 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Path Prompting in LLMs: Analyzing Reasoning Instability and Solutions for Robust Performance
Apr 13, 2025Recent years have witnessed significant progress in large language models' (LLMs) reasoning, which is largely due to the chain-of-thought (CoT) approaches, allowing models to generate intermediate reasoning steps before reaching the final answer. Building on these advances, state-of-the-art LLMs are instruction-tuned to provide long and detailed CoT pathways when responding to reasoning-related questions. However, human beings are naturally cognitive misers and will prompt language models to give rather short responses, thus raising a significant conflict with CoT reasoning. In this paper, we delve into how LLMs' reasoning performance changes when users provide short-path prompts. The results and analysis reveal that language models can reason effectively and robustly without explicit CoT prompts, while under short-path prompting, LLMs' reasoning ability drops significantly and becomes unstable, even on grade-school problems. To address this issue, we propose two approaches: an instruction-guided approach and a fine-tuning approach, both designed to effectively manage the conflict. Experimental results show that both methods achieve high accuracy, providing insights into the trade-off between instruction adherence and reasoning accuracy in current models.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
AntDT: A Self-Adaptive Distributed Training Framework for Leader and Straggler Nodes
Apr 15, 2024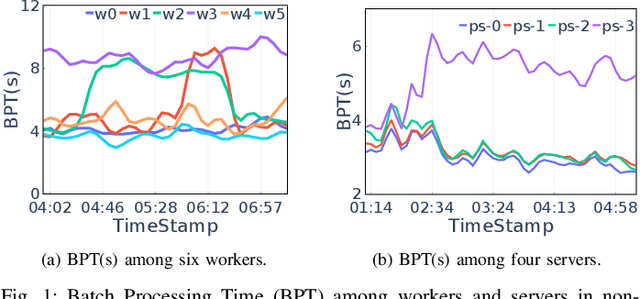
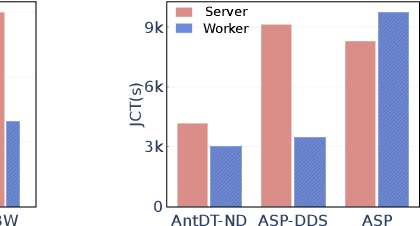
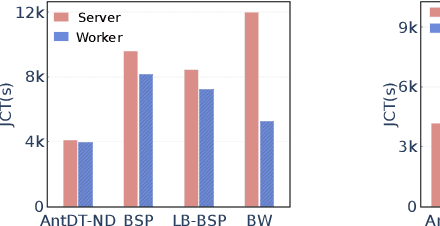
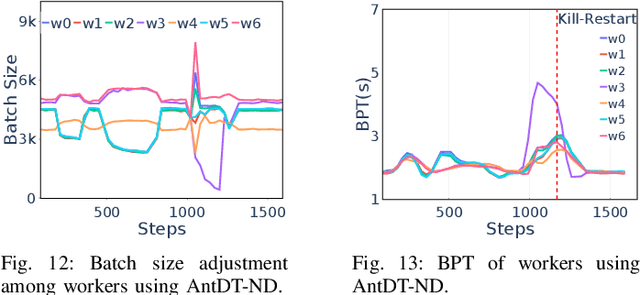
Many distributed training techniques like Parameter Server and AllReduce have been proposed to take advantage of the increasingly large data and rich features. However, stragglers frequently occur in distributed training due to resource contention and hardware heterogeneity, which significantly hampers the training efficiency. Previous works only address part of the stragglers and could not adaptively solve various stragglers in practice. Additionally, it is challenging to use a systematic framework to address all stragglers because different stragglers require diverse data allocation and fault-tolerance mechanisms. Therefore, this paper proposes a unified distributed training framework called AntDT (Ant Distributed Training Framework) to adaptively solve the straggler problems. Firstly, the framework consists of four components, including the Stateful Dynamic Data Sharding service, Monitor, Controller, and Agent. These components work collaboratively to efficiently distribute workloads and provide a range of pre-defined straggler mitigation methods with fault tolerance, thereby hiding messy details of data allocation and fault handling. Secondly, the framework provides a high degree of flexibility, allowing for the customization of straggler mitigation solutions based on the specific circumstances of the cluster. Leveraging this flexibility, we introduce two straggler mitigation solutions, namely AntDT-ND for non-dedicated clusters and AntDT-DD for dedicated clusters, as practical examples to resolve various types of stragglers at Ant Group. Justified by our comprehensive experiments and industrial deployment statistics, AntDT outperforms other SOTA methods more than 3x in terms of training efficiency. Additionally, in Alipay's homepage recommendation scenario, using AntDT reduces the training duration of the ranking model from 27.8 hours to just 5.4 hours.
