 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff3R: Feed-forward 3D Gaussian Splatting with Uncertainty-aware Differentiable Optimization
Apr 01, 2026Recent advances in 3D Gaussian Splatting (3DGS) present two main directions: feed-forward models offer fast inference in sparse-view settings, while per-scene optimization yields high-quality renderings but is computationally expensive. To combine the benefits of both, we introduce Diff3R, a novel framework that explicitly bridges feed-forward prediction and test-time optimization. By incorporating a differentiable 3DGS optimization layer directly into the training loop, our network learns to predict an optimal initialization for test-time optimization rather than a conventional zero-shot result. To overcome the computational cost of backpropagating through the optimization steps, we propose computing gradients via the Implicit Function Theorem and a scalable, matrix-free PCG solver tailored for 3DGS optimization. Additionally, we incorporate a data-driven uncertainty model into the optimization process by adaptively controlling how much the parameters are allowed to change during optimization. This approach effectively mitigates overfitting in under-constrained regions and increases robustness against input outliers. Since our proposed optimization layer is model-agnostic, we show that it can be seamlessly integrated into existing feed-forward 3DGS architectures for both pose-given and pose-free methods, providing improvements for test-time optimization.
Seen2Scene: Completing Realistic 3D Scenes with Visibility-Guided Flow
Mar 30, 2026We present Seen2Scene, the first flow matching-based approach that trains directly on incomplete, real-world 3D scans for scene completion and generation. Unlike prior methods that rely on complete and hence synthetic 3D data, our approach introduces visibility-guided flow matching, which explicitly masks out unknown regions in real scans, enabling effective learning from real-world, partial observations. We represent 3D scenes using truncated signed distance field (TSDF) volumes encoded in sparse grids and employ a sparse transformer to efficiently model complex scene structures while masking unknown regions. We employ 3D layout boxes as an input conditioning signal, and our approach is flexibly adapted to various other inputs such as text or partial scans. By learning directly from real-world, incomplete 3D scans, Seen2Scene enables realistic 3D scene completion for complex, cluttered real environments. Experiments demonstrate that our model produces coherent, complete, and realistic 3D scenes, outperforming baselines in completion accuracy and generation quality.
Lookalike3D: Seeing Double in 3D
Mar 25, 20263D object understanding and generation methods produce impressive results, yet they often overlook a pervasive source of information in real-world scenes: repeated objects. We introduce the task of lookalike object detection in indoor scenes, which leverages repeated and complementary cues from identical and near-identical object pairs. Given an input scene, the task is to classify pairs of objects as identical, similar or different using multiview images as input. To address this, we present Lookalike3D, a multiview image transformer that effectively distinguishes such object pairs by harnessing strong semantic priors from large image foundation models. To support this task, we collected the 3DTwins dataset, containing 76k manually annotated identical, similar and different pairs of objects based on ScanNet++, and show an improvement of 104% IoU over baselines. We demonstrate how our method improves downstream tasks such as enabling joint 3D object reconstruction and part co-segmentation, turning repeated and lookalike objects into a powerful cue for consistent, high-quality 3D perception. Our code, dataset and models will be made publicly available.
WorldMesh: Generating Navigable Multi-Room 3D Scenes via Mesh-Conditioned Image Diffusion
Mar 25, 2026Recent progress in image and video synthesis has inspired their use in advancing 3D scene generation. However, we observe that text-to-image and -video approaches struggle to maintain scene- and object-level consistency beyond a limited environment scale due to the absence of explicit geometry. We thus present a geometry-first approach that decouples this complex problem of large-scale 3D scene synthesis into its structural composition, represented as a mesh scaffold, and realistic appearance synthesis, which leverages powerful image synthesis models conditioned on the mesh scaffold. From an input text description, we first construct a mesh capturing the environment's geometry (walls, floors, etc.), and then use image synthesis, segmentation and object reconstruction to populate the mesh structure with objects in realistic layouts. This mesh scaffold is then rendered to condition image synthesis, providing a structural backbone for consistent appearance generation. This enables scalable, arbitrarily-sized 3D scenes of high object richness and diversity, combining robust 3D consistency with photorealistic detail. We believe this marks a significant step toward generating truly environment-scale, immersive 3D worlds.
