 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explicit Acoustic Evidence Perception in Audio LLMs for Speech Deepfake Detection
Jan 30, 2026Speech deepfake detection (SDD) focuses on identifying whether a given speech signal is genuine or has been synthetically generated. Existing audio large language model (LLM)-based methods excel in content understanding; however, their predictions are often biased toward semantically correlated cues, which results in fine-grained acoustic artifacts being overlooked during the decisionmaking process. Consequently, fake speech with natural semantics can bypass detectors despite harboring subtle acoustic anomalies; this suggests that the challenge stems not from the absence of acoustic data, but from its inadequate accessibility when semantic-dominant reasoning prevails. To address this issue, we investigate SDD within the audio LLM paradigm and introduce SDD with Auditory Perception-enhanced Audio Large Language Model (SDD-APALLM), an acoustically enhanced framework designed to explicitly expose fine-grained time-frequency evidence as accessible acoustic cues. By combining raw audio with structured spectrograms, the proposed framework empowers audio LLMs to more effectively capture subtle acoustic inconsistencies without compromising their semantic understanding. Experimental results indicate consistent gains in detection accuracy and robustness, especially in cases where semantic cues are misleading. Further analysis reveals that these improvements stem from a coordinated utilization of semantic and acoustic information, as opposed to simple modality aggregation.
Interpretable All-Type Audio Deepfake Detection with Audio LLMs via Frequency-Time Reinforcement Learning
Jan 06, 2026Recent advances in audio large language models (ALLMs) have made high-quality synthetic audio widely accessible, increasing the risk of malicious audio deepfakes across speech, environmental sounds, singing voice, and music. Real-world audio deepfake detection (ADD) therefore requires all-type detectors that generalize across heterogeneous audio and provide interpretable decisions. Given the strong multi-task generalization ability of ALLMs, we first investigate their performance on all-type ADD under both supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). However, SFT using only binary real/fake labels tends to reduce the model to a black-box classifier, sacrificing interpretability. Meanwhile, vanilla RFT under sparse supervision is prone to reward hacking and can produce hallucinated, ungrounded rationales. To address this, we propose an automatic annotation and polishing pipeline that constructs Frequency-Time structured chain-of-thought (CoT) rationales, producing ~340K cold-start demonstrations. Building on CoT data, we propose Frequency Time-Group Relative Policy Optimization (FT-GRPO), a two-stage training paradigm that cold-starts ALLMs with SFT and then applies GRPO under rule-based frequency-time constraints. Experiments demonstrate that FT-GRPO achieves state-of-the-art performance on all-type ADD while producing interpretable, FT-grounded rationales. The data and code are available online.
Encyclo-K: Evaluating LLMs with Dynamically Composed Knowledge Statements
Dec 31, 2025Benchmarks play a crucial role in tracking the rapid advancement of large language models (LLMs) and identifying their capability boundaries. However, existing benchmarks predominantly curate questions at the question level, suffering from three fundamental limitations: vulnerability to data contamination, restriction to single-knowledge-point assessment, and reliance on costly domain expert annotation. We propose Encyclo-K, a statement-based benchmark that rethinks benchmark construction from the ground up. Our key insight is that knowledge statements, not questions, can serve as the unit of curation, and questions can then be constructed from them. We extract standalone knowledge statements from authoritative textbooks and dynamically compose them into evaluation questions through random sampling at test time. This design directly addresses all three limitations: the combinatorial space is too vast to memorize, and model rankings remain stable across dynamically generated question sets, enabling reliable periodic dataset refresh; each question aggregates 8-10 statements for comprehensive multi-knowledge assessment; annotators only verify formatting compliance without requiring domain expertise, substantially reducing annotation costs. Experiments on over 50 LLMs demonstrate that Encyclo-K poses substantial challenges with strong discriminative power. Even the top-performing OpenAI-GPT-5.1 achieves only 62.07% accuracy, and model performance displays a clear gradient distribution--reasoning models span from 16.04% to 62.07%, while chat models range from 9.71% to 50.40%. These results validate the challenges introduced by dynamic evaluation and multi-statement comprehensive understanding. These findings establish Encyclo-K as a scalable framework for dynamic evaluation of LLMs' comprehensive understanding over multiple fine-grained disciplinary knowledge statements.
