation, the generated scenes can be rendered from arbitrary viewpoints in real-time. We demonstrate that our approach significantly improves visual quality over prior work on unconditional object-level radiance field synthesis and showcase its applicability to room-scale scene generation.
Volumetric Surfaces: Representing Fuzzy Geometries with Multiple Meshes
Sep 04, 2024



High-quality real-time view synthesis methods are based on volume rendering, splatting, or surface rendering. While surface-based methods generally are the fastest, they cannot faithfully model fuzzy geometry like hair. In turn, alpha-blending techniques excel at representing fuzzy materials but require an unbounded number of samples per ray (P1). Further overheads are induced by empty space skipping in volume rendering (P2) and sorting input primitives in splatting (P3). These problems are exacerbated on low-performance graphics hardware, e.g. on mobile devices. We present a novel representation for real-time view synthesis where the (P1) number of sampling locations is small and bounded, (P2) sampling locations are efficiently found via rasterization, and (P3) rendering is sorting-free. We achieve this by representing objects as semi-transparent multi-layer meshes, rendered in fixed layer order from outermost to innermost. We model mesh layers as SDF shells with optimal spacing learned during training. After baking, we fit UV textures to the corresponding meshes. We show that our method can represent challenging fuzzy objects while achieving higher frame rates than volume-based and splatting-based methods on low-end and mobile devices.
MultiDiff: Consistent Novel View Synthesis from a Single Image
Jun 26, 2024
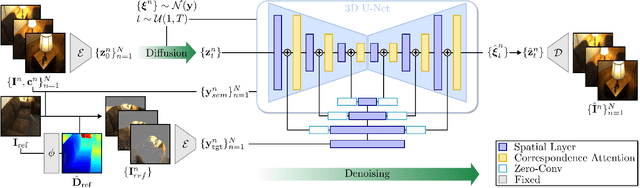


We introduce MultiDiff, a novel approach for consistent novel view synthesis of scenes from a single RGB image. The task of synthesizing novel views from a single reference image is highly ill-posed by nature, as there exist multiple, plausible explanations for unobserved areas. To address this issue, we incorporate strong priors in form of monocular depth predictors and video-diffusion models. Monocular depth enables us to condition our model on warped reference images for the target views, increasing geometric stability. The video-diffusion prior provides a strong proxy for 3D scenes, allowing the model to learn continuous and pixel-accurate correspondences across generated images. In contrast to approaches relying on autoregressive image generation that are prone to drifts and error accumulation, MultiDiff jointly synthesizes a sequence of frames yielding high-quality and multi-view consistent results -- even for long-term scene generation with large camera movements, while reducing inference time by an order of magnitude. For additional consistency and image quality improvements, we introduce a novel, structured noise distribution. Our experimental results demonstrate that MultiDiff outperforms state-of-the-art methods on the challenging, real-world datasets RealEstate10K and ScanNet. Finally, our model naturally supports multi-view consistent editing without the need for further tuning.
ConsistDreamer: 3D-Consistent 2D Diffusion for High-Fidelity Scene Editing
Jun 13, 2024



