 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECO: Energy-Constrained Optimization with Reinforcement Learning for Humanoid Walking
Feb 06, 2026Achieving stable and energy-efficient locomotion is essential for humanoid robots to operate continuously in real-world applications. Existing MPC and RL approaches often rely on energy-related metrics embedded within a multi-objective optimization framework, which require extensive hyperparameter tuning and often result in suboptimal policies. To address these challenges, we propose ECO (Energy-Constrained Optimization), a constrained RL framework that separates energy-related metrics from rewards, reformulating them as explicit inequality constraints. This method provides a clear and interpretable physical representation of energy costs, enabling more efficient and intuitive hyperparameter tuning for improved energy efficiency. ECO introduces dedicated constraints for energy consumption and reference motion, enforced by the Lagrangian method, to achieve stable, symmetric, and energy-efficient walking for humanoid robots. We evaluated ECO against MPC, standard RL with reward shaping, and four state-of-the-art constrained RL methods. Experiments, including sim-to-sim and sim-to-real transfers on the kid-sized humanoid robot BRUCE, demonstrate that ECO significantly reduces energy consumption compared to baselines while maintaining robust walking performance. These results highlight a substantial advancement in energy-efficient humanoid locomotion. All experimental demonstrations can be found on the project website: https://sites.google.com/view/eco-humanoid.
Towards Bridging the Gap between Large-Scale Pretraining and Efficient Finetuning for Humanoid Control
Jan 29, 2026Reinforcement learning (RL) is widely used for humanoid control, with on-policy methods such as Proximal Policy Optimization (PPO) enabling robust training via large-scale parallel simulation and, in some cases, zero-shot deployment to real robots. However, the low sample efficiency of on-policy algorithms limits safe adaptation to new environments. Although off-policy RL and model-based RL have shown improved sample efficiency, the gap between large-scale pretraining and efficient finetuning on humanoids still exists. In this paper, we find that off-policy Soft Actor-Critic (SAC), with large-batch update and a high Update-To-Data (UTD) ratio, reliably supports large-scale pretraining of humanoid locomotion policies, achieving zero-shot deployment on real robots. For adaptation, we demonstrate that these SAC-pretrained policies can be finetuned in new environments and out-of-distribution tasks using model-based methods. Data collection in the new environment executes a deterministic policy while stochastic exploration is instead confined to a physics-informed world model. This separation mitigates the risks of random exploration during adaptation while preserving exploratory coverage for improvement. Overall, the approach couples the wall-clock efficiency of large-scale simulation during pretraining with the sample efficiency of model-based learning during fine-tuning.
Towards Automated Differential Diagnosis of Skin Diseases Using Deep Learning and Imbalance-Aware Strategies
Jan 01, 2026As dermatological conditions become increasingly common and the availability of dermatologists remains limited, there is a growing need for intelligent tools to support both patients and clinicians in the timely and accurate diagnosis of skin diseases. In this project, we developed a deep learning based model for the classification and diagnosis of skin conditions. By leveraging pretraining on publicly available skin disease image datasets, our model effectively extracted visual features and accurately classified various dermatological cases. Throughout the project, we refined the model architecture, optimized data preprocessing workflows, and applied targeted data augmentation techniques to improve overall performance. The final model, based on the Swin Transformer, achieved a prediction accuracy of 87.71 percent across eight skin lesion classes on the ISIC2019 dataset. These results demonstrate the model's potential as a diagnostic support tool for clinicians and a self assessment aid for patients.
Benchmarking Preprocessing and Integration Methods in Single-Cell Genomics
Jan 01, 2026Single-cell data analysis has the potential to revolutionize personalized medicine by characterizing disease-associated molecular changes at the single-cell level. Advanced single-cell multimodal assays can now simultaneously measure various molecules (e.g., DNA, RNA, Protein) across hundreds of thousands of individual cells, providing a comprehensive molecular readout. A significant analytical challenge is integrating single-cell measurements across different modalities. Various methods have been developed to address this challenge, but there has been no systematic evaluation of these techniques with different preprocessing strategies. This study examines a general pipeline for single-cell data analysis, which includes normalization, data integration, and dimensionality reduction. The performance of different algorithm combinations often depends on the dataset sizes and characteristics. We evaluate six datasets across diverse modalities, tissues, and organisms using three metrics: Silhouette Coefficient Score, Adjusted Rand Index, and Calinski-Harabasz Index. Our experiments involve combinations of seven normalization methods, four dimensional reduction methods, and five integration methods. The results show that Seurat and Harmony excel in data integration, with Harmony being more time-efficient, especially for large datasets. UMAP is the most compatible dimensionality reduction method with the integration techniques, and the choice of normalization method varies depending on the integration method used.
