 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForCM: Forest Cover Mapping from Multispectral Sentinel-2 Image by Integrating Deep Learning with Object-Based Image Analysis
Dec 29, 2025This research proposes "ForCM", a novel approach to forest cover mapping that combines Object-Based Image Analysis (OBIA) with Deep Learning (DL) using multispectral Sentinel-2 imagery. The study explores several DL models, including UNet, UNet++, ResUNet, AttentionUNet, and ResNet50-Segnet, applied to high-resolution Sentinel-2 Level 2A satellite images of the Amazon Rainforest. The datasets comprise three collections: two sets of three-band imagery and one set of four-band imagery. After evaluation, the most effective DL models are individually integrated with the OBIA technique to enhance mapping accuracy. The originality of this work lies in evaluating different deep learning models combined with OBIA and comparing them with traditional OBIA methods. The results show that the proposed ForCM method improves forest cover mapping, achieving overall accuracies of 94.54 percent with ResUNet-OBIA and 95.64 percent with AttentionUNet-OBIA, compared to 92.91 percent using traditional OBIA. This research also demonstrates the potential of free and user-friendly tools such as QGIS for accurate mapping within their limitations, supporting global environmental monitoring and conservation efforts.
Solving the multiplication problem of a large language model system using a graph-based method
Oct 18, 2023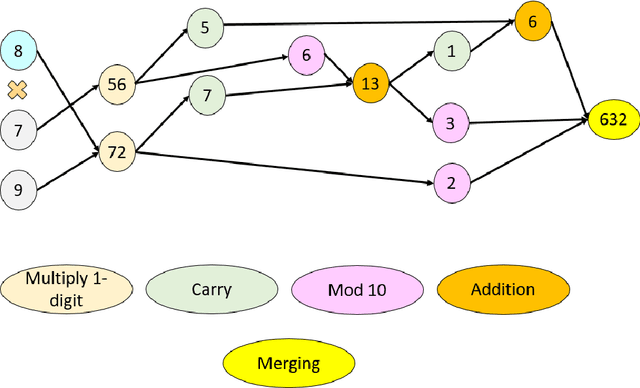
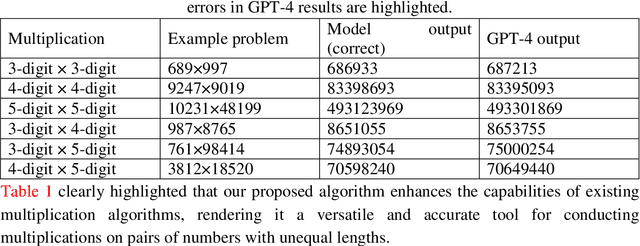

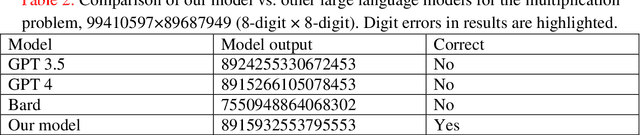
The generative pre-trained transformer (GPT)-based chatbot software ChatGPT possesses excellent natural language processing capabilities but is inadequate for solving arithmetic problems, especially multiplication. Its GPT structure uses a computational graph for multiplication, which has limited accuracy beyond simple multiplication operations. We developed a graph-based multiplication algorithm that emulated human-like numerical operations by incorporating a 10k operator, where k represents the maximum power to base 10 of the larger of two input numbers. Our proposed algorithm attained 100% accuracy for 1,000,000 large number multiplication tasks, effectively solving the multiplication challenge of GPT-based and other large language models. Our work highlights the importance of blending simple human insights into the design of artificial intelligence algorithms. Keywords: Graph-based multiplication; ChatGPT; Multiplication problem
Full-resolution Lung Nodule Segmentation from Chest X-ray Images using Residual Encoder-Decoder Networks
Jul 13, 2023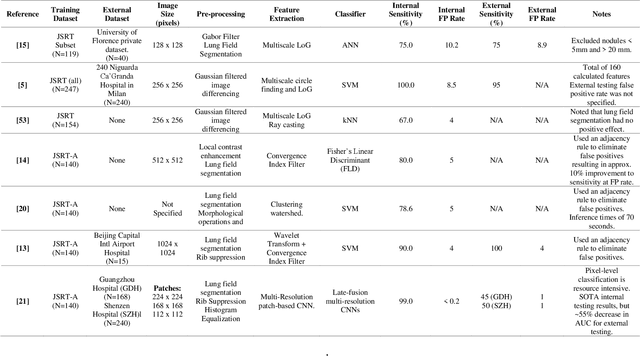
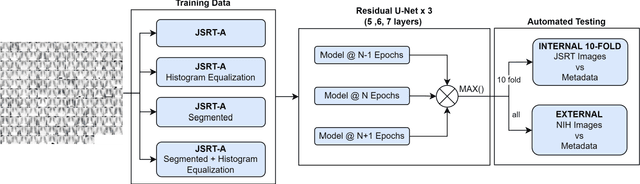

Lung cancer is the leading cause of cancer death and early diagnosis is associated with a positive prognosis. Chest X-ray (CXR) provides an inexpensive imaging mode for lung cancer diagnosis. Suspicious nodules are difficult to distinguish from vascular and bone structures using CXR. Computer vision has previously been proposed to assist human radiologists in this task, however, leading studies use down-sampled images and computationally expensive methods with unproven generalization. Instead, this