 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMI-DPG: Decomposable Parameter Generation Network Based on Mutual Information for Multi-Scenario Recommendation
Mar 22, 2026Conversion rate (CVR) prediction models play a vital role in recommendation and advertising systems. Recent research on multi-scenario recommendation shows that learning a unified model to serve multiple scenarios is effective for improving overall performance. However, it remains challenging to improve model prediction performance across scenarios at low model parameter cost, and current solutions are hard to robustly model multi-scenario diversity. In this paper, we propose MI-DPG for the multi-scenario CVR prediction, which learns scenario-conditioned dynamic model parameters for each scenario in a more efficient and effective manner. Specifically, we introduce an auxiliary network to generate scenario-conditioned dynamic weighting matrices, which are obtained by combining decomposed scenario-specific and scenario-shared low-rank matrices with parameter efficiency. For each scene, weighting the backbone model parameters by the weighting matrix helps to specialize the model parameters for different scenarios. It can not only modulate the complete parameter space of the backbone model but also improve the model effectiveness. Furthermore, we design a mutual information regularization to enhance the diversity of model parameters across different scenarios by maximizing the mutual information between the scenario-aware input and the scene-conditioned dynamic weighting matrix. Experiments from three real-world datasets show that MI-DPG significantly outperforms previous multi-scenario recommendation models.
* Accepted by CIKM 2023
Trie-Aware Transformers for Generative Recommendation
Feb 25, 2026Generative recommendation (GR) aligns with advances in generative AI by casting next-item prediction as token-level generation rather than score-based ranking. Most GR methods adopt a two-stage pipeline: (i) \textit{item tokenization}, which maps each item to a sequence of discrete, hierarchically organized tokens; and (ii) \textit{autoregressive generation}, which predicts the next item's tokens conditioned on the tokens of user's interaction history. Although hierarchical tokenization induces a prefix tree (trie) over items, standard autoregressive modeling with conventional Transformers often flattens item tokens into a linear stream and overlooks the underlying topology. To address this, we propose TrieRec, a trie-aware generative recommendation method that augments Transformers with structural inductive biases via two positional encodings. First, a \textit{trie-aware absolute positional encoding} aggregates a token's (node's) local structural context (\eg depth, ancestors, and descendants) into the token representation. Second, a \textit{topology-aware relative positional encoding} injects pairwise structural relations into self-attention to capture topology-induced semantic relatedness. TrieRec is also model-agnostic, efficient, and hyperparameter-free. In our experiments, we implement TrieRec within three representative GR backbones, achieving notably improvements of 8.83\% on average across four real-world datasets.
Abstraction Generation for Generalized Planning with Pretrained Large Language Models
Feb 11, 2026Qualitative Numerical Planning (QNP) serves as an important abstraction model for generalized planning (GP), which aims to compute general plans that solve multiple instances at once. Recent works show that large language models (LLMs) can function as generalized planners. This work investigates whether LLMs can serve as QNP abstraction generators for GP problems and how to fix abstractions via automated debugging. We propose a prompt protocol: input a GP domain and training tasks to LLMs, prompting them to generate abstract features and further abstract the initial state, action set, and goal into QNP problems. An automated debugging method is designed to detect abstraction errors, guiding LLMs to fix abstractions. Experiments demonstrate that under properly guided by automated debugging, some LLMs can generate useful QNP abstractions.
Open-Source Multimodal Moxin Models with Moxin-VLM and Moxin-VLA
Dec 22, 2025Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Moxin 7B is introduced as a fully open-source LLM developed in accordance with the Model Openness Framework, which moves beyond the simple sharing of model weights to embrace complete transparency in training, datasets, and implementation detail, thus fostering a more inclusive and collaborative research environment that can sustain a healthy open-source ecosystem. To further equip Moxin with various capabilities in different tasks, we develop three variants based on Moxin, including Moxin-VLM, Moxin-VLA, and Moxin-Chinese, which target the vision-language, vision-language-action, and Chinese capabilities, respectively. Experiments show that our models achieve superior performance in various evaluations. We adopt open-source framework and open data for the training. We release our models, along with the available data and code to derive these models.