WorldAgents: Can Foundation Image Models be Agents for 3D World Models?
Mar 20, 2026Given the remarkable ability of 2D foundation image models to generate high-fidelity outputs, we investigate a fundamental question: do 2D foundation image models inherently possess 3D world model capabilities? To answer this, we systematically evaluate multiple state-of-the-art image generation models and Vision-Language Models (VLMs) on the task of 3D world synthesis. To harness and benchmark their potential implicit 3D capability, we propose an agentic framing to facilitate 3D world generation. Our approach employs a multi-agent architecture: a VLM-based director that formulates prompts to guide image synthesis, a generator that synthesizes new image views, and a VLM-backed two-step verifier that evaluates and selectively curates generated frames from both 2D image and 3D reconstruction space. Crucially, we demonstrate that our agentic approach provides coherent and robust 3D reconstruction, producing output scenes that can be explored by rendering novel views. Through extensive experiments across various foundation models, we demonstrate that 2D models do indeed encapsulate a grasp of 3D worlds. By exploiting this understanding, our method successfully synthesizes expansive, realistic, and 3D-consistent worlds.
DynaRetarget: Dynamically-Feasible Retargeting using Sampling-Based Trajectory Optimization
Feb 06, 2026In this paper, we introduce DynaRetarget, a complete pipeline for retargeting human motions to humanoid control policies. The core component of DynaRetarget is a novel Sampling-Based Trajectory Optimization (SBTO) framework that refines imperfect kinematic trajectories into dynamically feasible motions. SBTO incrementally advances the optimization horizon, enabling optimization over the entire trajectory for long-horizon tasks. We validate DynaRetarget by successfully retargeting hundreds of humanoid-object demonstrations and achieving higher success rates than the state of the art. The framework also generalizes across varying object properties, such as mass, size, and geometry, using the same tracking objective. This ability to robustly retarget diverse demonstrations opens the door to generating large-scale synthetic datasets of humanoid loco-manipulation trajectories, addressing a major bottleneck in real-world data collection.
ProcGen3D: Learning Neural Procedural Graph Representations for Image-to-3D Reconstruction
Nov 10, 2025We introduce ProcGen3D, a new approach for 3D content creation by generating procedural graph abstractions of 3D objects, which can then be decoded into rich, complex 3D assets. Inspired by the prevalent use of procedural generators in production 3D applications, we propose a sequentialized, graph-based procedural graph representation for 3D assets. We use this to learn to approximate the landscape of a procedural generator for image-based 3D reconstruction. We employ edge-based tokenization to encode the procedural graphs, and train a transformer prior to predict the next token conditioned on an input RGB image. Crucially, to enable better alignment of our generated outputs to an input image, we incorporate Monte Carlo Tree Search (MCTS) guided sampling into our generation process, steering output procedural graphs towards more image-faithful reconstructions. Our approach is applicable across a variety of objects that can be synthesized with procedural generators. Extensive experiments on cacti, trees, and bridges show that our neural procedural graph generation outperforms both state-of-the-art generative 3D methods and domain-specific modeling techniques. Furthermore, this enables improved generalization on real-world input images, despite training only on synthetic data.