study localizes lung nodules using efficient encoder-decoder neural networks that process full resolution images to avoid any signal loss resulting from down-sampling. Encoder-decoder networks are trained and tested using the JSRT lung nodule dataset. The networks are used to localize lung nodules from an independent external CXR dataset. Sensitivity and false positive rates are measured using an automated framework to eliminate any observer subjectivity. These experiments allow for the determination of the optimal network depth, image resolution and pre-processing pipeline for generalized lung nodule localization. We find that nodule localization is influenced by subtlety, with more subtle nodules being detected in earlier training epochs. Therefore, we propose a novel self-ensemble model from three consecutive epochs centered on the validation optimum. This ensemble achieved a sensitivity of 85% in 10-fold internal testing with false positives of 8 per image. A sensitivity of 81% is achieved at a false positive rate of 6 following morphological false positive reduction. This result is comparable to more computationally complex systems based on linear and spatial filtering, but with a sub-second inference time that is faster than other methods. The proposed algorithm achieved excellent generalization results against an external dataset with sensitivity of 77% at a false positive rate of 7.6.
2-speed network ensemble for efficient classification of incremental land-use/land-cover satellite image chips
Mar 15, 2022
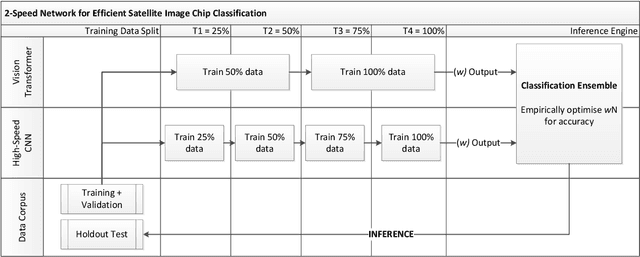


The ever-growing volume of satellite imagery data presents a challenge for industry and governments making data-driven decisions based on the timely analysis of very large data sets. Commonly used deep learning algorithms for automatic classification of satellite images are time and resource-intensive to train. The cost of retraining in the context of Big Data presents a practical challenge when new image data and/or classes are added to a training corpus. Recognizing the need for an adaptable, accurate, and scalable satellite image chip classification scheme, in this research we present an ensemble of: i) a slow to train but high accuracy vision transformer; and ii) a fast to train, low-parameter convolutional neural network. The vision transformer model provides a scalable and accurate foundation model. The high-speed CNN provides an efficient means of incorporating newly labelled data into analysis, at the expense of lower accuracy. To simulate incremental data, the very large (~400,000 images) So2Sat LCZ42 satellite image chip dataset is divided into four intervals, with the high-speed CNN retrained every interval and the vision transformer trained every half interval. This experimental setup mimics an increase in data volume and diversity over time. For the task of automated land-cover/land-use classification, the ensemble models for each data increment outperform each of the component models, with best accuracy of 65% against a holdout test partition of the So2Sat dataset. The proposed ensemble and staggered training schedule provide a scalable and cost-effective satellite image classification scheme that is optimized to process very large volumes of satellite data.