AgriGPT: a Large Language Model Ecosystem for Agriculture
Aug 12, 2025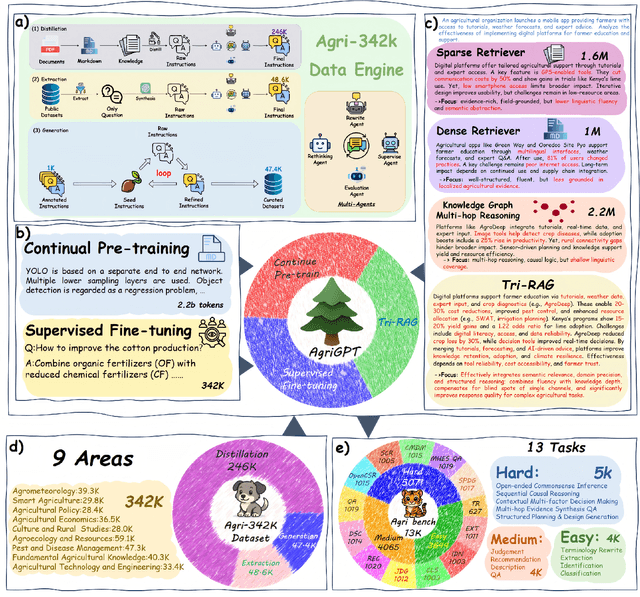
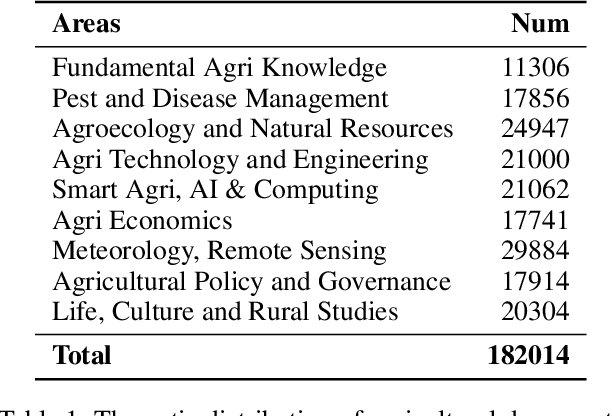
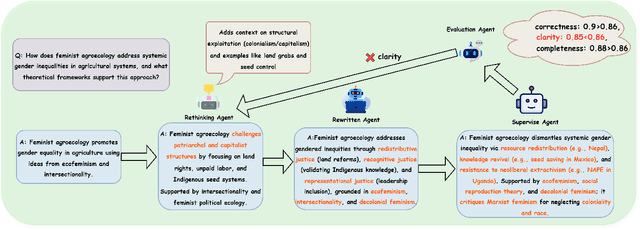
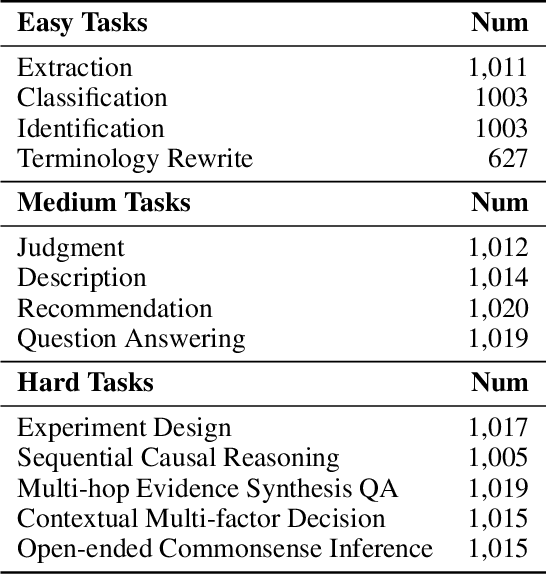
Despite the rapid progress of Large Language Models (LLMs), their application in agriculture remains limited due to the lack of domain-specific models, curated datasets, and robust evaluation frameworks. To address these challenges, we propose AgriGPT, a domain-specialized LLM ecosystem for agricultural usage. At its core, we design a multi-agent scalable data engine that systematically compiles credible data sources into Agri-342K, a high-quality, standardized question-answer (QA) dataset. Trained on this dataset, AgriGPT supports a broad range of agricultural stakeholders, from practitioners to policy-makers. To enhance factual grounding, we employ Tri-RAG, a three-channel Retrieval-Augmented Generation framework combining dense retrieval, sparse retrieval, and multi-hop knowledge graph reasoning, thereby improving the LLM's reasoning reliability. For comprehensive evaluation, we introduce AgriBench-13K, a benchmark suite comprising 13 tasks with varying types and complexities. Experiments demonstrate that AgriGPT significantly outperforms general-purpose LLMs on both domain adaptation and reasoning. Beyond the model itself, AgriGPT represents a modular and extensible LLM ecosystem for agriculture, comprising structured data construction, retrieval-enhanced generation, and domain-specific evaluation. This work provides a generalizable framework for developing scientific and industry-specialized LLMs. All models, datasets, and code will be released to empower agricultural communities, especially in underserved regions, and to promote open, impactful research.