DiffuMatch: Category-Agnostic Spectral Diffusion Priors for Robust Non-rigid Shape Matching
Jul 31, 2025Deep functional maps have recently emerged as a powerful tool for solving non-rigid shape correspondence tasks. Methods that use this approach combine the power and flexibility of the functional map framework, with data-driven learning for improved accuracy and generality. However, most existing methods in this area restrict the learning aspect only to the feature functions and still rely on axiomatic modeling for formulating the training loss or for functional map regularization inside the networks. This limits both the accuracy and the applicability of the resulting approaches only to scenarios where assumptions of the axiomatic models hold. In this work, we show, for the first time, that both in-network regularization and functional map training can be replaced with data-driven methods. For this, we first train a generative model of functional maps in the spectral domain using score-based generative modeling, built from a large collection of high-quality maps. We then exploit the resulting model to promote the structural properties of ground truth functional maps on new shape collections. Remarkably, we demonstrate that the learned models are category-agnostic, and can fully replace commonly used strategies such as enforcing Laplacian commutativity or orthogonality of functional maps. Our key technical contribution is a novel distillation strategy from diffusion models in the spectral domain. Experiments demonstrate that our learned regularization leads to better results than axiomatic approaches for zero-shot non-rigid shape matching. Our code is available at: https://github.com/daidedou/diffumatch/
HOI-PAGE: Zero-Shot Human-Object Interaction Generation with Part Affordance Guidance
Jun 08, 2025



We present HOI-PAGE, a new approach to synthesizing 4D human-object interactions (HOIs) from text prompts in a zero-shot fashion, driven by part-level affordance reasoning. In contrast to prior works that focus on global, whole body-object motion for 4D HOI synthesis, we observe that generating realistic and diverse HOIs requires a finer-grained understanding -- at the level of how human body parts engage with object parts. We thus introduce Part Affordance Graphs (PAGs), a structured HOI representation distilled from large language models (LLMs) that encodes fine-grained part information along with contact relations. We then use these PAGs to guide a three-stage synthesis: first, decomposing input 3D objects into geometric parts; then, generating reference HOI videos from text prompts, from which we extract part-based motion constraints; finally, optimizing for 4D HOI motion sequences that not only mimic the reference dynamics but also satisfy part-level contact constraints. Extensive experiments show that our approach is flexible and capable of generating complex multi-object or multi-person interaction sequences, with significantly improved realism and text alignment for zero-shot 4D HOI generation.
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025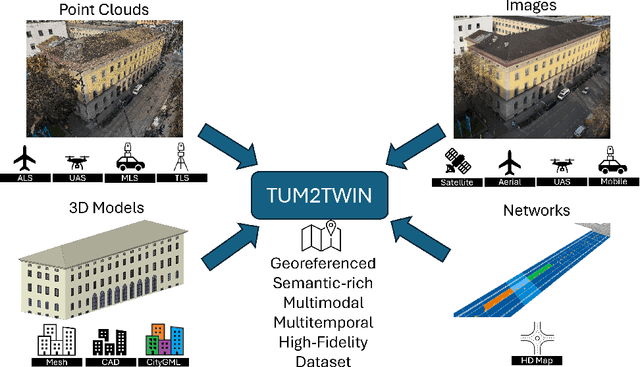
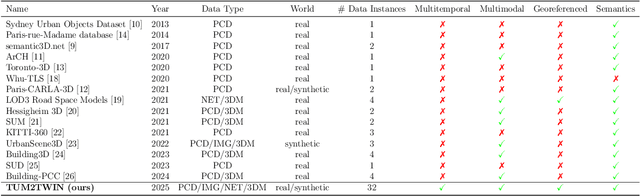

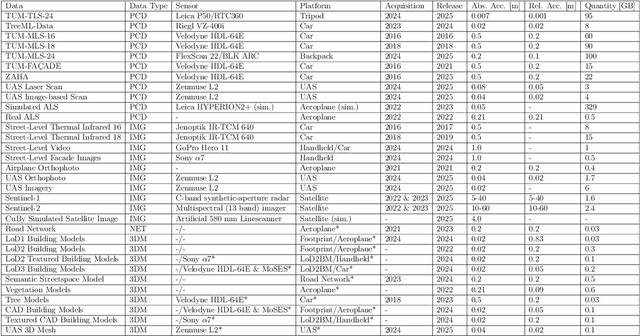
Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win