 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHippo: High-performance Interior-Point and Projection-based Solver for Generic Constrained Trajectory Optimization
Mar 01, 2026Trajectory optimization is the core of modern model-based robotic control and motion planning. Existing trajectory optimizers, based on sequential quadratic programming (SQP) or differential dynamic programming (DDP), are often limited by their slow computation efficiency, low modeling flexibility, and poor convergence for complex tasks requiring hard constraints. In this paper, we introduce Hippo, a solver that can handle inequality constraints using the interior-point method (IPM) with an adaptive barrier update strategy and hard equality constraints via projection or IPM. Through extensive numerical benchmarks, we show that Hippo is a robust and efficient alternative to existing state-of-the-art solvers for difficult robotic trajectory optimization problems requiring high-quality solutions, such as locomotion and manipulation.
SURE: Safe Uncertainty-Aware Robot-Environment Interaction using Trajectory Optimization
Feb 06, 2026Robotic tasks involving contact interactions pose significant challenges for trajectory optimization due to discontinuous dynamics. Conventional formulations typically assume deterministic contact events, which limit robustness and adaptability in real-world settings. In this work, we propose SURE, a robust trajectory optimization framework that explicitly accounts for contact timing uncertainty. By allowing multiple trajectories to branch from possible pre-impact states and later rejoin a shared trajectory, SURE achieves both robustness and computational efficiency within a unified optimization framework. We evaluate SURE on two representative tasks with unknown impact times. In a cart-pole balancing task involving uncertain wall location, SURE achieves an average improvement of 21.6% in success rate when branch switching is enabled during control. In an egg-catching experiment using a robotic manipulator, SURE improves the success rate by 40%. These results demonstrate that SURE substantially enhances robustness compared to conventional nominal formulations.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
RollArt: Scaling Agentic RL Training via Disaggregated Infrastructure
Dec 27, 2025Agentic Reinforcement Learning (RL) enables Large Language Models (LLMs) to perform autonomous decision-making and long-term planning. Unlike standard LLM post-training, agentic RL workloads are highly heterogeneous, combining compute-intensive prefill phases, bandwidth-bound decoding, and stateful, CPU-heavy environment simulations. We argue that efficient agentic RL training requires disaggregated infrastructure to leverage specialized, best-fit hardware. However, naive disaggregation introduces substantial synchronization overhead and resource underutilization due to the complex dependencies between stages. We present RollArc, a distributed system designed to maximize throughput for multi-task agentic RL on disaggregated infrastructure. RollArc is built on three core principles: (1) hardware-affinity workload mapping, which routes compute-bound and bandwidth-bound tasks to bestfit GPU devices, (2) fine-grained asynchrony, which manages execution at the trajectory level to mitigate resource bubbles, and (3) statefulness-aware computation, which offloads stateless components (e.g., reward models) to serverless infrastructure for elastic scaling. Our results demonstrate that RollArc effectively improves training throughput and achieves 1.35-2.05\(\times\) end-to-end training time reduction compared to monolithic and synchronous baselines. We also evaluate RollArc by training a hundreds-of-billions-parameter MoE model for Qoder product on an Alibaba cluster with more than 3,000 GPUs, further demonstrating RollArc scalability and robustness. The code is available at https://github.com/alibaba/ROLL.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
Physically Consistent Humanoid Loco-Manipulation using Latent Diffusion Models
Apr 23, 2025This paper uses the capabilities of latent diffusion models (LDMs) to generate realistic RGB human-object interaction scenes to guide humanoid loco-manipulation planning. To do so, we extract from the generated images both the contact locations and robot configurations that are then used inside a whole-body trajectory optimization (TO) formulation to generate physically consistent trajectories for humanoids. We validate our full pipeline in simulation for different long-horizon loco-manipulation scenarios and perform an extensive analysis of the proposed contact and robot configuration extraction pipeline. Our results show that using the information extracted from LDMs, we can generate physically consistent trajectories that require long-horizon reasoning.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Trajectory Optimization under Contact Timing Uncertainties
Jul 16, 2024



Most interesting problems in robotics (e.g., locomotion and manipulation) are realized through intermittent contact with the environment. Due to the perception and modeling errors, assuming an exact time for establishing contact with the environment is unrealistic. On the other hand, handling uncertainties in contact timing is notoriously difficult as it gives rise to either handling uncertain complementarity systems or solving combinatorial optimization problems at run-time. This work presents a novel optimal control formulation to find robust control policies under contact timing uncertainties. Our main novelty lies in casting the stochastic problem to a deterministic optimization over the uncertainty set that ensures robustness criterion satisfaction of candidate pre-contact states and optimizes for contact-relevant objectives. This way, we only need to solve a manageable standard nonlinear programming problem without complementarity constraints or combinatorial explosion. Our simulation results on multiple simplified locomotion and manipulation tasks demonstrate the robustness of our uncertainty-aware formulation compared to the nominal optimal control formulation.
Arm-Constrained Curriculum Learning for Loco-Manipulation of the Wheel-Legged Robot
Mar 28, 2024
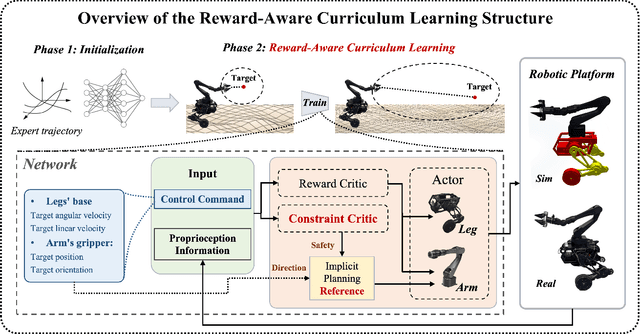
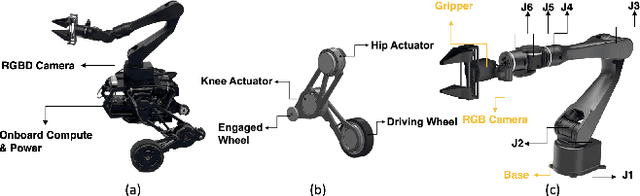
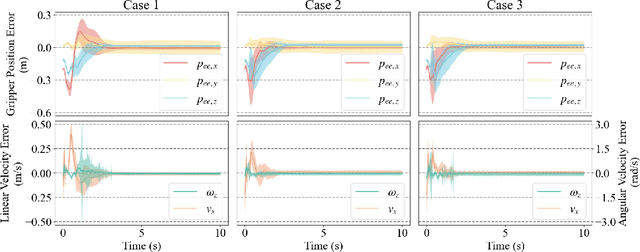
Incorporating a robotic manipulator into a wheel-legged robot enhances its agility and expands its potential for practical applications. However, the presence of potential instability and uncertainties presents additional challenges for control objectives. In this paper, we introduce an arm-constrained curriculum learning architecture to tackle the issues introduced by adding the manipulator. Firstly, we develop an arm-constrained reinforcement learning algorithm to ensure safety and stability in control performance. Additionally, to address discrepancies in reward settings between the arm and the base, we propose a reward-aware curriculum learning method. The policy is first trained in Isaac gym and transferred to the physical robot to do dynamic grasping tasks, including the door-opening task, fan-twitching task and the relay-baton-picking and following task. The results demonstrate that our proposed approach effectively controls the arm-equipped wheel-legged robot to master dynamic grasping skills, allowing it to chase and catch a moving object while in motion. Please refer to our website (https://acodedog.github.io/wheel-legged-loco-manipulation) for the code and supplemental videos.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.