Breaking the Length Barrier: LLM-Enhanced CTR Prediction in Long Textual User Behaviors
Mar 28, 2024With the rise of large language models (LLMs), recent works have leveraged LLMs to improve the performance of click-through rate (CTR) prediction. However, we argue that a critical obstacle remains in deploying LLMs for practical use: the efficiency of LLMs when processing long textual user behaviors. As user sequences grow longer, the current efficiency of LLMs is inadequate for training on billions of users and items. To break through the efficiency barrier of LLMs, we propose Behavior Aggregated Hierarchical Encoding (BAHE) to enhance the efficiency of LLM-based CTR modeling. Specifically, BAHE proposes a novel hierarchical architecture that decouples the encoding of user behaviors from inter-behavior interactions. Firstly, to prevent computational redundancy from repeated encoding of identical user behaviors, BAHE employs the LLM's pre-trained shallow layers to extract embeddings of the most granular, atomic user behaviors from extensive user sequences and stores them in the offline database. Subsequently, the deeper, trainable layers of the LLM facilitate intricate inter-behavior interactions, thereby generating comprehensive user embeddings. This separation allows the learning of high-level user representations to be independent of low-level behavior encoding, significantly reducing computational complexity. Finally, these refined user embeddings, in conjunction with correspondingly processed item embeddings, are incorporated into the CTR model to compute the CTR scores. Extensive experimental results show that BAHE reduces training time and memory by five times for CTR models using LLMs, especially with longer user sequences. BAHE has been deployed in a real-world system, allowing for daily updates of 50 million CTR data on 8 A100 GPUs, making LLMs practical for industrial CTR prediction.
G-Meta: Distributed Meta Learning in GPU Clusters for Large-Scale Recommender Systems
Jan 09, 2024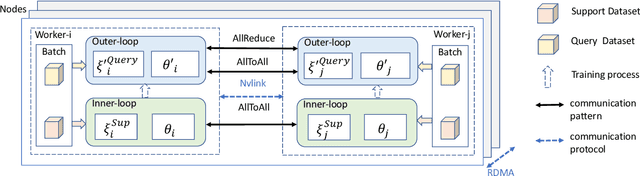
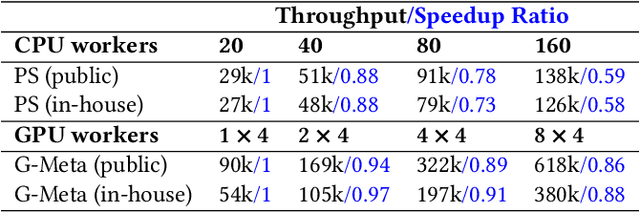
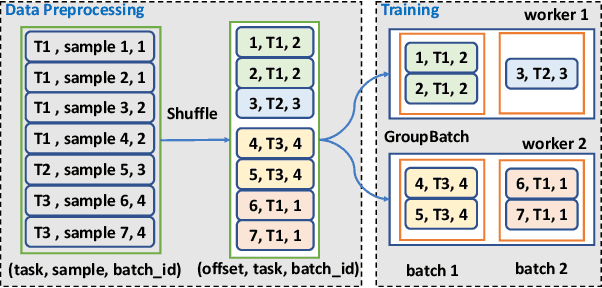
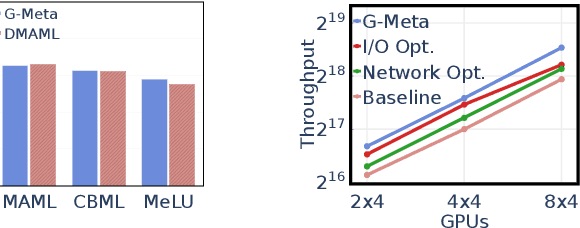
Recently, a new paradigm, meta learning, has been widely applied to Deep Learning Recommendation Models (DLRM) and significantly improves statistical performance, especially in cold-start scenarios. However, the existing systems are not tailored for meta learning based DLRM models and have critical problems regarding efficiency in distributed training in the GPU cluster. It is because the conventional deep learning pipeline is not optimized for two task-specific datasets and two update loops in meta learning. This paper provides a high-performance framework for large-scale training for Optimization-based