 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointDiffuse: A Dual-Conditional Diffusion Model for Enhanced Point Cloud Semantic Segmentation
Mar 11, 2025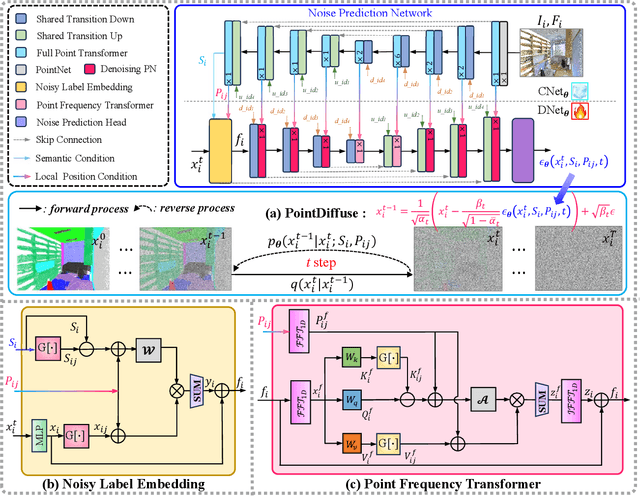



Diffusion probabilistic models are traditionally used to generate colors at fixed pixel positions in 2D images. Building on this, we extend diffusion models to point cloud semantic segmentation, where point positions also remain fixed, and the diffusion model generates point labels instead of colors. To accelerate the denoising process in reverse diffusion, we introduce a noisy label embedding mechanism. This approach integrates semantic information into the noisy label, providing an initial semantic reference that improves the reverse diffusion efficiency. Additionally, we propose a point frequency transformer that enhances the adjustment of high-level context in point clouds. To reduce computational complexity, we introduce the position condition into MLP and propose denoising PointNet to process the high-resolution point cloud without sacrificing geometric details. Finally, we integrate the proposed noisy label embedding, point frequency transformer and denoising PointNet in our proposed dual conditional diffusion model-based network (PointDiffuse) to perform large-scale point cloud semantic segmentation. Extensive experiments on five benchmarks demonstrate the superiority of PointDiffuse, achieving the state-of-the-art mIoU of 74.2\% on S3DIS Area 5, 81.2\% on S3DIS 6-fold and 64.8\% on SWAN dataset.
Video Anomaly Detection in 10 Years: A Survey and Outlook
May 29, 2024



Video anomaly detection (VAD) holds immense importance across diverse domains such as surveillance, healthcare, and environmental monitoring. While numerous surveys focus on conventional VAD methods, they often lack depth in exploring specific approaches and emerging trends. This survey explores deep learning-based VAD, expanding beyond traditional supervised training paradigms to encompass emerging weakly supervised, self-supervised, and unsupervised approaches. A prominent feature of this review is the investigation of core challenges within the VAD paradigms including large-scale datasets, features extraction, learning methods, loss functions, regularization, and anomaly score prediction. Moreover, this review also investigates the vision language models (VLMs) as potent feature extractors for VAD. VLMs integrate visual data with textual descriptions or spoken language from videos, enabling a nuanced understanding of scenes crucial for anomaly detection. By addressing these challenges and proposing future research directions, this review aims to foster the development of robust and efficient VAD systems leveraging the capabilities of VLMs for enhanced anomaly detection in complex real-world scenarios. This comprehensive analysis seeks to bridge existing knowledge gaps, provide researchers with valuable insights, and contribute to shaping the future of VAD research.
Neuromorphic Correlates of Artificial Consciousness
May 03, 2024The concept of neural correlates of consciousness (NCC), which suggests that specific neural activities are linked to conscious experiences, has gained widespread acceptance. This acceptance is based on a wealth of evidence from experimental studies, brain imaging techniques such as fMRI and EEG, and theoretical frameworks like integrated information theory (IIT) within neuroscience and the philosophy of mind. This paper explores the potential for artificial consciousness by merging neuromorphic design and architecture with brain simulations. It proposes the Neuromorphic Correlates of Artificial Consciousness (NCAC) as a theoretical framework. While the debate on artificial consciousness remains contentious due to our incomplete grasp of consciousness, this work may raise eyebrows and invite criticism. Nevertheless, this optimistic and forward-thinking approach is fueled by insights from the Human Brain Project, advancements in brain imaging like EEG and fMRI, and recent strides in AI and computing, including quantum and neuromorphic designs. Additionally, this paper outlines how machine learning can play a role in crafting artificial consciousness, aiming to realise machine consciousness and awareness in the future.
