 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Gymnasium: A Unified Safe Reinforcement Learning Benchmark
Oct 19, 2023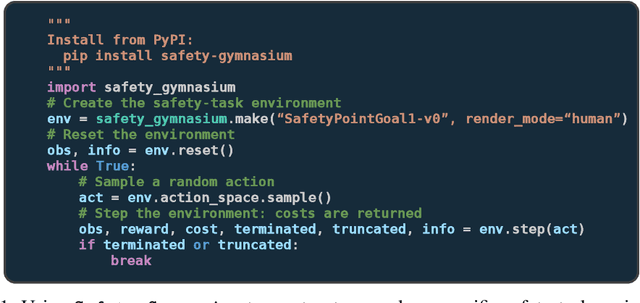
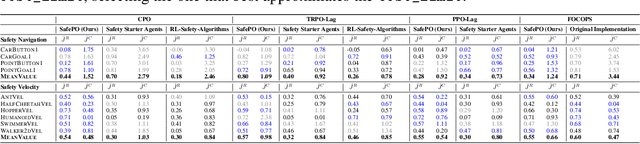

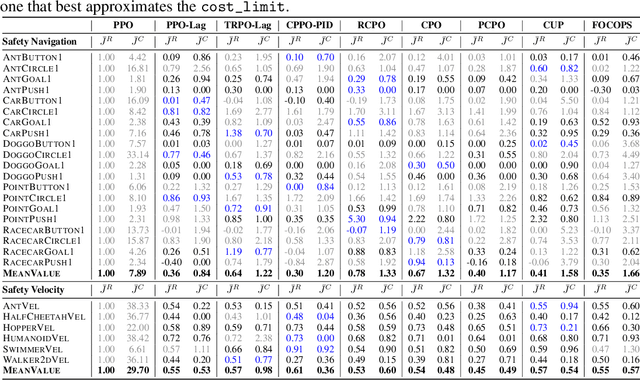
Artificial intelligence (AI) systems possess significant potential to drive societal progress. However, their deployment often faces obstacles due to substantial safety concerns. Safe reinforcement learning (SafeRL) emerges as a solution to optimize policies while simultaneously adhering to multiple constraints, thereby addressing the challenge of integrating reinforcement learning in safety-critical scenarios. In this paper, we present an environment suite called Safety-Gymnasium, which encompasses safety-critical tasks in both single and multi-agent scenarios, accepting vector and vision-only input. Additionally, we offer a library of algorithms named Safe Policy Optimization (SafePO), comprising 16 state-of-the-art SafeRL algorithms. This comprehensive library can serve as a validation tool for the research community. By introducing this benchmark, we aim to facilitate the evaluation and comparison of safety performance, thus fostering the development of reinforcement learning for safer, more reliable, and responsible real-world applications. The website of this project can be accessed at https://sites.google.com/view/safety-gymnasium.
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Oct 19, 2023



With the development of large language models (LLMs), striking a balance between the performance and safety of AI systems has never been more critical. However, the inherent tension between the objectives of helpfulness and harmlessness presents a significant challenge during LLM training. To address this issue, we propose Safe Reinforcement Learning from Human Feedback (Safe RLHF), a novel algorithm for human value alignment. Safe RLHF explicitly decouples human preferences regarding helpfulness and harmlessness, effectively avoiding the crowdworkers' confusion about the tension and allowing us to train separate reward and cost models. We formalize the safety concern of LLMs as an optimization task of maximizing the reward function while satisfying specified cost constraints. Leveraging the Lagrangian method to solve this constrained problem, Safe RLHF dynamically adjusts the balance between the two objectives during fine-tuning. Through a three-round fine-tuning using Safe RLHF, we demonstrate a superior ability to mitigate harmful responses while enhancing model performance compared to existing value-aligned algorithms. Experimentally, we fine-tuned the Alpaca-7B using Safe RLHF and aligned it with collected human preferences, significantly improving its helpfulness and harmlessness according to human evaluations.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset
Jul 10, 2023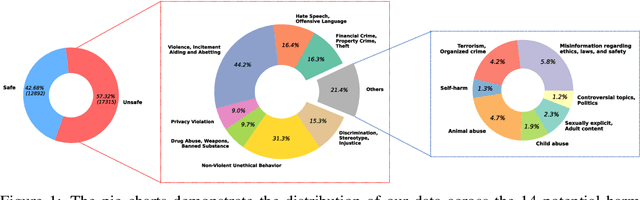



In this paper, we introduce the BeaverTails dataset, aimed at fostering research on safety alignment in large language models (LLMs). This dataset uniquely separates annotations of helpfulness and harmlessness for question-answering pairs, thus offering distinct perspectives on these crucial attributes. In total, we have compiled safety meta-labels for 30,207 question-answer (QA) pairs and gathered 30,144 pairs of expert comparison data for both the helpfulness and harmlessness metrics. We further showcase applications of BeaverTails in content moderation and reinforcement learning with human feedback (RLHF), emphasizing its potential for practical safety measures in LLMs. We believe this dataset provides vital resources for the community, contributing towards the safe development and deployment of LLMs. Our project page is available at the following URL: https://sites.google.com/view/pku-beavertails.