Meta DLRM models over the \textbf{G}PU cluster, namely \textbf{G}-Meta. Firstly, G-Meta utilizes both data parallelism and model parallelism with careful orchestration regarding computation and communication efficiency, to enable high-speed distributed training. Secondly, it proposes a Meta-IO pipeline for efficient data ingestion to alleviate the I/O bottleneck. Various experimental results show that G-Meta achieves notable training speed without loss of statistical performance. Since early 2022, G-Meta has been deployed in Alipay's core advertising and recommender system, shrinking the continuous delivery of models by four times. It also obtains 6.48\% improvement in Conversion Rate (CVR) and 1.06\% increase in CPM (Cost Per Mille) in Alipay's homepage display advertising, with the benefit of larger training samples and tasks.
One Model for All: Large Language Models are Domain-Agnostic Recommendation Systems
Oct 22, 2023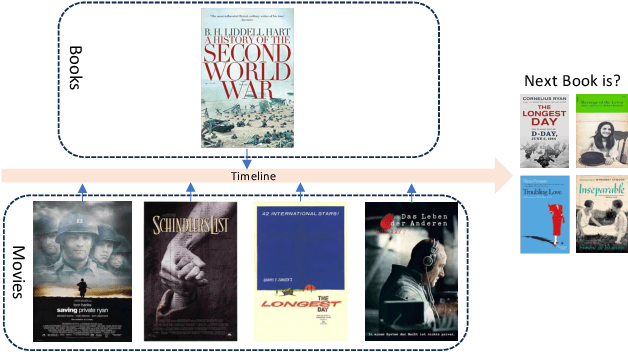

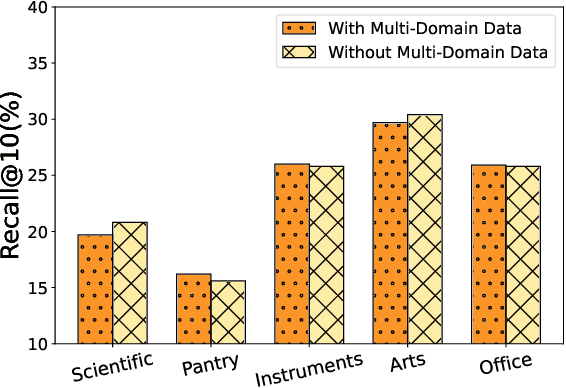

The purpose of sequential recommendation is to utilize the interaction history of a user and predict the next item that the user is most likely to interact with. While data sparsity and cold start are two challenges that most recommender systems are still facing, many efforts are devoted to utilizing data from other domains, called cross-domain methods. However, general cross-domain methods explore the relationship between two domains by designing complex model architecture, making it difficult to scale to multiple domains and utilize more data. Moreover, existing recommendation systems use IDs to represent item, which carry less transferable signals in cross-domain scenarios, and user cross-domain behaviors are also sparse, making it challenging to learn item relationship from different domains. These problems hinder the application of multi-domain methods to sequential recommendation. Recently, large language models (LLMs) exhibit outstanding performance in world knowledge learning from text corpora and general-purpose question answering. Inspired by these successes, we propose a simple but effective framework for domain-agnostic recommendation by exploiting the pre-trained LLMs (namely LLM-Rec). We mix the user's behavior across different domains, and then concatenate the title information of these items into a sentence and model the user's behaviors with a pre-trained language model. We expect that by mixing the user's behaviors across different domains, we can exploit the common knowledge encoded in the pre-trained language model to alleviate the problems of data sparsity and cold start problems. Furthermore, we are curious about whether the latest technical advances in nature language processing (NLP) can transfer to the recommendation scenarios.