Soft Masked Transformer for Point Cloud Processing with Skip Attention-Based Upsampling
Mar 21, 2024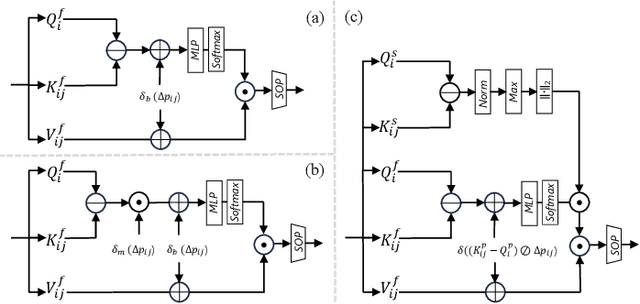
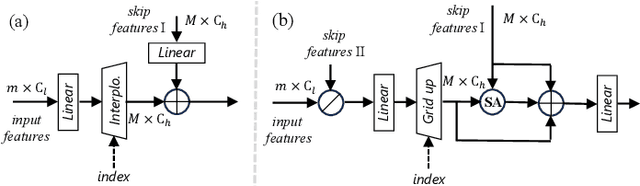
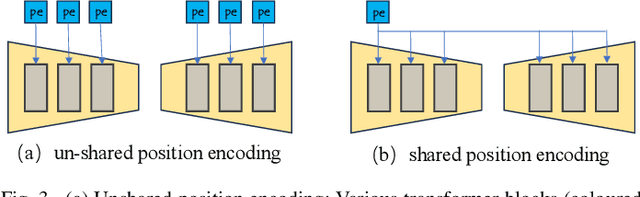
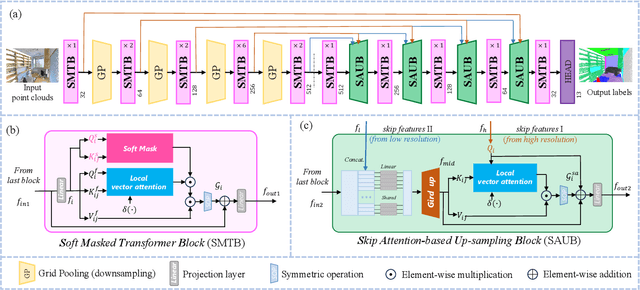
Point cloud processing methods leverage local and global point features %at the feature level to cater to downstream tasks, yet they often overlook the task-level context inherent in point clouds during the encoding stage. We argue that integrating task-level information into the encoding stage significantly enhances performance. To that end, we propose SMTransformer which incorporates task-level information into a vector-based transformer by utilizing a soft mask generated from task-level queries and keys to learn the attention weights. Additionally, to facilitate effective communication between features from the encoding and decoding layers in high-level tasks such as segmentation, we introduce a skip-attention-based up-sampling block. This block dynamically fuses features from various resolution points across the encoding and decoding layers. To mitigate the increase in network parameters and training time resulting from the complexity of the aforementioned blocks, we propose a novel shared position encoding strategy. This strategy allows various transformer blocks to share the same position information over the same resolution points, thereby reducing network parameters and training time without compromising accuracy.Experimental comparisons with existing methods on multiple datasets demonstrate the efficacy of SMTransformer and skip-attention-based up-sampling for point cloud processing tasks, including semantic segmentation and classification. In particular, we achieve state-of-the-art semantic segmentation results of 73.4% mIoU on S3DIS Area 5 and 62.4% mIoU on SWAN dataset
Accurate and Efficient Urban Street Tree Inventory with Deep Learning on Mobile Phone Imagery
Jan 02, 2024



Deforestation, a major contributor to climate change, poses detrimental consequences such as agricultural sector disruption, global warming, flash floods, and landslides. Conventional approaches to urban street tree inventory suffer from inaccuracies and necessitate specialised equipment. To overcome these challenges, this paper proposes an innovative method that leverages deep learning techniques and mobile phone imaging for urban street tree inventory. Our approach utilises a pair of images captured by smartphone cameras to accurately segment tree trunks and compute the diameter at breast height (DBH). Compared to traditional methods, our approach exhibits several advantages, including superior accuracy, reduced dependency on specialised equipment, and applicability in hard-to-reach areas. We evaluated our method on a comprehensive dataset of 400 trees and achieved a DBH estimation accuracy with an error rate of less than 2.5%. Our method holds significant potential for substantially improving forest management practices. By enhancing the accuracy and efficiency of tree inventory, our model empowers urban management to mitigate the adverse effects of deforestation and climate change.