FedSAF: A Federated Learning Framework for Enhanced Gastric Cancer Detection and Privacy Preservation
Mar 20, 2025
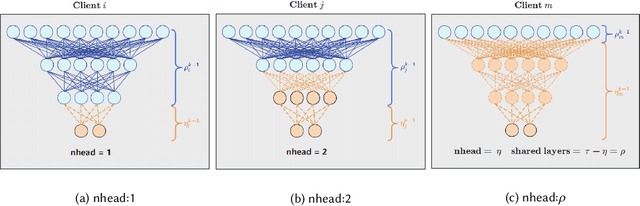
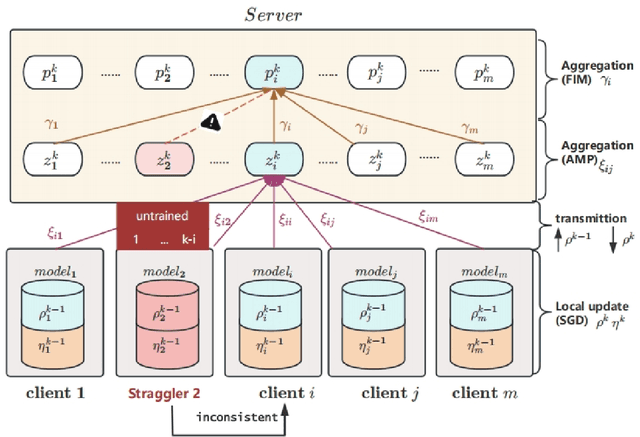
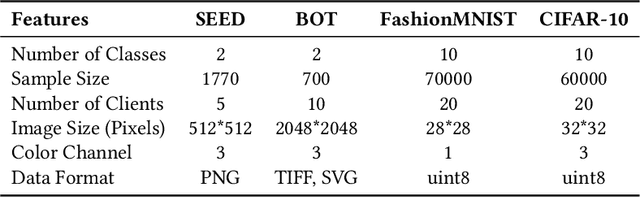
Gastric cancer is one of the most commonly diagnosed cancers and has a high mortality rate. Due to limited medical resources, developing machine learning models for gastric cancer recognition provides an efficient solution for medical institutions. However, such models typically require large sample sizes for training and testing, which can challenge patient privacy. Federated learning offers an effective alternative by enabling model training across multiple institutions without sharing sensitive patient data. This paper addresses the limited sample size of publicly available gastric cancer data with a modified data processing method. This paper introduces FedSAF, a novel federated learning algorithm designed to improve the performance of existing methods, particularly in non-independent and identically distributed (non-IID) data scenarios. FedSAF incorporates attention-based message passing and the Fisher Information Matrix to enhance model accuracy, while a model splitting function reduces computation and transmission costs. Hyperparameter tuning and ablation studies demonstrate the effectiveness of this new algorithm, showing improvements in test accuracy on gastric cancer datasets, with FedSAF outperforming existing federated learning methods like FedAMP, FedAvg, and FedProx. The framework's robustness and generalization ability were further validated across additional datasets (SEED, BOT, FashionMNIST, and CIFAR-10), achieving high performance in diverse environments.