Depth as Points: Center Point-based Depth Estimation
Apr 26, 2025The perception of vehicles and pedestrians in urban scenarios is crucial for autonomous driving. This process typically involves complicated data collection, imposes high computational and hardware demands. To address these limitations, we first develop a highly efficient method for generating virtual datasets, which enables the creation of task- and scenario-specific datasets in a short time. Leveraging this method, we construct the virtual depth estimation dataset VirDepth, a large-scale, multi-task autonomous driving dataset. Subsequently, we propose CenterDepth, a lightweight architecture for monocular depth estimation that ensures high operational efficiency and exhibits superior performance in depth estimation tasks with highly imbalanced height-scale distributions. CenterDepth integrates global semantic information through the innovative Center FC-CRFs algorithm, aggregates multi-scale features based on object key points, and enables detection-based depth estimation of targets. Experiments demonstrate that our proposed method achieves superior performance in terms of both computational speed and prediction accuracy.
PointDiffuse: A Dual-Conditional Diffusion Model for Enhanced Point Cloud Semantic Segmentation
Mar 11, 2025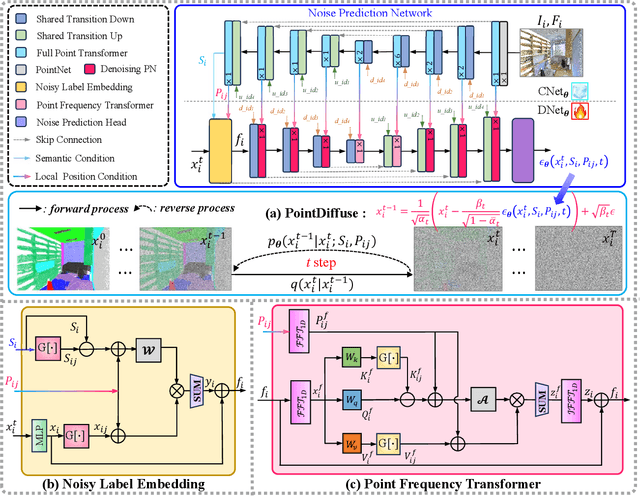



Diffusion probabilistic models are traditionally used to generate colors at fixed pixel positions in 2D images. Building on this, we extend diffusion models to point cloud semantic segmentation, where point positions also remain fixed, and the diffusion model generates point labels instead of colors. To accelerate the denoising process in reverse diffusion, we introduce a noisy label embedding mechanism. This approach integrates semantic information into the noisy label, providing an initial semantic reference that improves the reverse diffusion efficiency. Additionally, we propose a point frequency transformer that enhances the adjustment of high-level context in point clouds. To reduce computational complexity, we introduce the position condition into MLP and propose denoising PointNet to process the high-resolution point cloud without sacrificing geometric details. Finally, we integrate the proposed noisy label embedding, point frequency transformer and denoising PointNet in our proposed dual conditional diffusion model-based network (PointDiffuse) to perform large-scale point cloud semantic segmentation. Extensive experiments on five benchmarks demonstrate the superiority of PointDiffuse, achieving the state-of-the-art mIoU of 74.2\% on S3DIS Area 5, 81.2\% on S3DIS 6-fold and 64.8\% on SWAN dataset.
TReND: Transformer derived features and Regularized NMF for neonatal functional network Delineation
Mar 04, 2025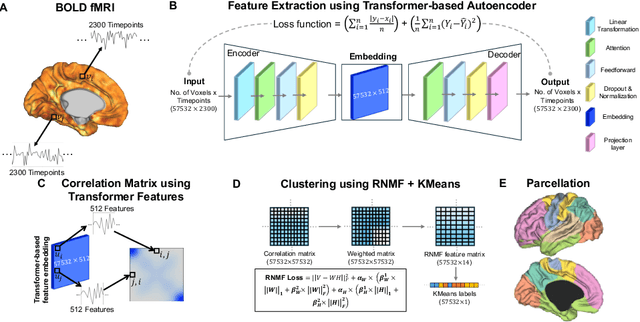
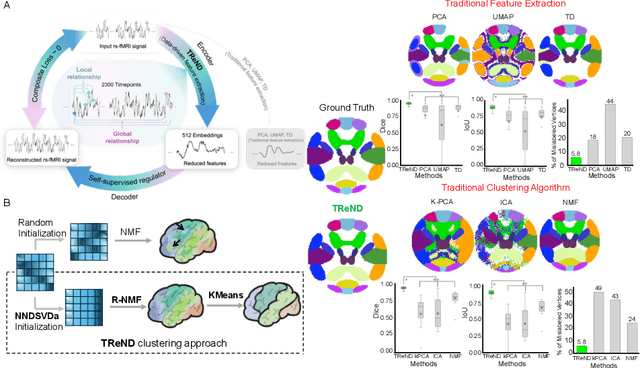
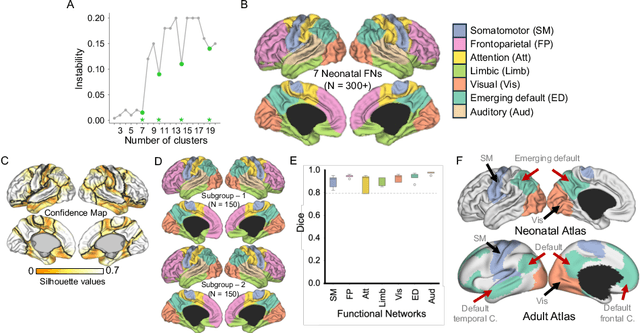
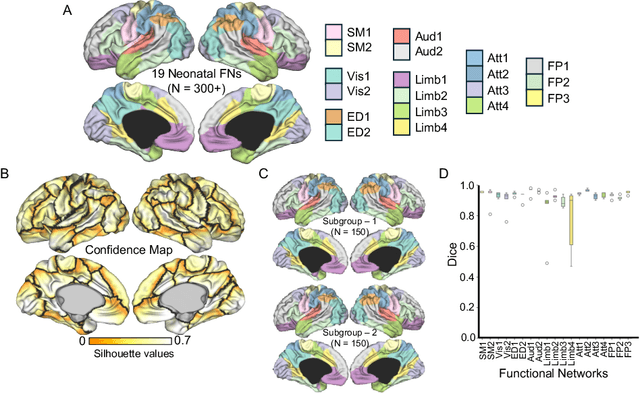
Precise parcellation of functional networks (FNs) of early developing human brain is the fundamental basis for identifying biomarker of developmental disorders and understanding functional development. Resting-state fMRI (rs-fMRI) enables in vivo exploration of functional changes, but adult FN parcellations cannot be directly applied to the neonates due to incomplete network maturation. No standardized neonatal functional atlas is currently available. To solve this fundamental issue, we propose TReND, a novel and fully automated self-supervised transformer-autoencoder framework that integrates regularized nonnegative matrix factorization (RNMF) to unveil the FNs in neonates. TReND effectively disentangles spatiotemporal features in voxel-wise rs-fMRI data. The framework integrates confidence-adaptive masks into