OmniSafe: An Infrastructure for Accelerating Safe Reinforcement Learning Research
May 16, 2023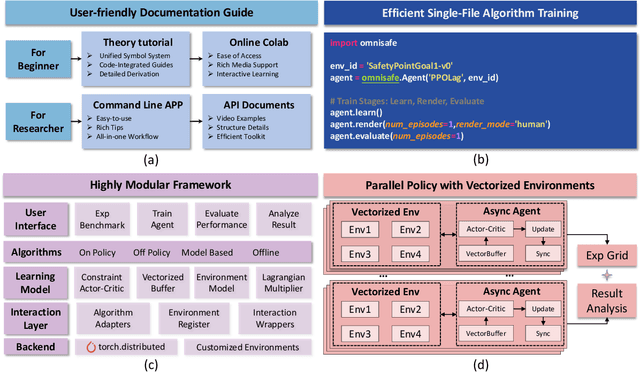
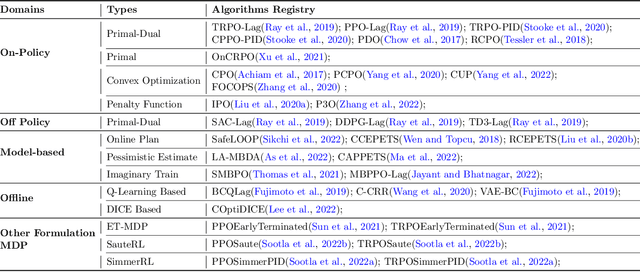
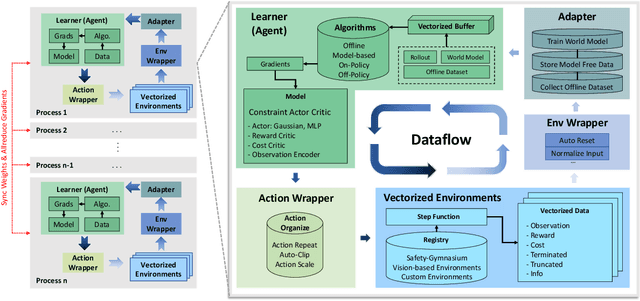
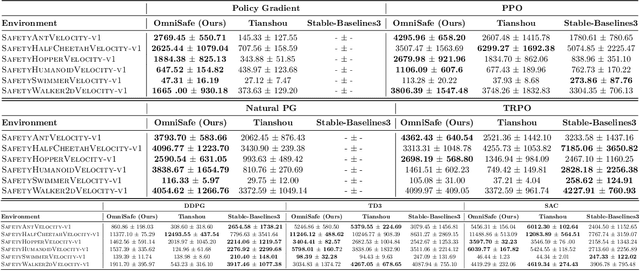
AI systems empowered by reinforcement learning (RL) algorithms harbor the immense potential to catalyze societal advancement, yet their deployment is often impeded by significant safety concerns. Particularly in safety-critical applications, researchers have raised concerns about unintended harms or unsafe behaviors of unaligned RL agents. The philosophy of safe reinforcement learning (SafeRL) is to align RL agents with harmless intentions and safe behavioral patterns. In SafeRL, agents learn to develop optimal policies by receiving feedback from the environment, while also fulfilling the requirement of minimizing the risk of unintended harm or unsafe behavior. However, due to the intricate nature of SafeRL algorithm implementation, combining methodologies across various domains presents a formidable challenge. This had led to an absence of a cohesive and efficacious learning framework within the contemporary SafeRL research milieu. In this work, we introduce a foundational framework designed to expedite SafeRL research endeavors. Our comprehensive framework encompasses an array of algorithms spanning different RL domains and places heavy emphasis on safety elements. Our efforts are to make the SafeRL-related research process more streamlined and efficient, therefore facilitating further research in AI safety. Our project is released at: https://github.com/PKU-Alignment/omnisafe.
