 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Holistic Capability Preservation: Towards Compact Yet Comprehensive Reasoning Models
Apr 09, 2025This technical report presents Ring-Lite-Distill, a lightweight reasoning model derived from our open-source Mixture-of-Experts (MoE) Large Language Models (LLMs) Ling-Lite. This study demonstrates that through meticulous high-quality data curation and ingenious training paradigms, the compact MoE model Ling-Lite can be further trained to achieve exceptional reasoning capabilities, while maintaining its parameter-efficient architecture with only 2.75 billion activated parameters, establishing an efficient lightweight reasoning architecture. In particular, in constructing this model, we have not merely focused on enhancing advanced reasoning capabilities, exemplified by high-difficulty mathematical problem solving, but rather aimed to develop a reasoning model with more comprehensive competency coverage. Our approach ensures coverage across reasoning tasks of varying difficulty levels while preserving generic capabilities, such as instruction following, tool use, and knowledge retention. We show that, Ring-Lite-Distill's reasoning ability reaches a level comparable to DeepSeek-R1-Distill-Qwen-7B, while its general capabilities significantly surpass those of DeepSeek-R1-Distill-Qwen-7B. The models are accessible at https://huggingface.co/inclusionAI
Deep LG-Track: An Enhanced Localization-Confidence-Guided Multi-Object Tracker
Apr 02, 2025Multi-object tracking plays a crucial role in various applications, such as autonomous driving and security surveillance. This study introduces Deep LG-Track, a novel multi-object tracker that incorporates three key enhancements to improve the tracking accuracy and robustness. First, an adaptive Kalman filter is developed to dynamically update the covariance of measurement noise based on detection confidence and trajectory disappearance. Second, a novel cost matrix is formulated to adaptively fuse motion and appearance information, leveraging localization confidence and detection confidence as weighting factors. Third, a dynamic appearance feature updating strategy is introduced, adjusting the relative weighting of historical and current appearance features based on appearance clarity and localization accuracy. Comprehensive evaluations on the MOT17 and MOT20 datasets demonstrate that the proposed Deep LG-Track consistently outperforms state-of-the-art trackers across multiple performance metrics, highlighting its effectiveness in multi-object tracking tasks.
SD-SLAM: A Semantic SLAM Approach for Dynamic Scenes Based on LiDAR Point Clouds
Feb 28, 2024
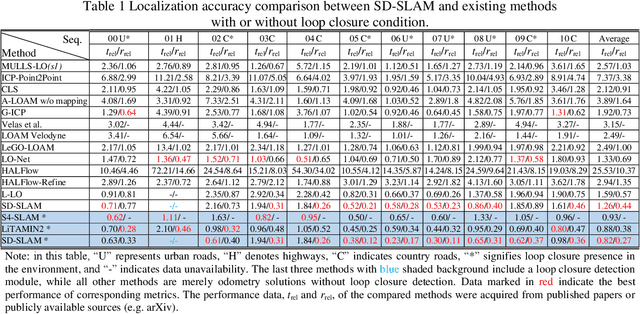


Point cloud maps generated via LiDAR sensors using extensive remotely sensed data are commonly used by autonomous vehicles and robots for localization and navigation. However, dynamic objects contained in point cloud maps not only downgrade localization accuracy and navigation performance but also jeopardize the map quality. In response to this challenge, we propose in this paper a novel semantic SLAM approach for dynamic scenes based on LiDAR point clouds, referred to as SD-SLAM hereafter. The main contributions of this work are in three aspects: 1) introducing a semantic SLAM framework dedicatedly for dynamic scenes based on LiDAR point clouds, 2) Employing semantics and Kalman filtering to effectively differentiate between dynamic and semi-static landmarks, and 3) Making full use of semi-static and pure static landmarks with semantic information in the SD-SLAM process to improve localization and mapping performance. To evaluate the proposed SD-SLAM, tests were conducted using the widely adopted KITTI odometry dataset. Results demonstrate that the proposed SD-SLAM effectively mitigates the adverse effects of dynamic objects on SLAM, improving vehicle localization and mapping performance in dynamic scenes, and simultaneously constructing a static semantic map with multiple semantic classes for enhanced environment understanding.