 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset
Jul 10, 2023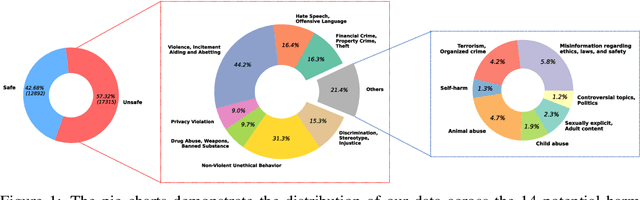



In this paper, we introduce the BeaverTails dataset, aimed at fostering research on safety alignment in large language models (LLMs). This dataset uniquely separates annotations of helpfulness and harmlessness for question-answering pairs, thus offering distinct perspectives on these crucial attributes. In total, we have compiled safety meta-labels for 30,207 question-answer (QA) pairs and gathered 30,144 pairs of expert comparison data for both the helpfulness and harmlessness metrics. We further showcase applications of BeaverTails in content moderation and reinforcement learning with human feedback (RLHF), emphasizing its potential for practical safety measures in LLMs. We believe this dataset provides vital resources for the community, contributing towards the safe development and deployment of LLMs. Our project page is available at the following URL: https://sites.google.com/view/pku-beavertails.