EnvSSLAM-FFN: Lightweight Layer-Fused System for ESDD 2026 Challenge
Dec 23, 2025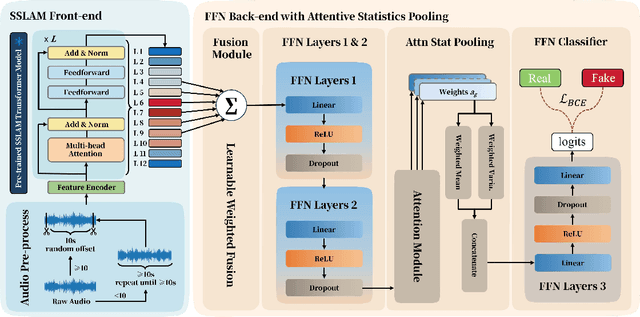
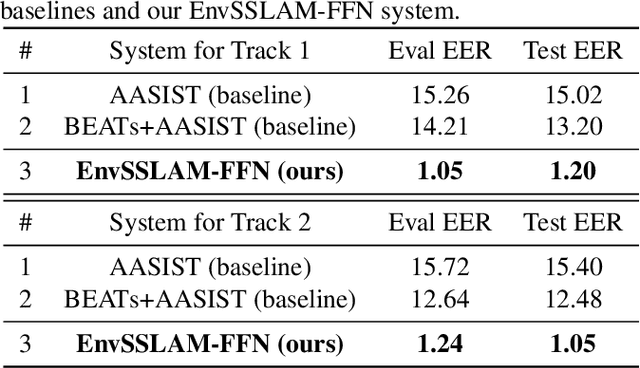
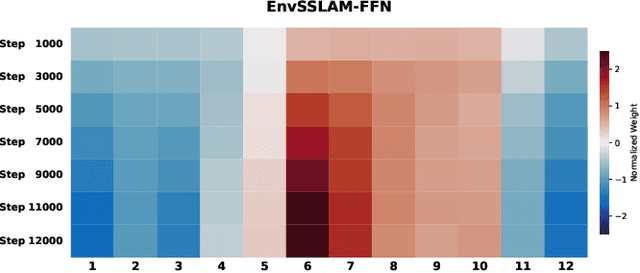
Recent advances in generative audio models have enabled high-fidelity environmental sound synthesis, raising serious concerns for audio security. The ESDD 2026 Challenge therefore addresses environmental sound deepfake detection under unseen generators (Track 1) and black-box low-resource detection (Track 2) conditions. We propose EnvSSLAM-FFN, which integrates a frozen SSLAM self-supervised encoder with a lightweight FFN back-end. To effectively capture spoofing artifacts under severe data imbalance, we fuse intermediate SSLAM representations from layers 4-9 and adopt a class-weighted training objective. Experimental results show that the proposed system consistently outperforms the official baselines on both tracks, achieving Test Equal Error Rates (EERs) of 1.20% and 1.05%, respectively.
Reconstruction as a Bridge for Event-Based Visual Question Answering
Dec 12, 2025Integrating event cameras with Multimodal Large Language Models (MLLMs) promises general scene understanding in challenging visual conditions, yet requires navigating a trade-off between preserving the unique advantages of event data and ensuring compatibility with frame-based models. We address this challenge by using reconstruction as a bridge, proposing a straightforward Frame-based Reconstruction and Tokenization (FRT) method and designing an efficient Adaptive Reconstruction and Tokenization (ART) method that leverages event sparsity. For robust evaluation, we introduce EvQA, the first objective, real-world benchmark for event-based MLLMs, comprising 1,000 event-Q&A pairs from 22 public datasets. Our experiments demonstrate that our methods achieve state-of-the-art performance on EvQA, highlighting the significant potential of MLLMs in event-based vision.
On Thin Ice: Towards Explainable Conservation Monitoring via Attribution and Perturbations
Oct 24, 2025Computer vision can accelerate ecological research and conservation monitoring, yet adoption in ecology lags in part because of a lack of trust in black-box neural-network-based models. We seek to address this challenge by applying post-hoc explanations to provide evidence for predictions and document limitations that are important to field deployment. Using aerial imagery from Glacier Bay National Park, we train a Faster R-CNN to detect pinnipeds (harbor seals) and generate explanations via gradient-based class activation mapping (HiResCAM, LayerCAM), local interpretable model-agnostic explanations (LIME), and perturbation-based explanations. We assess explanations along three axes relevant to field use: (i) localization fidelity: whether high-attribution regions coincide with the animal rather than background context; (ii) faithfulness: whether deletion/insertion tests produce changes in detector confidence; and (iii) diagnostic utility: whether explanations reveal systematic failure modes. Explanations concentrate on seal torsos and contours rather than surrounding ice/rock, and removal of the seals reduces detection confidence, providing model-evidence for true positives. The analysis also uncovers recurrent error sources, including confusion between seals and black ice and rocks. We translate these findings into actionable next steps for model development, including more targeted data curation and augmentation. By pairing object detection with post-hoc explainability, we can move beyond "black-box" predictions toward auditable, decision-supporting tools for conservation monitoring.
InterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
May 29, 2025As multimodal large models (MLLMs) continue to advance across challenging tasks, a key question emerges: What essential capabilities are still missing? A critical aspect of human learning is continuous interaction with the environment -- not limited to language, but also involving multimodal understanding and generation. To move closer to human-level intelligence, models must similarly support multi-turn, multimodal interaction. In particular, they should comprehend interleaved multimodal contexts and respond coherently in ongoing exchanges. In this work, we present an initial exploration through the InterMT -- the first preference dataset for multi-turn multimodal interaction, grounded in real human feedback. In this exploration, we particularly emphasize the importance of human oversight, introducing expert annotations to guide the process, motivated by the fact that current MLLMs lack such complex interactive capabilities. InterMT captures human preferences at both global and local levels into nine sub-dimensions, consists of 15.6k prompts, 52.6k multi-turn dialogue instances, and 32.4k human-labeled preference pairs. To compensate for the lack of capability for multi-modal understanding and generation, we introduce an agentic workflow that leverages tool-augmented MLLMs to construct multi-turn QA instances. To further this goal, we introduce InterMT-Bench to assess the ability of MLLMs in assisting judges with multi-turn, multimodal tasks. We demonstrate the utility of \InterMT through applications such as judge moderation and further reveal the multi-turn scaling law of judge model. We hope the open-source of our data can help facilitate further research on aligning current MLLMs to the next step. Our project website can be found at https://pku-intermt.github.io .
Mitigating Deceptive Alignment via Self-Monitoring
May 24, 2025Modern large language models rely on chain-of-thought (CoT) reasoning to achieve impressive performance, yet the same mechanism can amplify deceptive alignment, situations in which a model appears aligned while covertly pursuing misaligned goals. Existing safety pipelines treat deception as a black-box output to be filtered post-hoc, leaving the model free to scheme during its internal reasoning. We ask: Can deception be intercepted while the model is thinking? We answer this question, the first framework that embeds a Self-Monitor inside the CoT process itself, named CoT Monitor+. During generation, the model produces (i) ordinary reasoning steps and (ii) an internal self-evaluation signal trained to flag and suppress misaligned strategies. The signal is used as an auxiliary reward in reinforcement learning, creating a feedback loop that rewards honest reasoning and discourages hidden goals. To study deceptive alignment systematically, we introduce DeceptionBench, a five-category benchmark that probes covert alignment-faking, sycophancy, etc. We evaluate various LLMs and show that unrestricted CoT roughly aggravates the deceptive tendency. In contrast, CoT Monitor+ cuts deceptive behaviors by 43.8% on average while preserving task accuracy. Further, when the self-monitor signal replaces an external weak judge in RL fine-tuning, models exhibit substantially fewer obfuscated thoughts and retain transparency. Our project website can be found at cot-monitor-plus.github.io
Generative RLHF-V: Learning Principles from Multi-modal Human Preference
May 24, 2025Training multi-modal large language models (MLLMs) that align with human intentions is a long-term challenge. Traditional score-only reward models for alignment suffer from low accuracy, weak generalization, and poor interpretability, blocking the progress of alignment methods, e.g., reinforcement learning from human feedback (RLHF). Generative reward models (GRMs) leverage MLLMs' intrinsic reasoning capabilities to discriminate pair-wise responses, but their pair-wise paradigm makes it hard to generalize to learnable rewards. We introduce Generative RLHF-V, a novel alignment framework that integrates GRMs with multi-modal RLHF. We propose a two-stage pipeline: $\textbf{multi-modal generative reward modeling from RL}$, where RL guides GRMs to actively capture human intention, then predict the correct pair-wise scores; and $\textbf{RL optimization from grouped comparison}$, which enhances multi-modal RL scoring precision by grouped responses comparison. Experimental results demonstrate that, besides out-of-distribution generalization of RM discrimination, our framework improves 4 MLLMs' performance across 7 benchmarks by $18.1\%$, while the baseline RLHF is only $5.3\%$. We further validate that Generative RLHF-V achieves a near-linear improvement with an increasing number of candidate responses. Our code and models can be found at https://generative-rlhf-v.github.io.
Fine-tuning Quantized Neural Networks with Zeroth-order Optimization
May 19, 2025As the size of large language models grows exponentially, GPU memory has become a bottleneck for adapting these models to downstream tasks. In this paper, we aim to push the limits of memory-efficient training by minimizing memory usage on model weights, gradients, and optimizer states, within a unified framework. Our idea is to eliminate both gradients and optimizer states using zeroth-order optimization, which approximates gradients by perturbing weights during forward passes to identify gradient directions. To minimize memory usage on weights, we employ model quantization, e.g., converting from bfloat16 to int4. However, directly applying zeroth-order optimization to quantized weights is infeasible due to the precision gap between discrete weights and continuous gradients, which would otherwise require de-quantization and re-quantization. To overcome this challenge, we propose Quantized Zeroth-order Optimization (QZO), a novel approach that perturbs the continuous quantization scale for gradient estimation and uses a directional derivative clipping method to stabilize training. QZO is orthogonal to both scalar-based and codebook-based post-training quantization methods. Compared to full-parameter fine-tuning in bfloat16, QZO can reduce the total memory cost by more than 18$\times$ for 4-bit LLMs, and enables fine-tuning Llama-2-13B and Stable Diffusion 3.5 Large within a single 24GB GPU.