 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRcAE: Recursive Reconstruction Framework for Unsupervised Industrial Anomaly Detection
Dec 12, 2025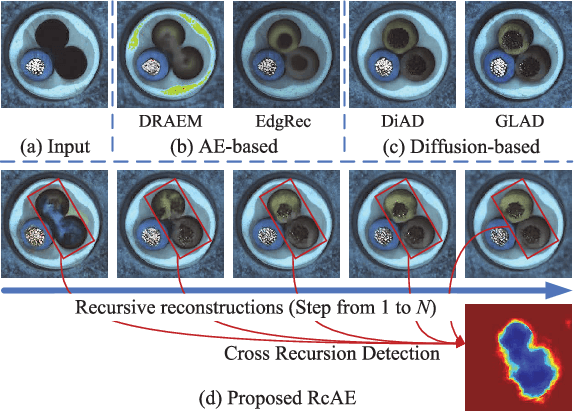
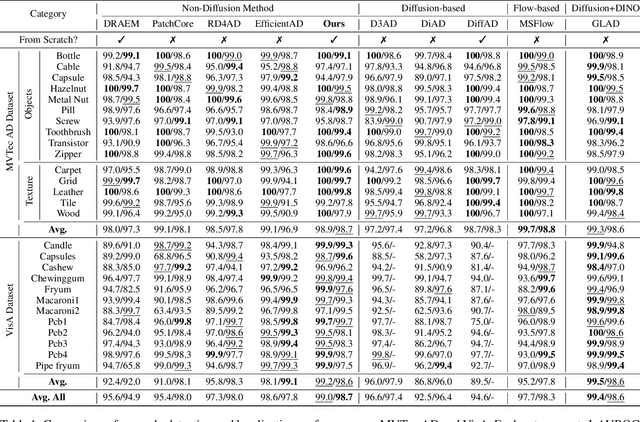
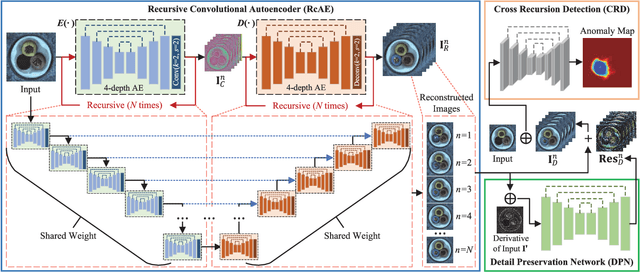
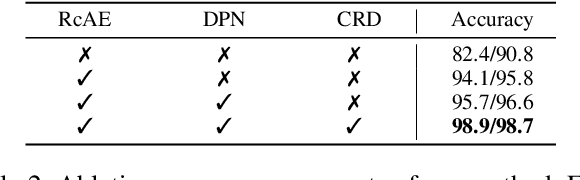
Unsupervised industrial anomaly detection requires accurately identifying defects without labeled data. Traditional autoencoder-based methods often struggle with incomplete anomaly suppression and loss of fine details, as their single-pass decoding fails to effectively handle anomalies with varying severity and scale. We propose a recursive architecture for autoencoder (RcAE), which performs reconstruction iteratively to progressively suppress anomalies while refining normal structures. Unlike traditional single-pass models, this recursive design naturally produces a sequence of reconstructions, progressively exposing suppressed abnormal patterns. To leverage this reconstruction dynamics, we introduce a Cross Recursion Detection (CRD) module that tracks inconsistencies across recursion steps, enhancing detection of both subtle and large-scale anomalies. Additionally, we incorporate a Detail Preservation Network (DPN) to recover high-frequency textures typically lost during reconstruction. Extensive experiments demonstrate that our method significantly outperforms existing non-diffusion methods, and achieves performance on par with recent diffusion models with only 10% of their parameters and offering substantially faster inference. These results highlight the practicality and efficiency of our approach for real-world applications.