Debiasing pipeline improves deep learning model generalization for X-ray based lung nodule detection
Jan 24, 2022
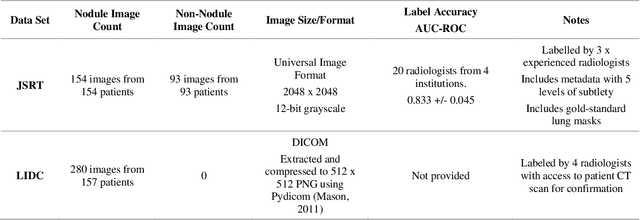


Lung cancer is the leading cause of cancer death worldwide and a good prognosis depends on early diagnosis. Unfortunately, screening programs for the early diagnosis of lung cancer are uncommon. This is in-part due to the at-risk groups being located in rural areas far from medical facilities. Reaching these populations would require a scaled approach that combines mobility, low cost, speed, accuracy, and privacy. We can resolve these issues by combining the chest X-ray imaging mode with a federated deep-learning approach, provided that the federated model is trained on homogenous data to ensure that no single data source can adversely bias the model at any point in time. In this study we show that an image pre-processing pipeline that homogenizes and debiases chest X-ray images can improve both internal classification and external generalization, paving the way for a low-cost and accessible deep learning-based clinical system for lung cancer screening. An evolutionary pruning mechanism is used to train a nodule detection deep learning model on the most informative images from a publicly available lung nodule X-ray dataset. Histogram equalization is used to remove systematic differences in image brightness and contrast. Model training is performed using all combinations of lung field segmentation, close cropping, and rib suppression operators. We show that this pre-processing pipeline results in deep learning models that successfully generalize an independent lung nodule dataset using ablation studies to assess the contribution of each operator in this pipeline. In stripping chest X-ray images of known confounding variables by lung field segmentation, along with suppression of signal noise from the bone structure we can train a highly accurate deep learning lung nodule detection algorithm with outstanding generalization accuracy of 89% to nodule samples in unseen data.
Automatic Generation of Interpretable Lung Cancer Scoring Models from Chest X-Ray Images
Dec 17, 2020
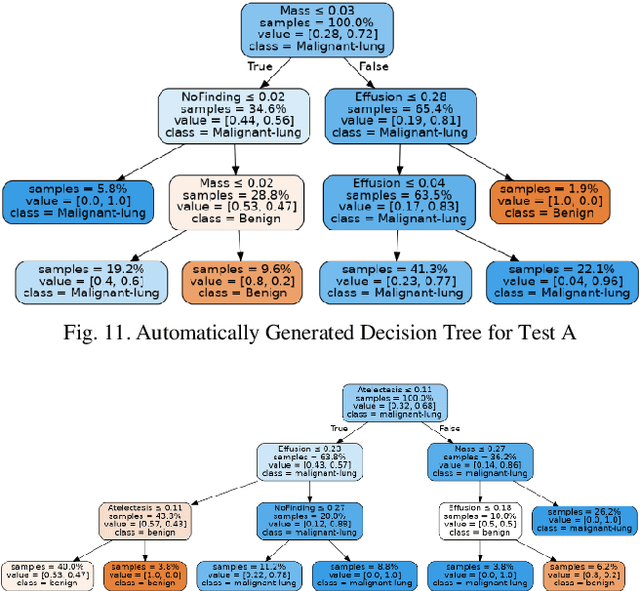
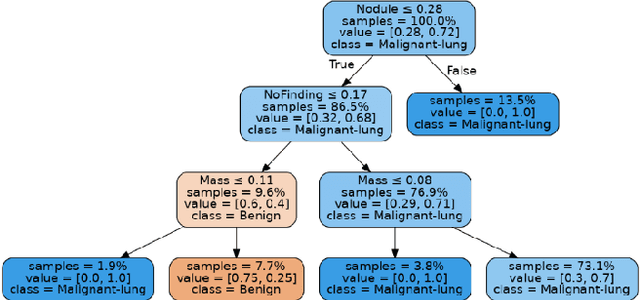
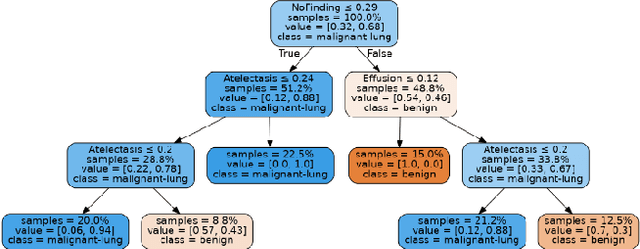
Lung cancer is the leading cause of cancer death worldwide with early detection being the key to a positive patient prognosis. Although a multitude of studies have demonstrated that machine learning, and particularly deep learning, techniques are effective at automatically diagnosing lung cancer, these techniques have yet to be clinically approved and adopted by the medical community. Most research in this field is focused on the narrow task of nodule detection to provide an artificial radiological second reading. We instead focus on extracting, from chest X-ray images, a wider range of pathologies associated with lung cancer using a computer vision model trained on a large dataset. We then find the set of best fit decision trees against an independent, smaller dataset for which lung cancer malignancy metadata is provided. For this small inferencing dataset, our best model achieves sensitivity and specificity of 85% and 75% respectively with a positive predictive value of 85% which is comparable to the performance of human radiologists. Furthermore, the decision trees created by this method may be considered as a starting point for refinement by medical experts into clinically usable multi-variate lung cancer scoring and diagnostic models.
