 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Path Prompting in LLMs: Analyzing Reasoning Instability and Solutions for Robust Performance
Apr 13, 2025Recent years have witnessed significant progress in large language models' (LLMs) reasoning, which is largely due to the chain-of-thought (CoT) approaches, allowing models to generate intermediate reasoning steps before reaching the final answer. Building on these advances, state-of-the-art LLMs are instruction-tuned to provide long and detailed CoT pathways when responding to reasoning-related questions. However, human beings are naturally cognitive misers and will prompt language models to give rather short responses, thus raising a significant conflict with CoT reasoning. In this paper, we delve into how LLMs' reasoning performance changes when users provide short-path prompts. The results and analysis reveal that language models can reason effectively and robustly without explicit CoT prompts, while under short-path prompting, LLMs' reasoning ability drops significantly and becomes unstable, even on grade-school problems. To address this issue, we propose two approaches: an instruction-guided approach and a fine-tuning approach, both designed to effectively manage the conflict. Experimental results show that both methods achieve high accuracy, providing insights into the trade-off between instruction adherence and reasoning accuracy in current models.
Holistic Capability Preservation: Towards Compact Yet Comprehensive Reasoning Models
Apr 09, 2025This technical report presents Ring-Lite-Distill, a lightweight reasoning model derived from our open-source Mixture-of-Experts (MoE) Large Language Models (LLMs) Ling-Lite. This study demonstrates that through meticulous high-quality data curation and ingenious training paradigms, the compact MoE model Ling-Lite can be further trained to achieve exceptional reasoning capabilities, while maintaining its parameter-efficient architecture with only 2.75 billion activated parameters, establishing an efficient lightweight reasoning architecture. In particular, in constructing this model, we have not merely focused on enhancing advanced reasoning capabilities, exemplified by high-difficulty mathematical problem solving, but rather aimed to develop a reasoning model with more comprehensive competency coverage. Our approach ensures coverage across reasoning tasks of varying difficulty levels while preserving generic capabilities, such as instruction following, tool use, and knowledge retention. We show that, Ring-Lite-Distill's reasoning ability reaches a level comparable to DeepSeek-R1-Distill-Qwen-7B, while its general capabilities significantly surpass those of DeepSeek-R1-Distill-Qwen-7B. The models are accessible at https://huggingface.co/inclusionAI
One Model for All: Large Language Models are Domain-Agnostic Recommendation Systems
Oct 22, 2023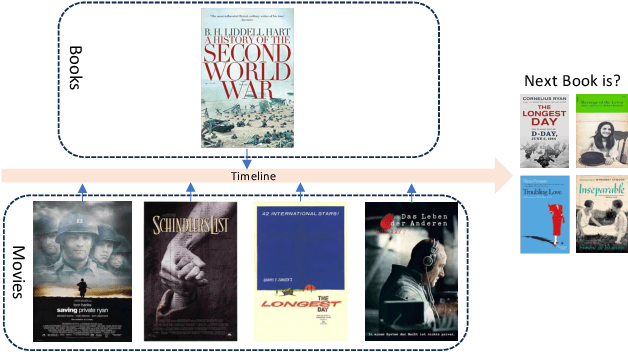