A Survey of TinyML Applications in Beekeeping for Hive Monitoring and Management
Sep 10, 2025Honey bee colonies are essential for global food security and ecosystem stability, yet they face escalating threats from pests, diseases, and environmental stressors. Traditional hive inspections are labor-intensive and disruptive, while cloud-based monitoring solutions remain impractical for remote or resource-limited apiaries. Recent advances in Internet of Things (IoT) and Tiny Machine Learning (TinyML) enable low-power, real-time monitoring directly on edge devices, offering scalable and non-invasive alternatives. This survey synthesizes current innovations at the intersection of TinyML and apiculture, organized around four key functional areas: monitoring hive conditions, recognizing bee behaviors, detecting pests and diseases, and forecasting swarming events. We further examine supporting resources, including publicly available datasets, lightweight model architectures optimized for embedded deployment, and benchmarking strategies tailored to field constraints. Critical limitations such as data scarcity, generalization challenges, and deployment barriers in off-grid environments are highlighted, alongside emerging opportunities in ultra-efficient inference pipelines, adaptive edge learning, and dataset standardization. By consolidating research and engineering practices, this work provides a foundation for scalable, AI-driven, and ecologically informed monitoring systems to support sustainable pollinator management.
ABE: A Unified Framework for Robust and Faithful Attribution-Based Explainability
May 03, 2025Attribution algorithms are essential for enhancing the interpretability and trustworthiness of deep learning models by identifying key features driving model decisions. Existing frameworks, such as InterpretDL and OmniXAI, integrate multiple attribution methods but suffer from scalability limitations, high coupling, theoretical constraints, and lack of user-friendly implementations, hindering neural network transparency and interoperability. To address these challenges, we propose Attribution-Based Explainability (ABE), a unified framework that formalizes Fundamental Attribution Methods and integrates state-of-the-art attribution algorithms while ensuring compliance with attribution axioms. ABE enables researchers to develop novel attribution techniques and enhances interpretability through four customizable modules: Robustness, Interpretability, Validation, and Data & Model. This framework provides a scalable, extensible foundation for advancing attribution-based explainability and fostering transparent AI systems. Our code is available at: https://github.com/LMBTough/ABE-XAI.
Can LLM Assist in the Evaluation of the Quality of Machine Learning Explanations?