transformer self-attention layers to mitigate noise influence. A self supervised decoder acts as a regulator to refine the encoder's latent embeddings, which serve as reliable temporal features. For spatial coherence, we incorporate brain surface-based geodesic distances as spatial encodings along with functional connectivity from temporal features. The TReND clustering approach processes these features under sparsity and smoothness constraints, producing robust and biologically plausible parcellations. We extensively validated our TReND framework on three different rs-fMRI datasets: simulated, dHCP and HCP-YA against comparable traditional feature extraction and clustering techniques. Our results demonstrated the superiority of the TReND framework in the delineation of neonate FNs with significantly better spatial contiguity and functional homogeneity. Collectively, we established TReND, a novel and robust framework, for neonatal FN delineation. TReND-derived neonatal FNs could serve as a neonatal functional atlas for perinatal populations in health and disease.
Integrating remote sensing data assimilation, deep learning and large language model for interactive wheat breeding yield prediction
Jan 08, 2025



Yield is one of the core goals of crop breeding. By predicting the potential yield of different breeding materials, breeders can screen these materials at various growth stages to select the best performing. Based on unmanned aerial vehicle remote sensing technology, high-throughput crop phenotyping data in breeding areas is collected to provide data support for the breeding decisions of breeders. However, the accuracy of current yield predictions still requires improvement, and the usability and user-friendliness of yield forecasting tools remain suboptimal. To address these challenges, this study introduces a hybrid method and tool for crop yield prediction, designed to allow breeders to interactively and accurately predict wheat yield by chatting with a large language model (LLM). First, the newly designed data assimilation algorithm is used to assimilate the leaf area index into the WOFOST model. Then, selected outputs from the assimilation process, along with remote sensing inversion results, are used to drive the time-series temporal fusion transformer model for wheat yield prediction. Finally, based on this hybrid method and leveraging an LLM with retrieval augmented generation technology, we developed an interactive yield prediction Web tool that is user-friendly and supports sustainable data updates. This tool integrates multi-source data to assist breeding decision-making. This study aims to accelerate the identification of high-yield materials in the breeding process, enhance breeding efficiency, and enable more scientific and smart breeding decisions.
Representational Transfer Learning for Matrix Completion
Dec 09, 2024

We propose to transfer representational knowledge from multiple sources to a target noisy matrix completion task by aggregating singular subspaces information. Under our representational similarity framework, we first integrate linear representation information by solving a two-way principal component analysis problem based on a properly debiased matrix-valued dataset. After acquiring better column and row representation estimators from the sources, the original high-dimensional target matrix completion problem is then transformed into a low-dimensional linear regression, of which the statistical efficiency is guaranteed. A variety of extensional arguments, including post-transfer statistical inference and robustness against negative transfer, are also discussed alongside. Finally, extensive simulation results and a number of real data cases are reported to support our claims.