Differentiable Information Enhanced Model-Based Reinforcement Learning
Mar 03, 2025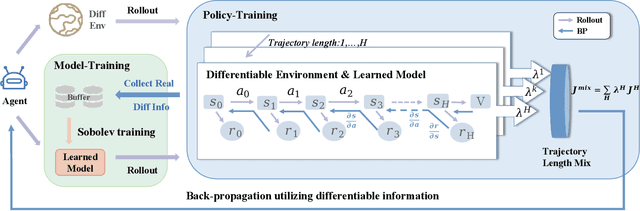
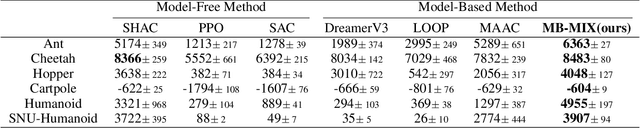
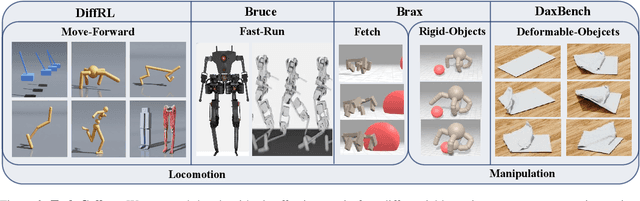

Differentiable environments have heralded new possibilities for learning control policies by offering rich differentiable information that facilitates gradient-based methods. In comparison to prevailing model-free reinforcement learning approaches, model-based reinforcement learning (MBRL) methods exhibit the potential to effectively harness the power of differentiable information for recovering the underlying physical dynamics. However, this presents two primary challenges: effectively utilizing differentiable information to 1) construct models with more accurate dynamic prediction and 2) enhance the stability of policy training. In this paper, we propose a Differentiable Information Enhanced MBRL method, MB-MIX, to address both challenges. Firstly, we adopt a Sobolev model training approach that penalizes incorrect model gradient outputs, enhancing prediction accuracy and yielding more precise models that faithfully capture system dynamics. Secondly, we introduce mixing lengths of truncated learning windows to reduce the variance in policy gradient estimation, resulting in improved stability during policy learning. To validate the effectiveness of our approach in differentiable environments, we provide theoretical analysis and empirical results. Notably, our approach outperforms previous model-based and model-free methods, in multiple challenging tasks involving controllable rigid robots such as humanoid robots' motion control and deformable object manipulation.
Safety-Gymnasium: A Unified Safe Reinforcement Learning Benchmark
Oct 19, 2023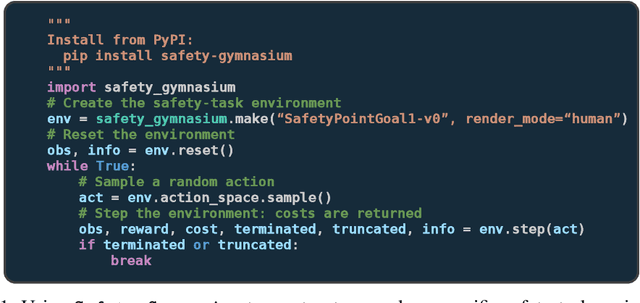
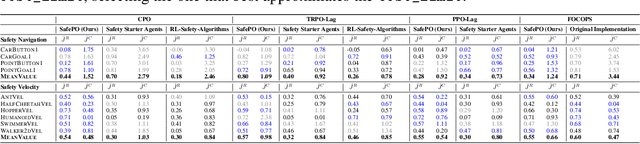

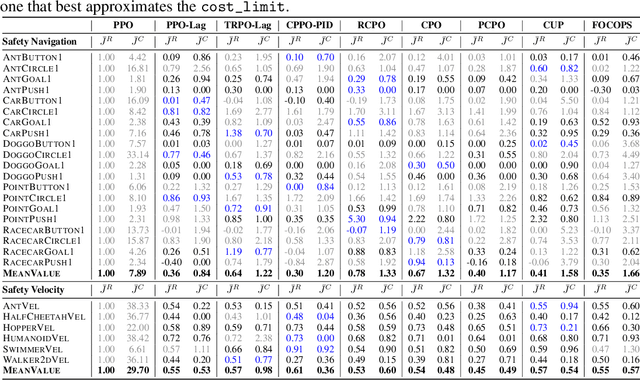
Artificial intelligence (AI) systems possess significant potential to drive societal progress. However, their deployment often faces obstacles due to substantial safety concerns. Safe reinforcement learning (SafeRL) emerges as a solution to optimize policies while simultaneously adhering to multiple constraints, thereby addressing the challenge of integrating reinforcement learning in safety-critical scenarios. In this paper, we present an environment suite called Safety-Gymnasium, which encompasses safety-critical tasks in both single and multi-agent scenarios, accepting vector and vision-only input. Additionally, we offer a library of algorithms named Safe Policy Optimization (SafePO), comprising 16 state-of-the-art SafeRL algorithms. This comprehensive library can serve as a validation tool for the research community. By introducing this benchmark, we aim to facilitate the evaluation and comparison of safety performance, thus fostering the development of reinforcement learning for safer, more reliable, and responsible real-world applications. The website of this project can be accessed at https://sites.google.com/view/safety-gymnasium.
