 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Length Barrier: LLM-Enhanced CTR Prediction in Long Textual User Behaviors
Mar 28, 2024With the rise of large language models (LLMs), recent works have leveraged LLMs to improve the performance of click-through rate (CTR) prediction. However, we argue that a critical obstacle remains in deploying LLMs for practical use: the efficiency of LLMs when processing long textual user behaviors. As user sequences grow longer, the current efficiency of LLMs is inadequate for training on billions of users and items. To break through the efficiency barrier of LLMs, we propose Behavior Aggregated Hierarchical Encoding (BAHE) to enhance the efficiency of LLM-based CTR modeling. Specifically, BAHE proposes a novel hierarchical architecture that decouples the encoding of user behaviors from inter-behavior interactions. Firstly, to prevent computational redundancy from repeated encoding of identical user behaviors, BAHE employs the LLM's pre-trained shallow layers to extract embeddings of the most granular, atomic user behaviors from extensive user sequences and stores them in the offline database. Subsequently, the deeper, trainable layers of the LLM facilitate intricate inter-behavior interactions, thereby generating comprehensive user embeddings. This separation allows the learning of high-level user representations to be independent of low-level behavior encoding, significantly reducing computational complexity. Finally, these refined user embeddings, in conjunction with correspondingly processed item embeddings, are incorporated into the CTR model to compute the CTR scores. Extensive experimental results show that BAHE reduces training time and memory by five times for CTR models using LLMs, especially with longer user sequences. BAHE has been deployed in a real-world system, allowing for daily updates of 50 million CTR data on 8 A100 GPUs, making LLMs practical for industrial CTR prediction.
Continual Learning for Task-oriented Dialogue System with Iterative Network Pruning, Expanding and Masking
Jul 17, 2021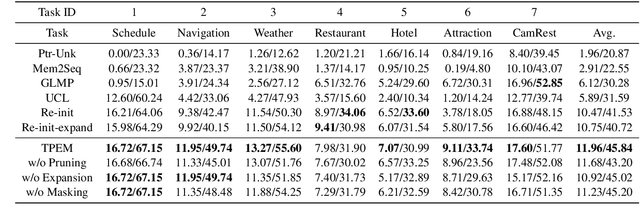
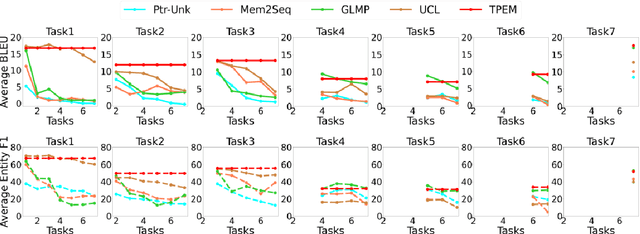
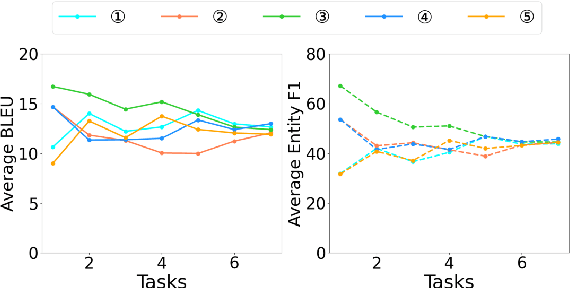
This ability to learn consecutive tasks without forgetting how to perform previously trained problems is essential for developing an online dialogue system. This paper proposes an effective continual learning for the task-oriented dialogue system with iterative network pruning, expanding and masking (TPEM), which preserves performance on previously encountered tasks while accelerating learning progress on subsequent tasks. Specifically, TPEM (i) leverages