Efficient quantum image representation and compression circuit using zero-discarded state preparation approach
Jun 22, 2023



Quantum image computing draws a lot of attention due to storing and processing image data faster than classical. With increasing the image size, the number of connections also increases, leading to the circuit complex. Therefore, efficient quantum image representation and compression issues are still challenging. The encoding of images for representation and compression in quantum systems is different from classical ones. In quantum, encoding of position is more concerned which is the major difference from the classical. In this paper, a novel zero-discarded state connection novel enhance quantum representation (ZSCNEQR) approach is introduced to reduce complexity further by discarding '0' in the location representation information. In the control operational gate, only input '1' contribute to its output thus, discarding zero makes the proposed ZSCNEQR circuit more efficient. The proposed ZSCNEQR approach significantly reduced the required bit for both representation and compression. The proposed method requires 11.76\% less qubits compared to the recent existing method. The results show that the proposed approach is highly effective for representing and compressing images compared to the two relevant existing methods in terms of rate-distortion performance.
A Network Theory Investigation into the Altered Resting State Functional Connectivity in Attention-Deficit Hyperactivity Disorder
Nov 23, 2022
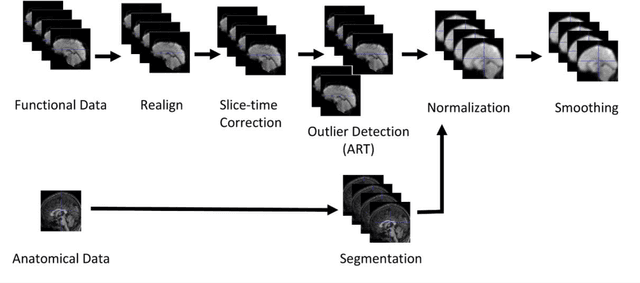
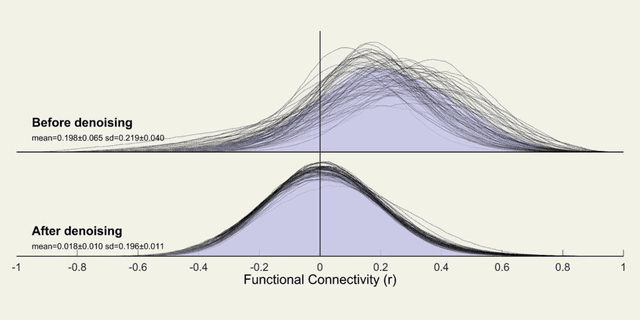

In the last two decades, functional magnetic resonance imaging (fMRI) has emerged as one of the most effective technologies in clinical research of the human brain. fMRI allows researchers to study healthy and pathological brains while they perform various neuropsychological functions. Beyond task-related activations, the human brain has some intrinsic activity at a task-negative (resting) state that surprisingly consumes a lot of energy to support communication among neurons. Recent neuroimaging research has also seen an increase in modeling and analyzing brain activity in terms of a graph or network. Since graph models facilitate a systems-theoretic explanation of the brain, they have become increasingly relevant with advances in network science and the popularization of complex systems theory. The purpose of this study is to look into the abnormalities in resting brain functions in adults with Attention Deficit Hyperactivity Disorder (ADHD). The primary goal is to investigate resting-state functional connectivity (FC), which can be construed as a significant temporal coincidence in blood-oxygen-level dependent (BOLD) signals between functionally related brain regions in the absence of any stimulus or task. When compared to healthy controls, ADHD patients have lower average connectivity in the Supramarginal Gyrus and Superior Parietal Lobule, but higher connectivity in the Lateral Occipital Cortex and Inferior Temporal Gyrus. We also hypothesize that the network organization of default mode and dorsal attention regions is abnormal in ADHD patients.