MAVIDH Score: A COVID-19 Severity Scoring using Chest X-Ray Pathology Features
Dec 01, 2020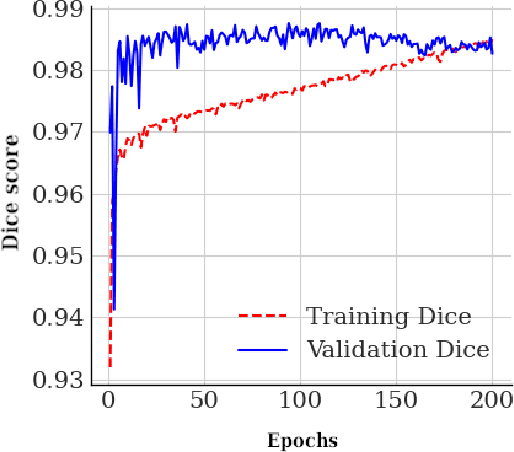
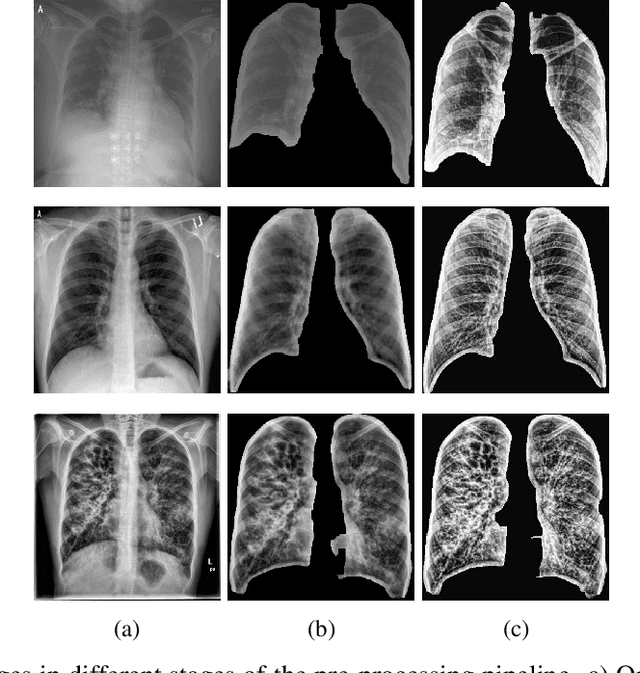
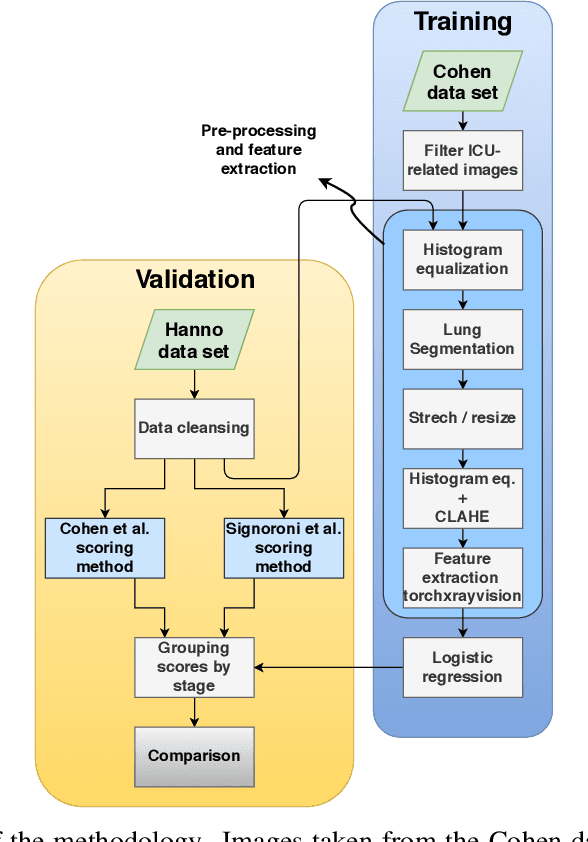
The application of computer vision for COVID-19 diagnosis is complex and challenging, given the risks associated with patient misclassifications. Arguably, the primary value of medical imaging for COVID-19 lies rather on patient prognosis. Radiological images can guide physicians assessing the severity of the disease, and a series of images from the same patient at different stages can help to gauge disease progression. Based on these premises, a simple method based on lung-pathology features for scoring disease severity from Chest X-rays is proposed here. As the primary contribution, this method shows to be correlated to patient severity in different stages of disease progression comparatively well when contrasted with other existing methods. An original approach for data selection is also proposed, allowing the simple model to learn the severity-related features. It is hypothesized that the resulting competitive performance presented here is related to the method being feature-based rather than reliant on lung involvement or compromise as others in the literature. The fact that it is simpler and interpretable than other end-to-end, more complex