 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
May 25, 2025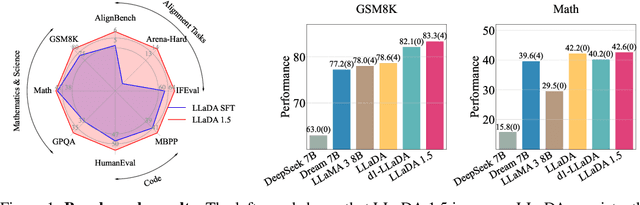
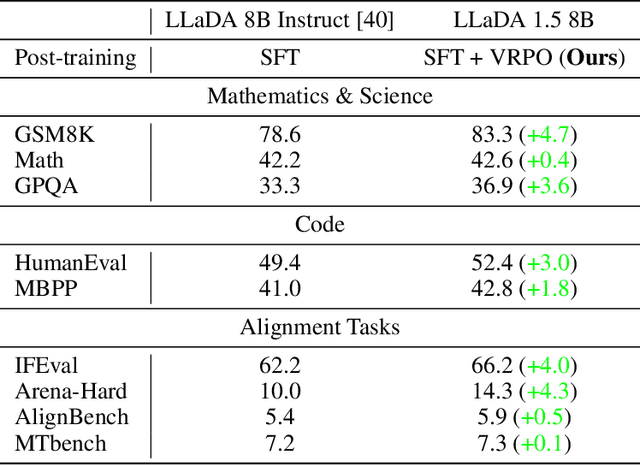
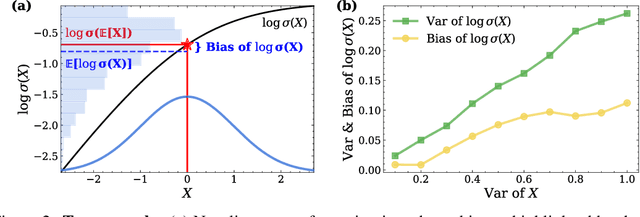
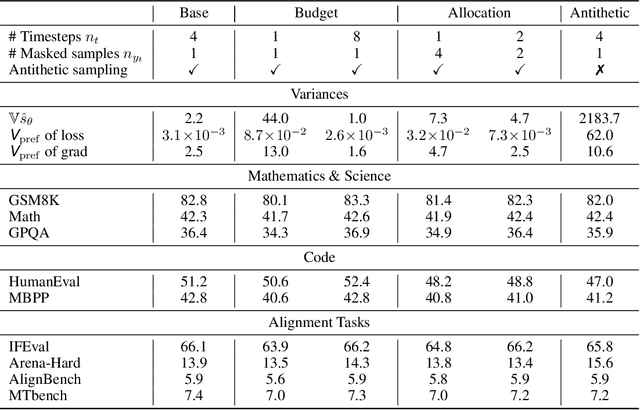
While Masked Diffusion Models (MDMs), such as LLaDA, present a promising paradigm for language modeling, there has been relatively little effort in aligning these models with human preferences via reinforcement learning. The challenge primarily arises from the high variance in Evidence Lower Bound (ELBO)-based likelihood estimates required for preference optimization. To address this issue, we propose Variance-Reduced Preference Optimization (VRPO), a framework that formally analyzes the variance of ELBO estimators and derives bounds on both the bias and variance of preference optimization gradients. Building on this theoretical foundation, we introduce unbiased variance reduction strategies, including optimal Monte Carlo budget allocation and antithetic sampling, that significantly improve the performance of MDM alignment. We demonstrate the effectiveness of VRPO by applying it to LLaDA, and the resulting model, LLaDA 1.5, outperforms its SFT-only predecessor consistently and significantly across mathematical (GSM8K +4.7), code (HumanEval +3.0, MBPP +1.8), and alignment benchmarks (IFEval +4.0, Arena-Hard +4.3). Furthermore, LLaDA 1.5 demonstrates a highly competitive mathematical performance compared to strong language MDMs and ARMs. Project page: https://ml-gsai.github.io/LLaDA-1.5-Demo/.