Adversarial Domain Adaptation for Action Recognition Around the Clock
Oct 25, 2022



Due to the numerous potential applications in visual surveillance and nighttime driving, recognizing human action in low-light conditions remains a difficult problem in computer vision. Existing methods separate action recognition and dark enhancement into two distinct steps to accomplish this task. However, isolating the recognition and enhancement impedes end-to-end learning of the space-time representation for video action classification. This paper presents a domain adaptation-based action recognition approach that uses adversarial learning in cross-domain settings to learn cross-domain action recognition. Supervised learning can train it on a large amount of labeled data from the source domain (daytime action sequences). However, it uses deep domain invariant features to perform unsupervised learning on many unlabelled data from the target domain (night-time action sequences). The resulting augmented model, named 3D-DiNet can be trained using standard backpropagation with an additional layer. It achieves SOTA performance on InFAR and XD145 actions datasets.
Vision Transformers for Action Recognition: A Survey
Sep 13, 2022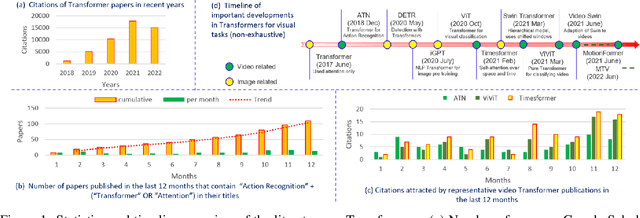
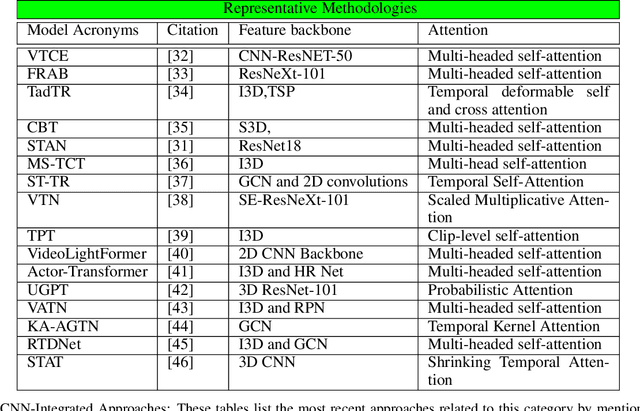
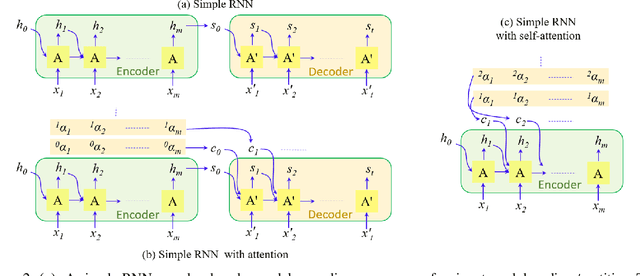
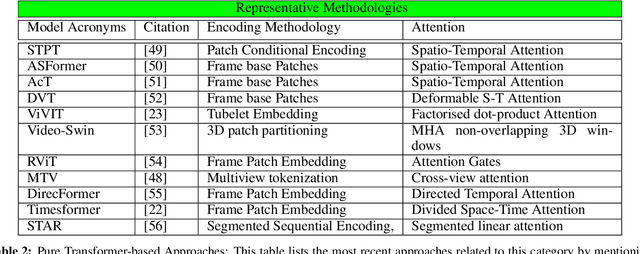
Vision transformers are emerging as a powerful tool to solve computer vision problems. Recent techniques have also proven the efficacy of transformers beyond the image domain to solve numerous video-related tasks. Among those, human action recognition is receiving special attention from the research community due to its widespread applications. This article provides the first comprehensive survey of vision transformer techniques for action recognition. We analyze and summarize the existing and emerging literature in this direction while highlighting the popular trends in adapting transformers for action recognition. Due to their specialized application, we collectively refer to these methods as ``action transformers''. Our literature review provides suitable taxonomies for action transformers based on their architecture, modality, and intended objective. Within the context of action transformers, we explore the techniques to encode spatio-temporal data, dimensionality reduction, frame patch and spatio-temporal cube construction, and various representation methods. We also investigate the optimization of spatio-temporal attention in transformer layers to handle longer sequences, typically by reducing the number of tokens in a single attention operation. Moreover, we also investigate different network learning strategies, such as self-supervised and zero-shot learning, along with their associated losses for transformer-based action recognition. This survey also summarizes the progress towards gaining grounds on evaluation metric scores on important benchmarks with action transformers. Finally, it provides a discussion on the challenges, outlook, and future avenues for this research direction.