models, also sets aside this work. As the data set is small, bias-inducing artifacts that could lead to overfitting are minimized through an image normalization and lung segmentation step at the learning phase. A second contribution comes from the validation of the results, conceptualized as the scoring of patients groups from different stages of the disease. Besides performing such validation on an independent data set, the results were also compared with other proposed scoring methods in the literature. The expressive results show that although imaging alone is not sufficient for assessing severity as a whole, there is a strong correlation with the scoring system, termed as MAVIDH score, with patient outcome.
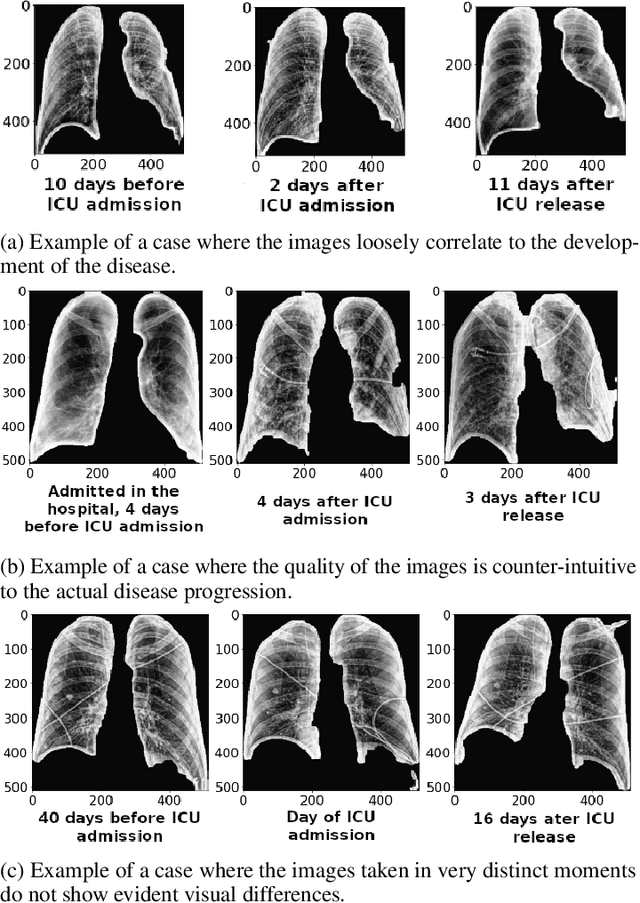
Potential Features of ICU Admission in X-ray Images of COVID-19 Patients
Sep 26, 2020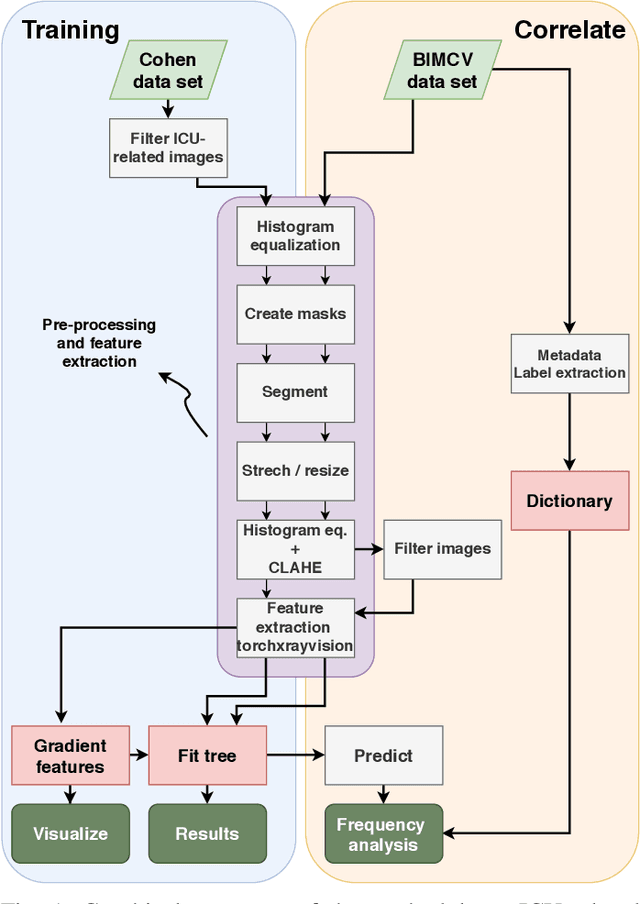
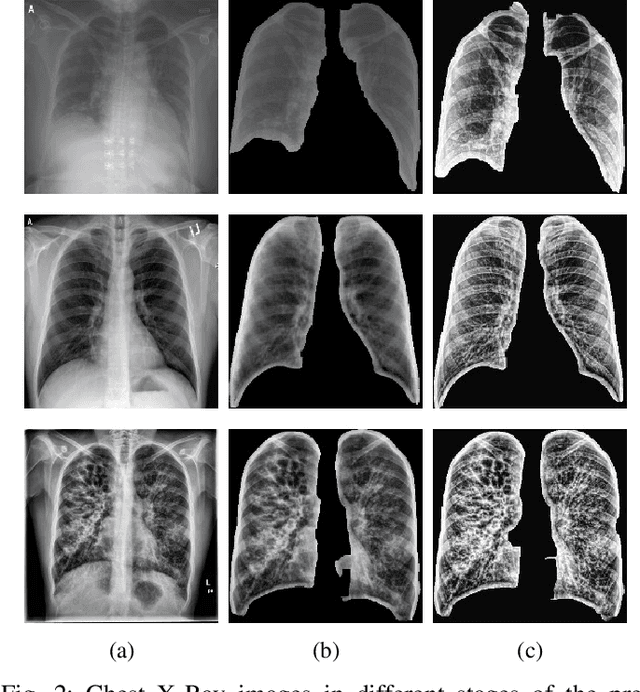
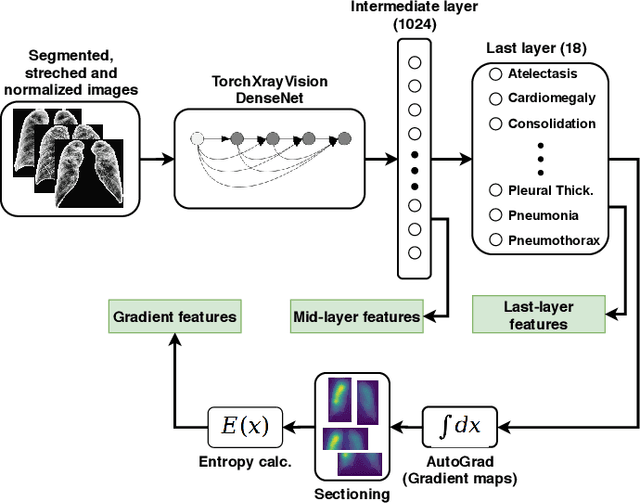

X-ray images may present non-trivial features with predictive information of patients that develop severe symptoms of COVID-19. If true, this hypothesis may have practical value in allocating resources to particular patients while using a relatively inexpensive imaging technique. The difficulty of testing such a hypothesis comes from the need for large sets of labelled data, which not only need to be well-annotated but also should contemplate the post-imaging severity outcome. On this account, this paper presents a methodology for extracting features from a limited data set with outcome label (patient required ICU admission or not) and correlating its significance to an additional, larger data set with hundreds of images. The methodology employs a neural network trained to recognise lung pathologies to extract the semantic features, which are then analysed with a shallow decision tree to limit overfitting while increasing interpretability. This analysis points out that only a few features explain most of the variance between patients that developed severe symptoms. When applied to an unrelated, larger data set with labels extracted from clinical notes, the method classified distinct sets of samples where there was a much higher frequency of labels such as `Consolidation', `Effusion', and `alveolar'. A further brief analysis on the locations of such labels also showed a significant increase in the frequency of words like `bilateral', `middle', and `lower' in patients classified as with higher chances of going severe. The methodology for dealing with the lack of specific ICU label data while attesting correlations with a data set containing text notes is novel; its results suggest that some pathologies should receive higher weights when assessing disease severity.