Safe DreamerV3: Safe Reinforcement Learning with World Models
Jul 14, 2023


The widespread application of Reinforcement Learning (RL) in real-world situations is yet to come to fruition, largely as a result of its failure to satisfy the essential safety demands of such systems. Existing safe reinforcement learning (SafeRL) methods, employing cost functions to enhance safety, fail to achieve zero-cost in complex scenarios, including vision-only tasks, even with comprehensive data sampling and training. To address this, we introduce Safe DreamerV3, a novel algorithm that integrates both Lagrangian-based and planning-based methods within a world model. Our methodology represents a significant advancement in SafeRL as the first algorithm to achieve nearly zero-cost in both low-dimensional and vision-only tasks within the Safety-Gymnasium benchmark. Our project website can be found in: https://sites.google.com/view/safedreamerv3.
OmniSafe: An Infrastructure for Accelerating Safe Reinforcement Learning Research
May 16, 2023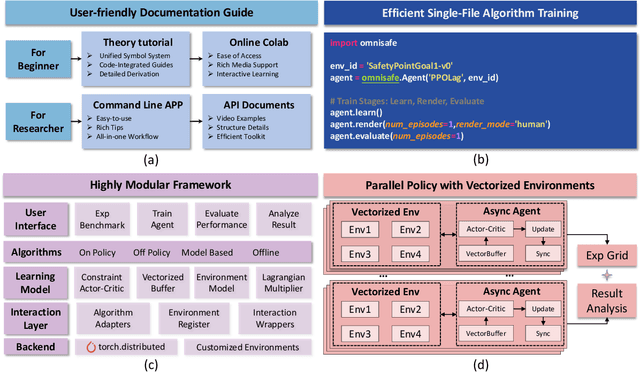
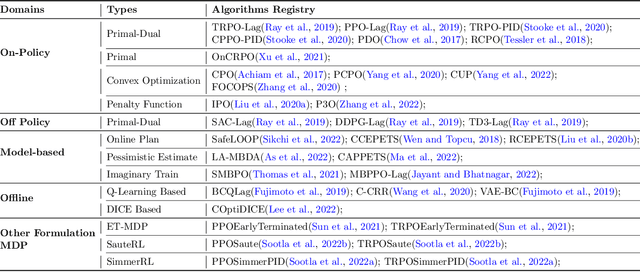
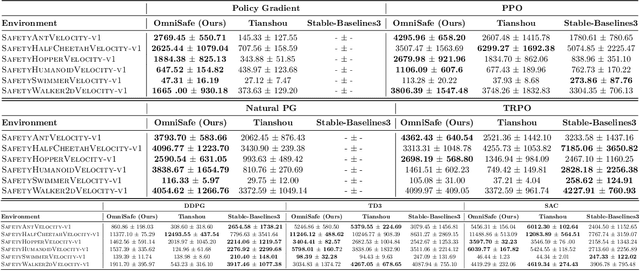
AI systems empowered by reinforcement learning (RL) algorithms harbor the immense potential to catalyze societal advancement, yet their deployment is often impeded by significant safety concerns. Particularly in safety-critical applications, researchers have raised concerns about unintended harms or unsafe behaviors of unaligned RL agents. The philosophy of safe reinforcement learning (SafeRL) is to align RL agents with harmless intentions and safe behavioral patterns. In SafeRL, agents learn to develop optimal policies by receiving feedback from the environment, while also fulfilling the requirement of minimizing the risk of unintended harm or unsafe behavior. However, due to the intricate nature of SafeRL algorithm implementation, combining methodologies across various domains presents a formidable challenge. This had led to an absence of a cohesive and efficacious learning framework within the contemporary SafeRL research milieu. In this work, we introduce a foundational framework designed to expedite SafeRL research endeavors. Our comprehensive framework encompasses an array of algorithms spanning different RL domains and places heavy emphasis on safety elements. Our efforts are to make the SafeRL-related research process more streamlined and efficient, therefore facilitating further research in AI safety. Our project is released at: https://github.com/PKU-Alignment/omnisafe.