Feb 28, 2025EXplainable machine learning (XML) has recently emerged to address the mystery mechanisms of machine learning (ML) systems by interpreting their 'black box' results. Despite the development of various explanation methods, determining the most suitable XML method for specific ML contexts remains unclear, highlighting the need for effective evaluation of explanations. The evaluating capabilities of the Transformer-based large language model (LLM) present an opportunity to adopt LLM-as-a-Judge for assessing explanations. In this paper, we propose a workflow that integrates both LLM-based and human judges for evaluating explanations. We examine how LLM-based judges evaluate the quality of various explanation methods and compare their evaluation capabilities to those of human judges within an iris classification scenario, employing both subjective and objective metrics. We conclude that while LLM-based judges effectively assess the quality of explanations using subjective metrics, they are not yet sufficiently developed to replace human judges in this role.
DeFusion: An Effective Decoupling Fusion Network for Multi-Modal Pregnancy Prediction
Jan 08, 2025
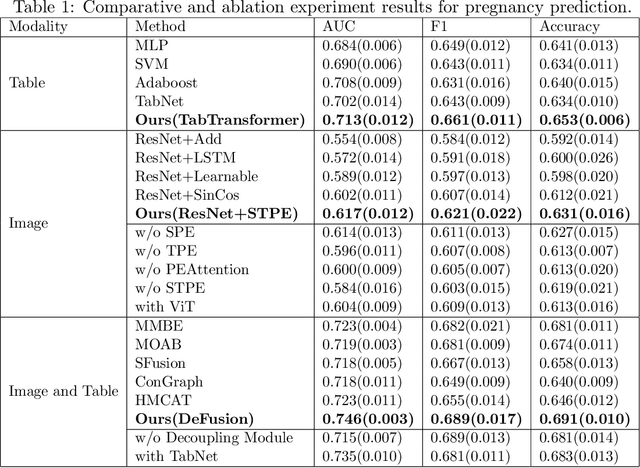
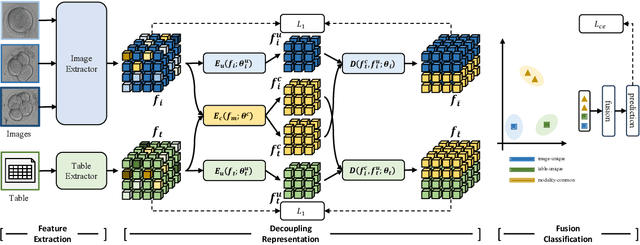
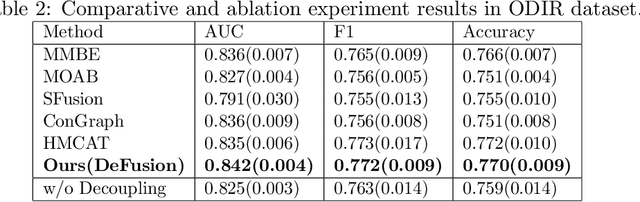
Temporal embryo images and parental fertility table indicators are both valuable for pregnancy prediction in \textbf{in vitro fertilization embryo transfer} (IVF-ET). However, current machine learning models cannot make full use of the complementary information between the two modalities to improve pregnancy prediction performance. In this paper, we propose a Decoupling Fusion Network called DeFusion to effectively integrate the multi-modal information for IVF-ET pregnancy prediction. Specifically, we propose a decoupling fusion module that decouples the information from the different modalities into related and unrelated information, thereby achieving a more delicate fusion. And we fuse temporal embryo images with a spatial-temporal position encoding, and extract fertility table indicator information with a table transformer. To evaluate the effectiveness of our model, we use a new dataset including 4046 cases collected from Southern Medical University. The experiments show that our model outperforms state-of-the-art methods. Meanwhile, the performance on the eye disease prediction dataset reflects the model's good generalization. Our code and dataset are available at https://github.com/Ou-Young-1999/DFNet.
Attribution for Enhanced Explanation with Transferable Adversarial eXploration
Dec 27, 2024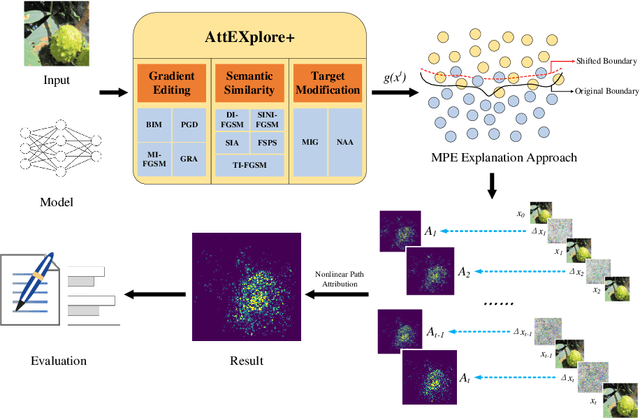
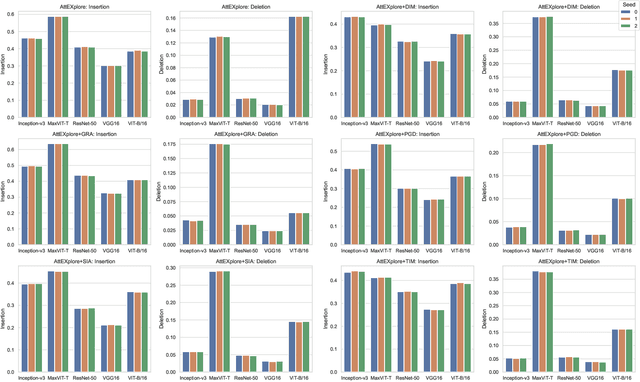
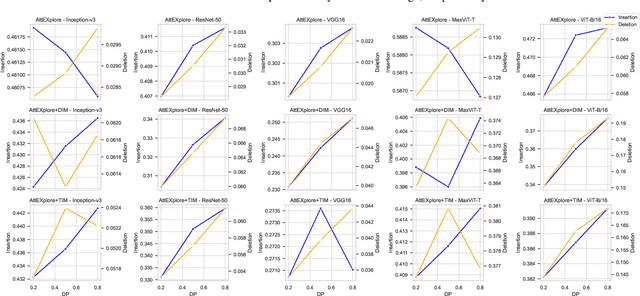
The interpretability of deep neural networks is crucial for understanding model decisions in various applications, including computer vision. AttEXplore++, an advanced framework built upon AttEXplore, enhances attribution by incorporating transferable adversarial attack methods such as MIG and GRA, significantly improving the accuracy and robustness of model explanations. We conduct extensive experiments on five models, including CNNs (Inception-v3, ResNet-50, VGG16) and vision transformers (MaxViT-T, ViT-B/16), using the ImageNet dataset. Our method achieves an average performance improvement of 7.57\% over AttEXplore and 32.62\% compared to other state-of-the-art interpretability algorithms. Using insertion and deletion scores as evaluation metrics, we show that adversarial transferability plays a vital role in enhancing attribution results. Furthermore, we explore the impact of randomness, perturbation rate, noise amplitude, and diversity probability on attribution performance, demonstrating that AttEXplore++ provides more stable and reliable explanations across various models. We release our code at: https://anonymous.4open.science/r/ATTEXPLOREP-8435/