Short-Path Prompting in LLMs: Analyzing Reasoning Instability and Solutions for Robust Performance
Apr 13, 2025Recent years have witnessed significant progress in large language models' (LLMs) reasoning, which is largely due to the chain-of-thought (CoT) approaches, allowing models to generate intermediate reasoning steps before reaching the final answer. Building on these advances, state-of-the-art LLMs are instruction-tuned to provide long and detailed CoT pathways when responding to reasoning-related questions. However, human beings are naturally cognitive misers and will prompt language models to give rather short responses, thus raising a significant conflict with CoT reasoning. In this paper, we delve into how LLMs' reasoning performance changes when users provide short-path prompts. The results and analysis reveal that language models can reason effectively and robustly without explicit CoT prompts, while under short-path prompting, LLMs' reasoning ability drops significantly and becomes unstable, even on grade-school problems. To address this issue, we propose two approaches: an instruction-guided approach and a fine-tuning approach, both designed to effectively manage the conflict. Experimental results show that both methods achieve high accuracy, providing insights into the trade-off between instruction adherence and reasoning accuracy in current models.
Holistic Capability Preservation: Towards Compact Yet Comprehensive Reasoning Models
Apr 09, 2025This technical report presents Ring-Lite-Distill, a lightweight reasoning model derived from our open-source Mixture-of-Experts (MoE) Large Language Models (LLMs) Ling-Lite. This study demonstrates that through meticulous high-quality data curation and ingenious training paradigms, the compact MoE model Ling-Lite can be further trained to achieve exceptional reasoning capabilities, while maintaining its parameter-efficient architecture with only 2.75 billion activated parameters, establishing an efficient lightweight reasoning architecture. In particular, in constructing this model, we have not merely focused on enhancing advanced reasoning capabilities, exemplified by high-difficulty mathematical problem solving, but rather aimed to develop a reasoning model with more comprehensive competency coverage. Our approach ensures coverage across reasoning tasks of varying difficulty levels while preserving generic capabilities, such as instruction following, tool use, and knowledge retention. We show that, Ring-Lite-Distill's reasoning ability reaches a level comparable to DeepSeek-R1-Distill-Qwen-7B, while its general capabilities significantly surpass those of DeepSeek-R1-Distill-Qwen-7B. The models are accessible at https://huggingface.co/inclusionAI
HyperEditor: Achieving Both Authenticity and Cross-Domain Capability in Image Editing via Hypernetworks
Dec 21, 2023Editing real images authentically while also achieving cross-domain editing remains a challenge. Recent studies have focused on converting real images into latent codes and accomplishing image editing by manipulating these codes. However, merely manipulating the latent codes would constrain the edited images to the generator's image domain, hindering the attainment of diverse editing goals. In response, we propose an innovative image editing method called HyperEditor, which utilizes weight factors generated by hypernetworks to reassign the weights of the pre-trained StyleGAN2's generator. Guided by CLIP's cross-modal image-text semantic alignment, this innovative approach enables us to simultaneously accomplish authentic attribute editing and cross-domain style transfer, a capability not realized in previous methods. Additionally, we ascertain that modifying only the weights of specific layers in the generator can yield an equivalent editing result. Therefore, we introduce an adaptive layer selector, enabling our hypernetworks to autonomously identify the layers requiring output weight factors, which can further improve our hypernetworks' efficiency. Extensive experiments on abundant challenging datasets demonstrate the effectiveness of our method.
When Source-Free Domain Adaptation Meets Label Propagation
Jan 20, 2023



Source-free domain adaptation, where only a pre-trained source model is used to adapt to the target distribution, is a more general approach to achieving domain adaptation. However, it can be challenging to capture the inherent structure of the target features accurately due to the lack of supervised information on the target domain. To tackle this problem, we propose a novel approach called Adaptive Local Transfer (ALT) that tries to achieve efficient feature clustering from the perspective of label propagation. ALT divides the target data into inner and outlier samples based on the adaptive threshold of the learning state, and applies a customized learning strategy to best fits the data property. Specifically, inner samples are utilized for learning intra-class structure thanks to their relatively well-clustered properties. The low-density outlier samples are regularized by input consistency to achieve high accuracy with respect to the ground truth labels. In this way, local clustering can be prevented from forming spurious clusters while effectively propagating label information among subpopulations. Empirical evidence demonstrates that ALT outperforms the state of the arts on three public benchmarks: Office-31, Office-Home, and VisDA.