Rethinking Memory and Communication Cost for Efficient Large Language Model Training
Oct 09, 2023
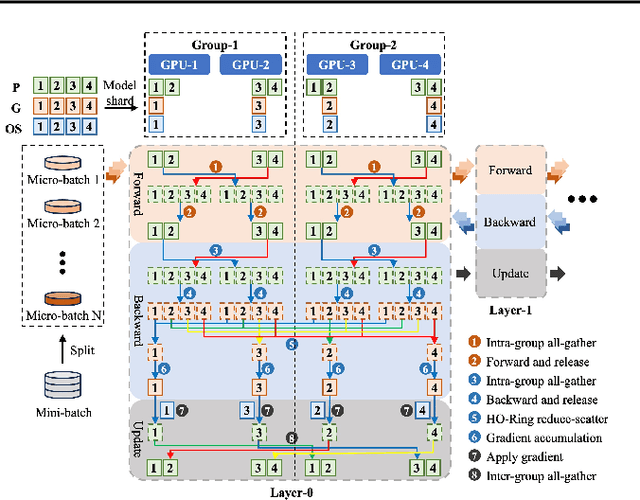
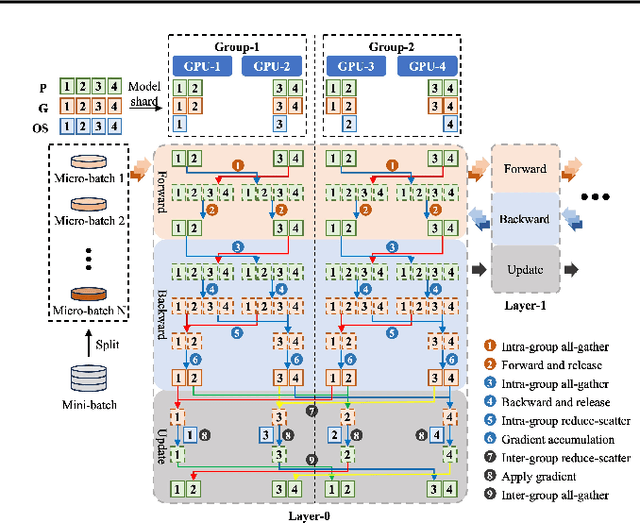
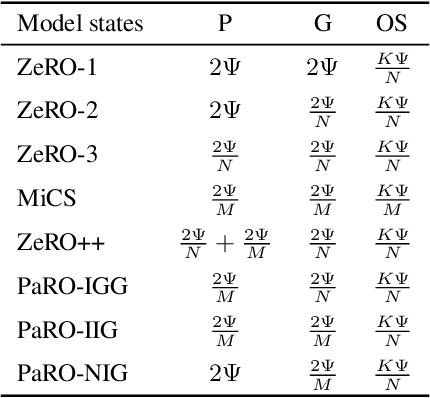
As model sizes and training datasets continue to increase, large-scale model training frameworks reduce memory consumption by various sharding techniques. However, the huge communication overhead reduces the training efficiency, especially in public cloud environments with varying network bandwidths. In this paper, we rethink the impact of memory consumption and communication overhead on the training speed of large language model, and propose a memory-communication balanced \underline{Pa}rtial \underline{R}edundancy \underline{O}ptimizer (PaRO). PaRO reduces the amount and frequency of inter-group communication by grouping GPU clusters and introducing minor intra-group memory redundancy, thereby improving the training efficiency of the model. Additionally, we propose a Hierarchical Overlapping Ring (HO-Ring) communication topology to enhance communication efficiency between nodes or across switches in large model training. Our experiments demonstrate that the HO-Ring algorithm improves communication efficiency by 32.6\% compared to the traditional Ring algorithm. Compared to the baseline ZeRO, PaRO significantly improves training throughput by 1.2x-2.6x and achieves a near-linear scalability. Therefore, the PaRO strategy provides more fine-grained options for the trade-off between memory consumption and communication overhead in different training scenarios.