network pruning to keep the knowledge for old tasks, (ii) adopts network expanding to create free weights for new tasks, and (iii) introduces task-specific network masking to alleviate the negative impact of fixed weights of old tasks on new tasks. We conduct extensive experiments on seven different tasks from three benchmark datasets and show empirically that TPEM leads to significantly improved results over the strong competitors. For reproducibility, we submit the code and data at: https://github.com/siat-nlp/TPEM
Iterative Network Pruning with Uncertainty Regularization for Lifelong Sentiment Classification
Jun 21, 2021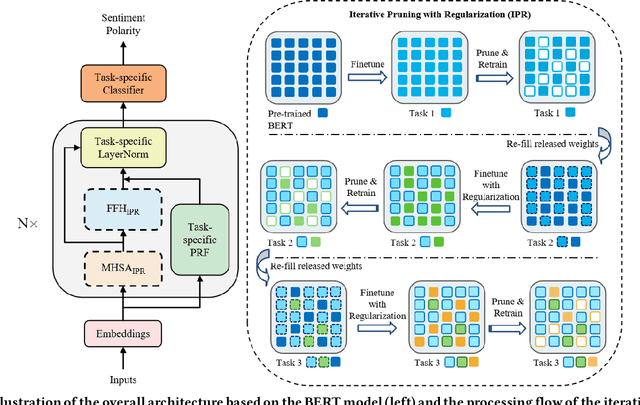
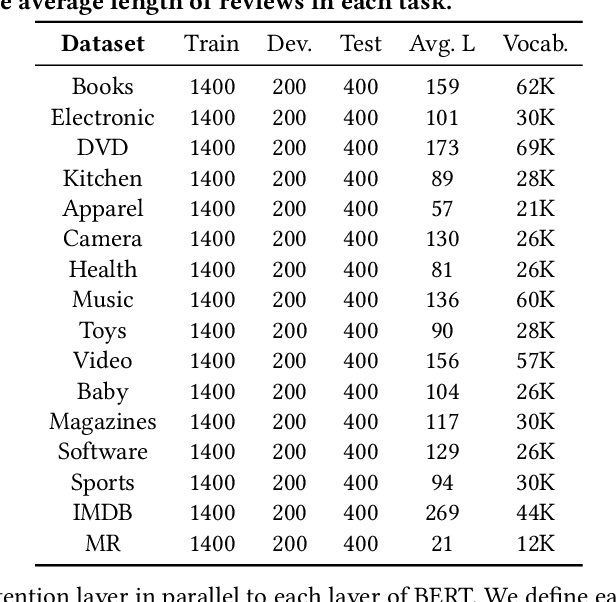
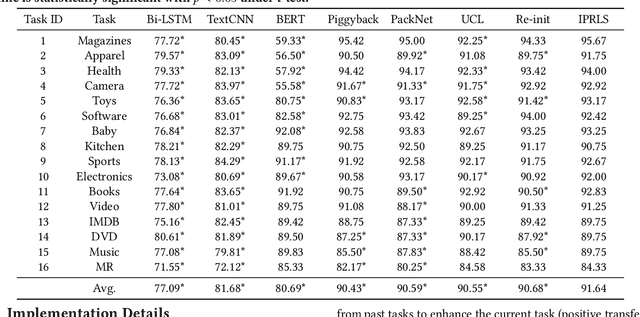
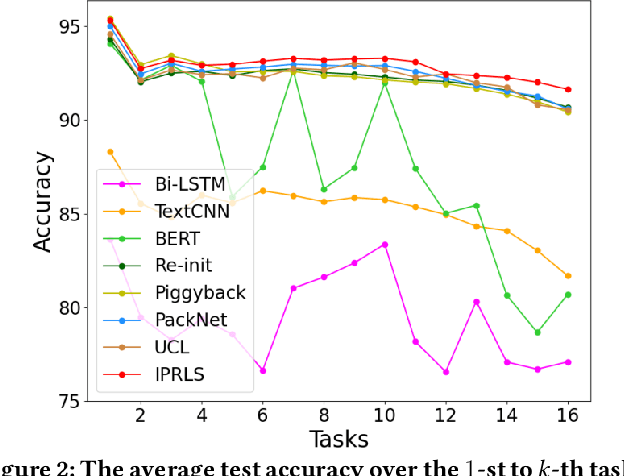
Lifelong learning capabilities are crucial for sentiment classifiers to process continuous streams of opinioned information on the Web. However, performing lifelong learning is non-trivial for deep neural networks as continually training of incrementally available information inevitably results in catastrophic forgetting or interference. In this paper, we propose a novel iterative network pruning with uncertainty regularization method for lifelong sentiment classification (IPRLS), which leverages the principles of network pruning and weight regularization. By performing network pruning with uncertainty regularization in an iterative manner, IPRLS can adapta single BERT model to work with continuously arriving data from multiple domains while avoiding catastrophic forgetting and interference. Specifically, we leverage an iterative pruning method to remove redundant parameters in large deep networks so that the freed-up space can then be employed to learn new tasks, tackling the catastrophic forgetting problem. Instead of keeping the old-tasks fixed when learning new tasks, we also use an uncertainty regularization based on the Bayesian online learning framework to constrain the update of old tasks weights in BERT, which enables positive backward transfer, i.e. learning new tasks improves performance on past tasks while protecting old knowledge from being lost. In addition, we propose a task-specific low-dimensional residual function in parallel to each layer of BERT, which makes IPRLS less prone to losing the knowledge saved in the base BERT network when learning a new task. Extensive experiments on 16 popular review corpora demonstrate that the proposed IPRLS method sig-nificantly outperforms the strong baselines for lifelong sentiment classification. For reproducibility, we submit the code and data at:https://github.com/siat-nlp/IPRLS.