Enhancing Transferability of Adversarial Attacks with GE-AdvGAN+: A Comprehensive Framework for Gradient Editing
Aug 22, 2024

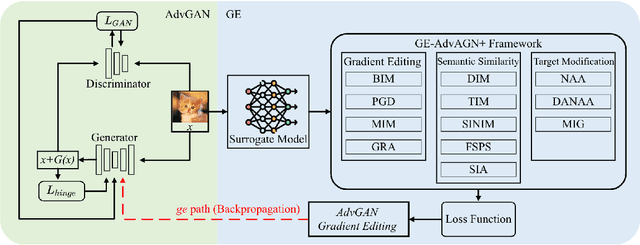

Transferable adversarial attacks pose significant threats to deep neural networks, particularly in black-box scenarios where internal model information is inaccessible. Studying adversarial attack methods helps advance the performance of defense mechanisms and explore model vulnerabilities. These methods can uncover and exploit weaknesses in models, promoting the development of more robust architectures. However, current methods for transferable attacks often come with substantial computational costs, limiting their deployment and application, especially in edge computing scenarios. Adversarial generative models, such as Generative Adversarial Networks (GANs), are characterized by their ability to generate samples without the need for retraining after an initial training phase. GE-AdvGAN, a recent method for transferable adversarial attacks, is based on this principle. In this paper, we propose a novel general framework for gradient editing-based transferable attacks, named GE-AdvGAN+, which integrates nearly all mainstream attack methods to enhance transferability while significantly reducing computational resource consumption. Our experiments demonstrate the compatibility and effectiveness of our framework. Compared to the baseline AdvGAN, our best-performing method, GE-AdvGAN++, achieves an average ASR improvement of 47.8. Additionally, it surpasses the latest competing algorithm, GE-AdvGAN, with an average ASR increase of 5.9. The framework also exhibits enhanced computational efficiency, achieving 2217.7 FPS, outperforming traditional methods such as BIM and MI-FGSM. The implementation code for our GE-AdvGAN+ framework is available at https://github.com/GEAdvGANP
Enhancing Adversarial Attacks via Parameter Adaptive Adversarial Attack
Aug 14, 2024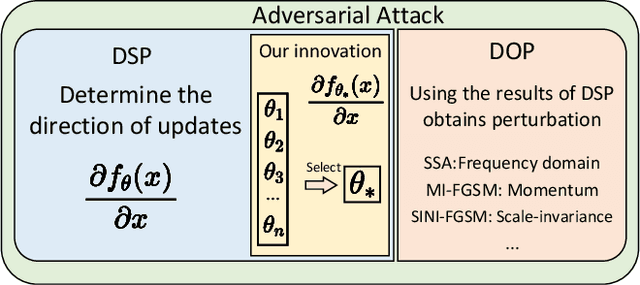
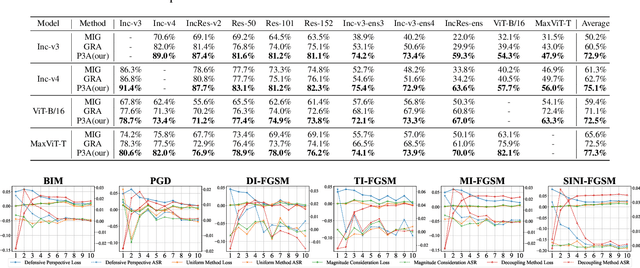
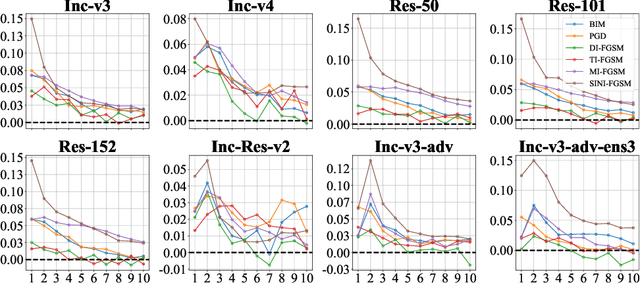
In recent times, the swift evolution of adversarial attacks has captured widespread attention, particularly concerning their transferability and other performance attributes. These techniques are primarily executed at the sample level, frequently overlooking the intrinsic parameters of models. Such neglect suggests that the perturbations introduced in adversarial samples might have the potential for further reduction. Given the essence of adversarial attacks is to impair model integrity with minimal noise on original samples, exploring avenues to maximize the utility of such perturbations is imperative. Against this backdrop, we have delved into the complexities of adversarial attack algorithms, dissecting the adversarial process into two critical phases: the Directional Supervision Process (DSP) and the Directional Optimization Process (DOP). While DSP determines the direction of updates based on the current samples and model parameters, it has been observed that existing model parameters may not always be conducive