This paper proposes ConsistDreamer - a novel framework that lifts 2D diffusion models with 3D awareness and 3D consistency, thus enabling high-fidelity instruction-guided scene editing. To overcome the fundamental limitation of missing 3D consistency in 2D diffusion models, our key insight is to introduce three synergetic strategies that augment the input of the 2D diffusion model to become 3D-aware and to explicitly enforce 3D consistency during the training process. Specifically, we design surrounding views as context-rich input for the 2D diffusion model, and generate 3D-consistent, structured noise instead of image-independent noise. Moreover, we introduce self-supervised consistency-enforcing training within the per-scene editing procedure. Extensive evaluation shows that our ConsistDreamer achieves state-of-the-art performance for instruction-guided scene editing across various scenes and editing instructions, particularly in complicated large-scale indoor scenes from ScanNet++, with significantly improved sharpness and fine-grained textures. Notably, ConsistDreamer stands as the first work capable of successfully editing complex (e.g., plaid/checkered) patterns. Our project page is at immortalco.github.io/ConsistDreamer.
Dynamic 3D Gaussian Fields for Urban Areas
Jun 05, 2024
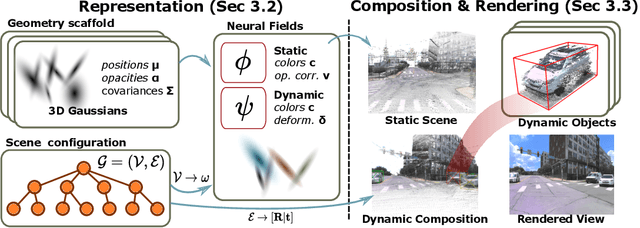
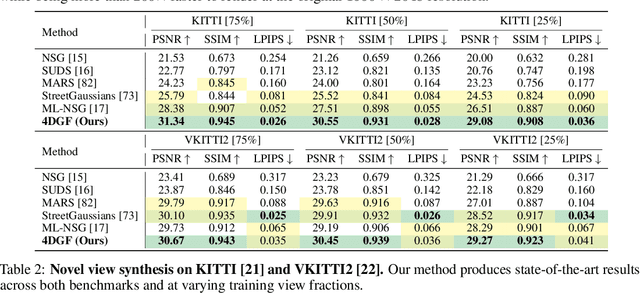
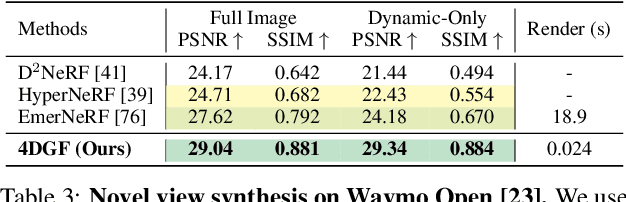
We present an efficient neural 3D scene representation for novel-view synthesis (NVS) in large-scale, dynamic urban areas. Existing works are not well suited for applications like mixed-reality or closed-loop simulation due to their limited visual quality and non-interactive rendering speeds. Recently, rasterization-based approaches have achieved high-quality NVS at impressive speeds. However, these methods are limited to small-scale, homogeneous data, i.e. they cannot handle severe appearance and geometry variations due to weather, season, and lighting and do not scale to larger, dynamic areas with thousands of images. We propose 4DGF, a neural scene representation that scales to large-scale dynamic urban areas, handles heterogeneous input data, and substantially improves rendering speeds. We use 3D Gaussians as an efficient geometry scaffold while relying on neural fields as a compact and flexible appearance model. We integrate scene dynamics via a scene graph at global scale while modeling articulated motions on a local level via deformations. This decomposed approach enables flexible scene composition suitable for real-world applications. In experiments, we surpass the state-of-the-art by over 3 dB in PSNR and more than 200 times in rendering speed.
Revising Densification in Gaussian Splatting
Apr 09, 2024
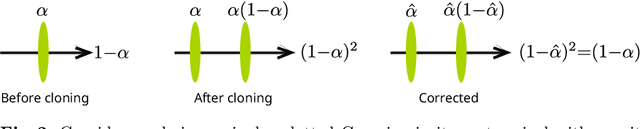


In this paper, we address the limitations of Adaptive Density Control (ADC) in 3D Gaussian Splatting (3DGS), a scene representation method achieving high-quality, photorealistic results for novel view synthesis. ADC has been introduced for automatic 3D point primitive management, controlling densification and pruning, however, with certain limitations in the densification logic. Our main contribution is a more principled, pixel-error driven formulation for density control in 3DGS, leveraging an auxiliary, per-pixel error function as the criterion for densification. We further introduce a mechanism to control the total number of primitives generated per scene and correct a bias in the current opacity handling strategy of ADC during cloning operations. Our approach leads to consistent quality improvements across a variety of benchmark scenes, without sacrificing the method's efficiency.
Multi-Level Neural Scene Graphs for Dynamic Urban Environments
Mar 29, 2024We estimate the radiance field of large-scale dynamic areas from multiple vehicle captures under varying environmental conditions. Previous works in this domain are either restricted to static environments, do not scale to more than a single short video, or struggle to separately represent dynamic object instances. To this end, we present a novel, decomposable radiance field approach for dynamic urban environments. We propose a multi-level neural scene graph representation that scales to thousands of images from dozens of sequences with hundreds of fast-moving objects. To enable efficient training and rendering of our representation, we develop a fast composite ray sampling and rendering scheme. To test our approach in urban driving scenarios, we introduce a new, novel view synthesis benchmark. We show that our approach outperforms prior art by a significant margin on both established and our proposed benchmark while being faster in training and rendering.