Advance quantum image representation and compression using DCTEFRQI approach
Aug 30, 2022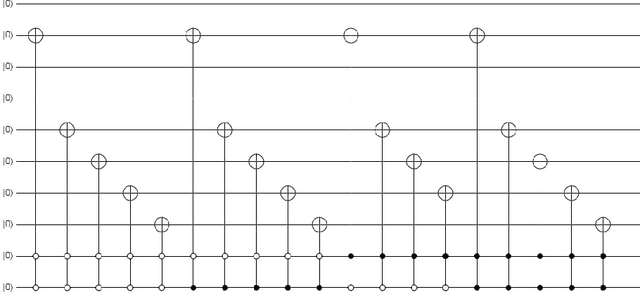
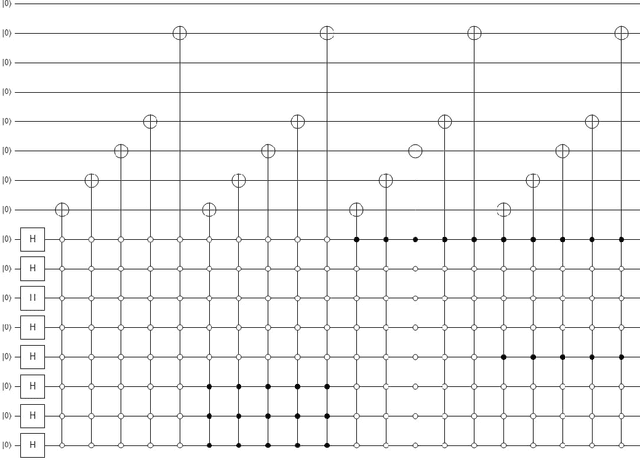
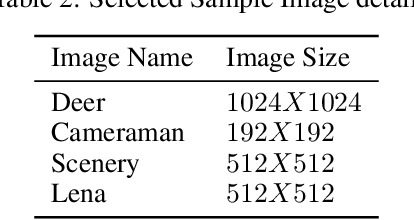
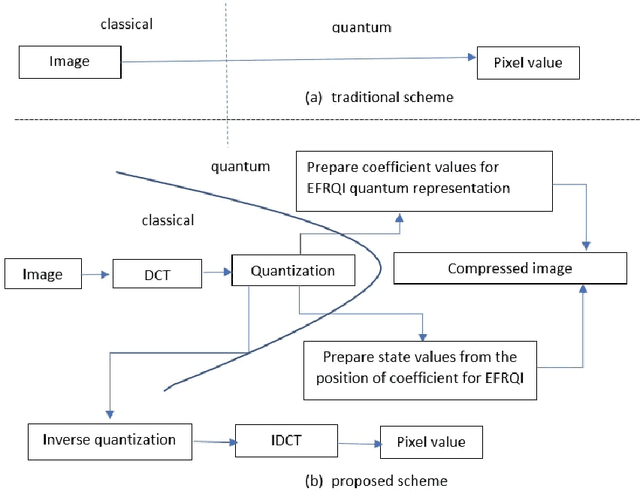
In recent year, quantum image processing got a lot of attention in the field of image processing due to opportunity to place huge image data in quantum Hilbert space. Hilbert space or Euclidean space has infinite dimension to locate and process the image data faster. Moreover, several researches show that, the computational time of quantum process is faster than classical computer. By encoding and compressing the image in quantum domain is still challenging issue. From literature survey, we have proposed a DCTEFRQI (Direct Cosine Transform Efficient Flexible Representation of Quantum Image) algorithm to represent and compress gray image efficiently which save computational time and minimize the complexity of preparation. The objective of this work is to represent and compress various gray image size in quantum computer using DCT(Discrete Cosine Transform) and EFRQI (Efficient Flexible Representation of Quantum Image) approach together. Quirk simulation tool is used to design corresponding quantum image circuit. Due to limitation of qubit, total 16 numbers of qubit are used to represent the gray scale image among those 8 are used to map the coefficient values and the rest 8 are used to generate the corresponding coefficient position. Theoretical analysis and experimental result show that, proposed DCTEFRQI scheme provides better representation and compression compare to DCT-GQIR, DWT-GQIR and DWT-EFRQI in terms of PSNR(Peak Signal to Noise Ratio) and bit rate..