Sketch-Inspector: a Deep Mixture Model for High-Quality Sketch Generation of Cats
Nov 09, 2020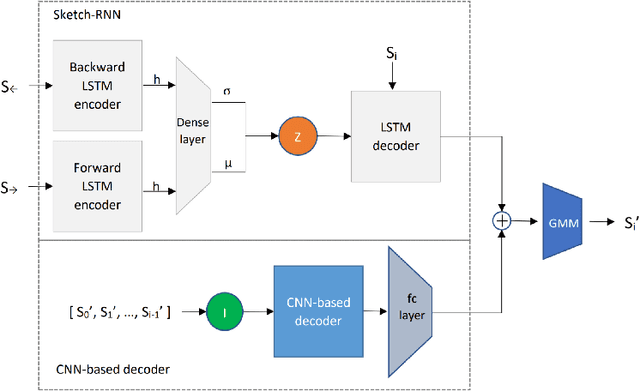
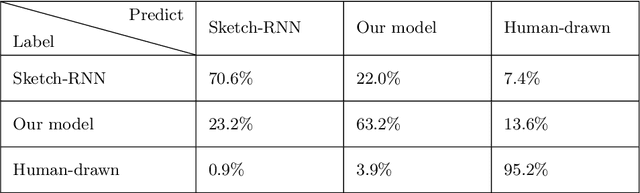
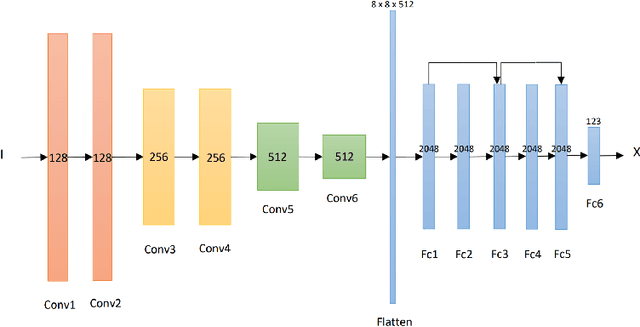
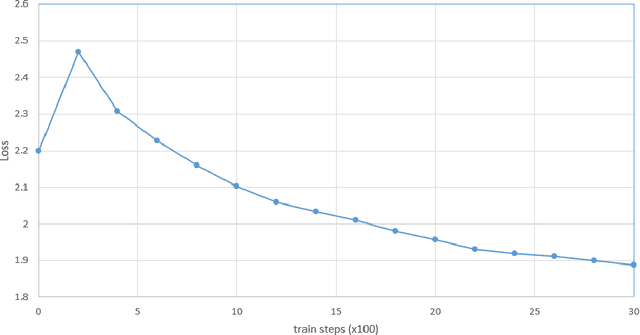
With the involvement of artificial intelligence (AI), sketches can be automatically generated under certain topics. Even though breakthroughs have been made in previous studies in this area, a relatively high proportion of the generated figures are too abstract to recognize, which illustrates that AIs fail to learn the general pattern of the target object when drawing. This paper posits that supervising the process of stroke generation can lead to a more accurate sketch interpretation. Based on that, a sketch generating system with an assistant convolutional neural network (CNN) predictor to suggest the shape of the next stroke is presented in this paper. In addition, a CNN-based discriminator is introduced to judge the recognizability of the end product. Since the base-line model is ineffective at generating multi-class sketches, we restrict the model to produce one category. Because the image of a cat is easy to identify, we consider cat sketches selected from the QuickDraw data set. This paper compares the proposed model with the original Sketch-RNN on 75K human-drawn cat sketches. The result indicates that our model produces sketches with higher quality than human's sketches.