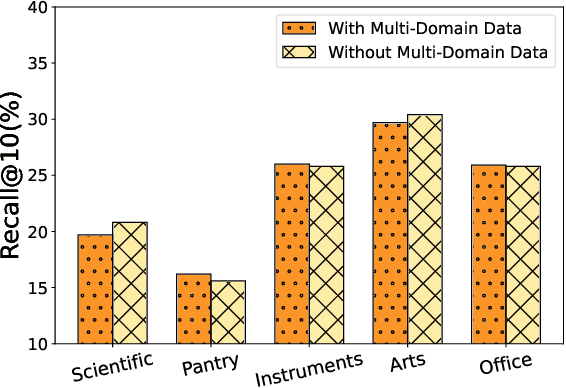

The purpose of sequential recommendation is to utilize the interaction history of a user and predict the next item that the user is most likely to interact with. While data sparsity and cold start are two challenges that most recommender systems are still facing, many efforts are devoted to utilizing data from other domains, called cross-domain methods. However, general cross-domain methods explore the relationship between two domains by designing complex model architecture, making it difficult to scale to multiple domains and utilize more data. Moreover, existing recommendation systems use IDs to represent item, which carry less transferable signals in cross-domain scenarios, and user cross-domain behaviors are also sparse, making it challenging to learn item relationship from different domains. These problems hinder the application of multi-domain methods to sequential recommendation. Recently, large language models (LLMs) exhibit outstanding performance in world knowledge learning from text corpora and general-purpose question answering. Inspired by these successes, we propose a simple but effective framework for domain-agnostic recommendation by exploiting the pre-trained LLMs (namely LLM-Rec). We mix the user's behavior across different domains, and then concatenate the title information of these items into a sentence and model the user's behaviors with a pre-trained language model. We expect that by mixing the user's behaviors across different domains, we can exploit the common knowledge encoded in the pre-trained language model to alleviate the problems of data sparsity and cold start problems. Furthermore, we are curious about whether the latest technical advances in nature language processing (NLP) can transfer to the recommendation scenarios.
Improving Transferability of Adversarial Patches on Face Recognition with Generative Models
Jun 29, 2021
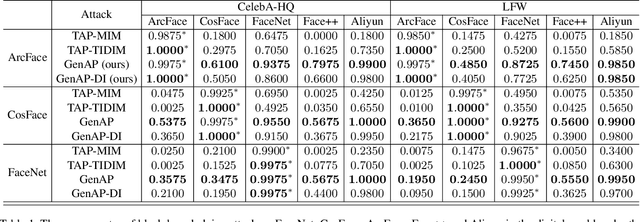
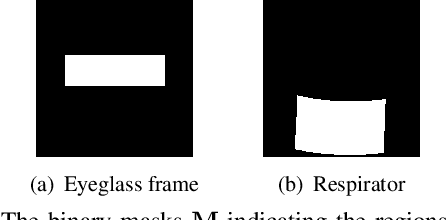
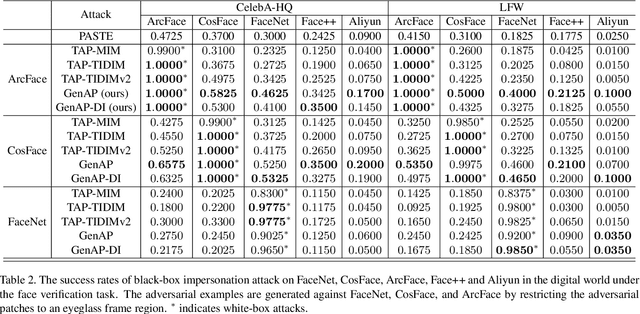
Face recognition is greatly improved by deep convolutional neural networks (CNNs). Recently, these face recognition models have been used for identity authentication in security sensitive applications. However, deep CNNs are vulnerable to adversarial patches, which are physically realizable and stealthy, raising new security concerns on the real-world applications of these models. In this paper, we evaluate the robustness of face recognition models using adversarial patches based on transferability, where the attacker has limited accessibility to the target models. First, we extend the existing transfer-based attack techniques to generate transferable adversarial patches. However, we observe that the transferability is sensitive to initialization and degrades when the perturbation magnitude is large, indicating the overfitting to the substitute models. Second, we propose to regularize the adversarial patches on the low dimensional data manifold. The manifold is represented by generative models pre-trained on legitimate human face images. Using face-like features as adversarial perturbations through optimization on the manifold, we show that the gaps between the responses of substitute models and the target models dramatically decrease, exhibiting a better transferability. Extensive digital world experiments are conducted to demonstrate the superiority of the proposed method in the black-box setting. We apply the proposed method in the physical world as well.
Data-Free Adversarial Perturbations for Practical Black-Box Attack
Mar 03, 2020
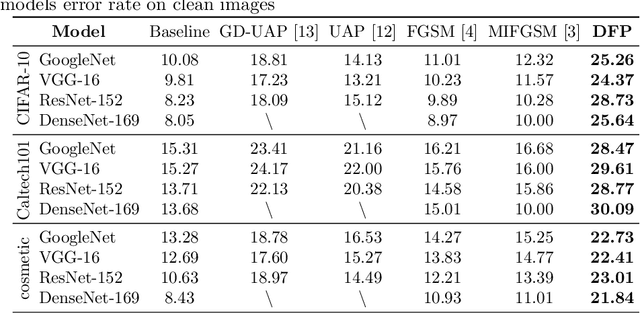

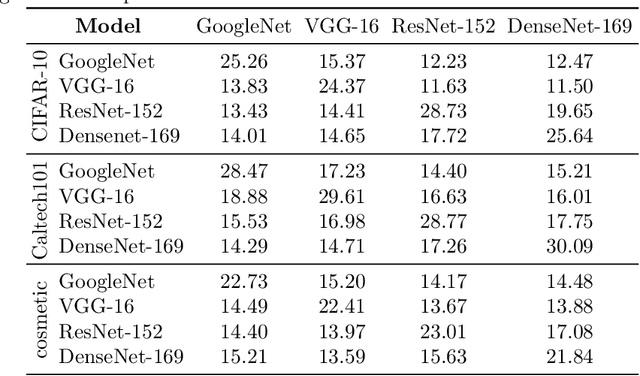
Neural networks are vulnerable to adversarial examples, which are malicious inputs crafted to fool pre-trained models. Adversarial examples often exhibit black-box attacking transferability, which allows that adversarial examples crafted for one model can fool another model. However, existing black-box attack methods require samples from the training data distribution to improve the transferability of adversarial examples across different models. Because of the data dependence, the fooling ability of adversarial perturbations is only applicable when training data are accessible. In this paper, we present a data-free method for crafting adversarial perturbations that can fool a target model without any knowledge about the training data distribution. In the practical setting of a black-box attack scenario where attackers do not have access to target models and training data, our method achieves high fooling rates on target models and outperforms other universal adversarial perturbation methods. Our method empirically shows that current deep learning models are still at risk even when the attackers do not have access to training data.