Changing Clusters of Indian States with respect to number of Cases of COVID-19 using incrementalKMN Method
Jul 12, 2020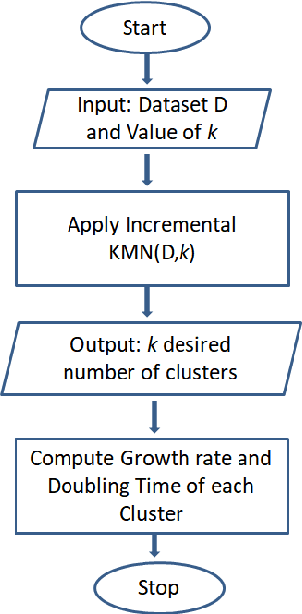
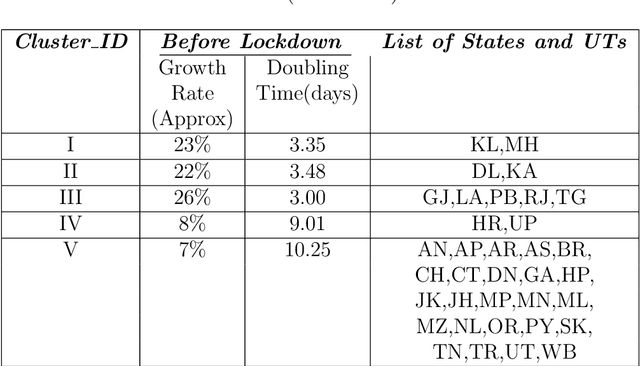
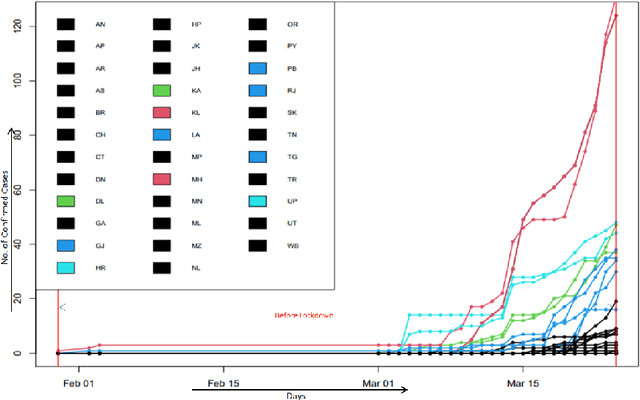
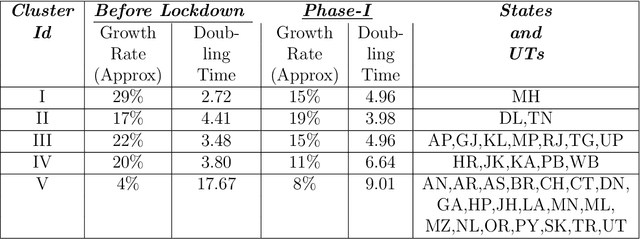
The novel Coronavirus (COVID-19) incidence in India is currently experiencing exponential rise but with apparent spatial variation in growth rate and doubling time rate. We classify the states into five clusters with low to the high-risk category and study how the different states moved from one cluster to the other since the onset of the first case on $30^{th}$ January 2020 till the end of unlock 1 that is $30^{th}$ June 2020. We have implemented a new clustering technique called the incrementalKMN (Prasad, R. K., Sarmah, R., Chakraborty, S.(2019))
A Practical Blockchain Framework using Image Hashing for Image Authentication
Apr 15, 2020
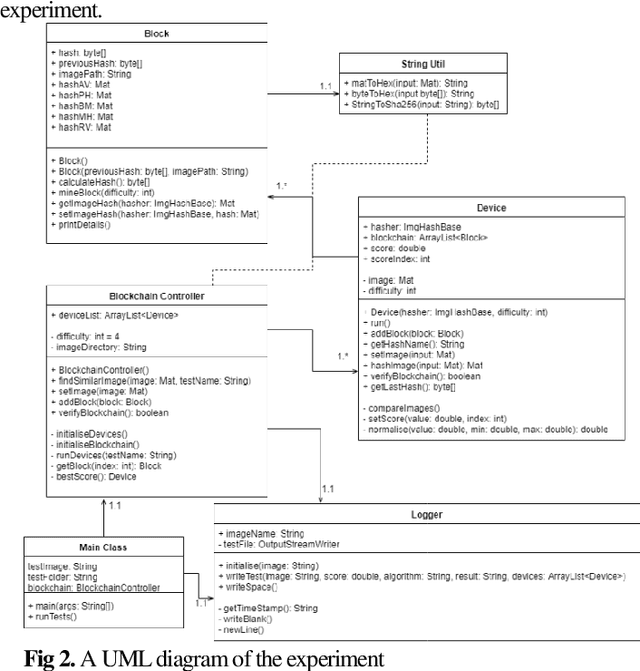
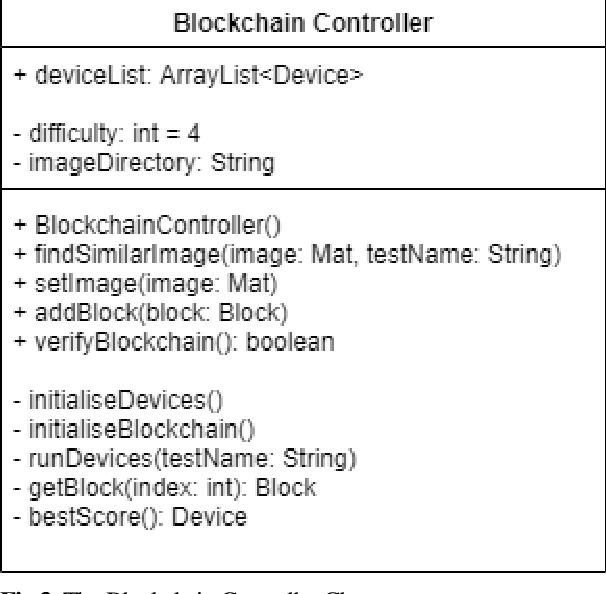
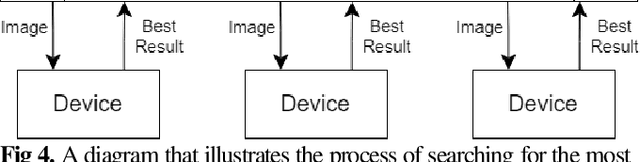
Blockchain is a relatively new technology that can be seen as a decentralised database. Blockchain systems heavily rely on cryptographic hash functions to store their data, which makes it difficult to tamper with any data stored in the system. A topic that was researched along with blockchain is image authentication. Image authentication focuses on investigating and maintaining the integrity of images. As a blockchain system can be useful for maintaining data integrity, image authentication has the potential to be enhanced by blockchain. There are many techniques that can be used to authenticate images; the technique investigated by this work is image hashing. Image hashing is a technique used to calculate how similar two different images are. This is done by converting the images into hashes and then comparing them using a distance formula. To investigate the topic, an experiment involving a simulated blockchain was created. The blockchain acted as a database for images. This blockchain was made up of devices which contained their own unique image hashing algorithms. The blockchain was tested by creating modified copies of the images contained in the database, and then submitting them to the blockchain to see if it will return the original image. Through this experiment it was discovered that it is plausible to create an image authentication system using blockchain and image hashing. However, the design proposed by this work requires refinement, as it appears to struggle in some situations. This work shows that blockchain can be a suitable approach for authenticating images, particularly via image hashing. Other observations include that using multiple image hash algorithms at the same time can increase performance in some cases, as well as that each type of test done to the blockchain has its own unique pattern to its data.