to adversarial attacks. The impact of models on adversarial efficacy is often overlooked in current research, leading to the neglect of DSP. We propose that under certain conditions, fine-tuning model parameters can significantly enhance the quality of DSP. For the first time, we propose that under certain conditions, fine-tuning model parameters can significantly improve the quality of the DSP. We provide, for the first time, rigorous mathematical definitions and proofs for these conditions, and introduce multiple methods for fine-tuning model parameters within DSP. Our extensive experiments substantiate the effectiveness of the proposed P3A method. Our code is accessible at: https://anonymous.4open.science/r/P3A-A12C/
Interpretable Robotic Manipulation from Language
May 27, 2024
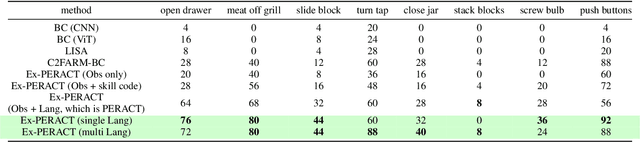


Humans naturally employ linguistic instructions to convey knowledge, a process that proves significantly more complex for machines, especially within the context of multitask robotic manipulation environments. Natural language, moreover, serves as the primary medium through which humans acquire new knowledge, presenting a potentially intuitive bridge for translating concepts understandable by humans into formats that can be learned by machines. In pursuit of facilitating this integration, we introduce an explainable behavior cloning agent, named Ex-PERACT, specifically designed for manipulation tasks. This agent is distinguished by its hierarchical structure, which incorporates natural language to enhance the learning process. At the top level, the model is tasked with learning a discrete skill code, while at the bottom level, the policy network translates the problem into a voxelized grid and maps the discretized actions to voxel grids. We evaluate our method across eight challenging manipulation tasks utilizing the RLBench benchmark, demonstrating that Ex-PERACT not only achieves competitive policy performance but also effectively bridges the gap between human instructions and machine execution in complex environments.
ACGAN-GNNExplainer: Auxiliary Conditional Generative Explainer for Graph Neural Networks
Oct 11, 2023Graph neural networks (GNNs) have proven their efficacy in a variety of real-world applications, but their underlying mechanisms remain a mystery. To address this challenge and enable reliable decision-making, many GNN explainers have been proposed in recent years. However, these methods often encounter limitations, including their dependence on specific instances, lack of generalizability to unseen graphs, producing potentially invalid explanations, and yielding inadequate fidelity. To overcome these limitations, we, in this paper, introduce the Auxiliary Classifier Generative Adversarial Network (ACGAN) into the field of GNN explanation and propose a new GNN explainer dubbed~\emph{ACGAN-GNNExplainer}. Our approach leverages a generator to produce explanations for the original input graphs while incorporating a discriminator to oversee the generation process, ensuring explanation fidelity and improving accuracy. Experimental evaluations conducted on both synthetic and real-world graph datasets demonstrate the superiority of our proposed method compared to other existing GNN explainers.