 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
SD-SLAM: A Semantic SLAM Approach for Dynamic Scenes Based on LiDAR Point Clouds
Feb 28, 2024
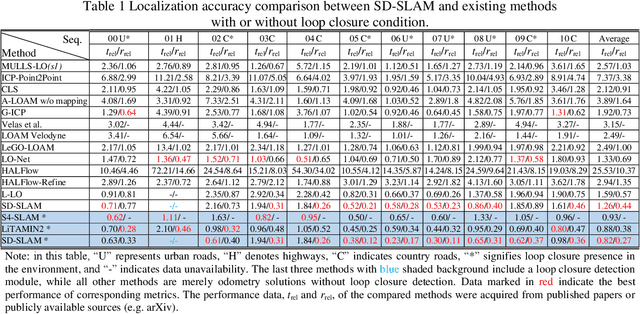


Point cloud maps generated via LiDAR sensors using extensive remotely sensed data are commonly used by autonomous vehicles and robots for localization and navigation. However, dynamic objects contained in point cloud maps not only downgrade localization accuracy and navigation performance but also jeopardize the map quality. In response to this challenge, we propose in this paper a novel semantic SLAM approach for dynamic scenes based on LiDAR point clouds, referred to as SD-SLAM hereafter. The main contributions of this work are in three aspects: 1) introducing a semantic SLAM framework dedicatedly for dynamic scenes based on LiDAR point clouds, 2) Employing semantics and Kalman filtering to effectively differentiate between dynamic and semi-static landmarks, and 3) Making full use of semi-static and pure static landmarks with semantic information in the SD-SLAM process to improve localization and mapping performance. To evaluate the proposed SD-SLAM, tests were conducted using the widely adopted KITTI odometry dataset. Results demonstrate that the proposed SD-SLAM effectively mitigates the adverse effects of dynamic objects on SLAM, improving vehicle localization and mapping performance in dynamic scenes, and simultaneously constructing a static semantic map with multiple semantic classes for enhanced environment understanding.
L-LO: Enhancing Pose Estimation Precision via a Landmark-Based LiDAR Odometry
Dec 28, 2023The majority of existing LiDAR odometry solutions are based on simple geometric features such as points, lines or planes which cannot fully reflect the characteristics of surrounding environments. In this study, we propose a novel LiDAR odometry which effectively utilizes the overall exterior characteristics of environmental landmarks. The vehicle pose estimation is accomplished by means of two sequential pose estimation stages, namely, horizontal pose estimation and vertical pose estimation. To achieve effective landmark registration, a comprehensive index is proposed to evaluate the level of similarity between landmarks. This index takes into account two crucial aspects of landmarks, namely, dimension and shape in evaluating their similarity. To assess the performance of the proposed algorithm, we utilize the widely recognized KITTI dataset as well as experimental data collected by an unmanned ground vehicle platform. Both graphical and numerical results indicate that our algorithm outperforms leading LiDAR odometry solutions in terms of positioning accuracy.