Facilitating Machine Learning Model Comparison and Explanation Through A Radial Visualisation
Apr 15, 2021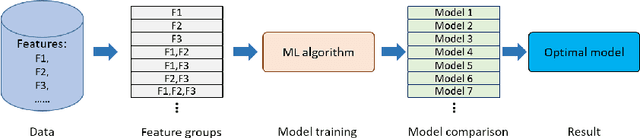
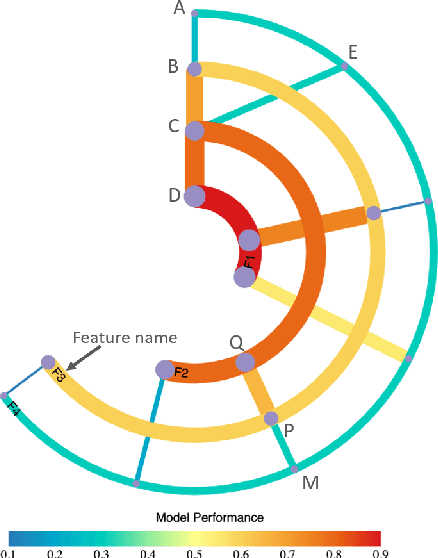
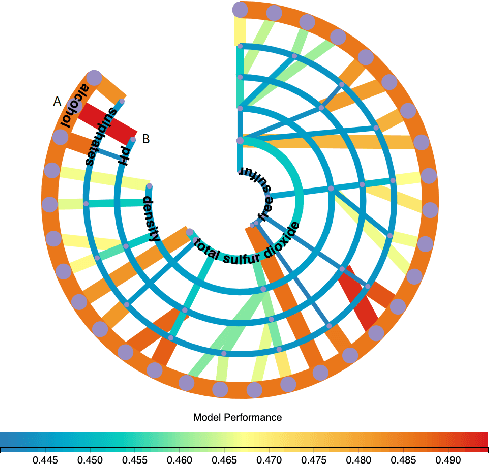
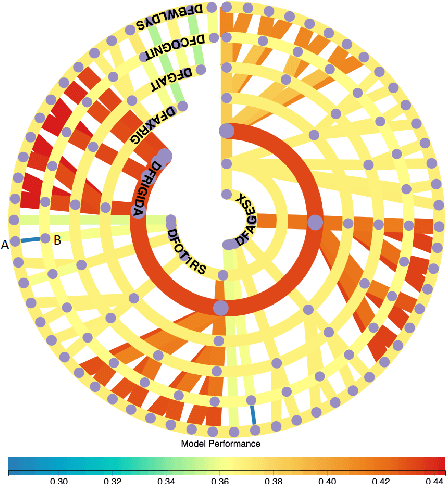
Building an effective Machine Learning (ML) model for a data set is a difficult task involving various steps. One of the most important steps is to compare generated substantial amounts of ML models to find the optimal one for the deployment. It is challenging to compare such models with dynamic number of features. Comparison is more than just finding differences of ML model performance, users are also interested in the relations between features and model performance such as feature importance for ML explanations. This paper proposes RadialNet Chart, a novel visualisation approach to compare ML models trained with a different number of features of a given data set while revealing implicit dependent relations. In RadialNet Chart, ML models and features are represented by lines and arcs respectively. These lines are generated effectively using a recursive function. The dependence of ML models with dynamic number of features is encoded into the structure of visualisation, where ML models and their dependent features are directly revealed from related line connections. ML model performance information is encoded with colour and line width in RadialNet Chart. Together with the structure of visualisation, feature importance can be directly discerned in RadialNet Chart for ML explanations.