AntM$^{2}$C: A Large Scale Dataset For Multi-Scenario Multi-Modal CTR Prediction
Aug 31, 2023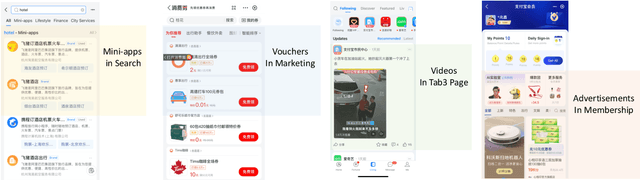

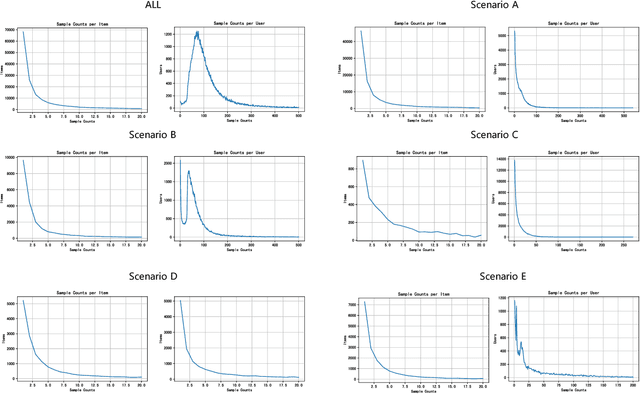

Click-through rate (CTR) prediction is a crucial issue in recommendation systems. There has been an emergence of various public CTR datasets. However, existing datasets primarily suffer from the following limitations. Firstly, users generally click different types of items from multiple scenarios, and modeling from multiple scenarios can provide a more comprehensive understanding of users. Existing datasets only include data for the same type of items from a single scenario. Secondly, multi-modal features are essential in multi-scenario prediction as they address the issue of inconsistent ID encoding between different scenarios. The existing datasets are based on ID features and lack multi-modal features. Third, a large-scale dataset can provide a more reliable evaluation of models, fully reflecting the performance differences between models. The scale of existing datasets is around 100 million, which is relatively small compared to the real-world CTR prediction. To address these limitations, we propose AntM$^{2}$C, a Multi-Scenario Multi-Modal CTR dataset based on industrial data from Alipay. Specifically, AntM$^{2}$C provides the following advantages: 1) It covers CTR data of 5 different types of items, providing insights into the preferences of users for different items, including advertisements, vouchers, mini-programs, contents, and videos. 2) Apart from ID-based features, AntM$^{2}$C also provides 2 multi-modal features, raw text and image features, which can effectively establish connections between items with different IDs. 3) AntM$^{2}$C provides 1 billion CTR data with 200 features, including 200 million users and 6 million items. It is currently the largest-scale CTR dataset available. Based on AntM$^{2}$C, we construct several typical CTR tasks and provide comparisons with baseline methods. The dataset homepage is available at https://www.atecup.cn/home.