 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
VoiceShop: A Unified Speech-to-Speech Framework for Identity-Preserving Zero-Shot Voice Editing
Apr 11, 2024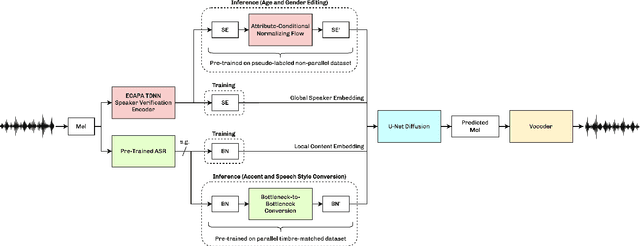

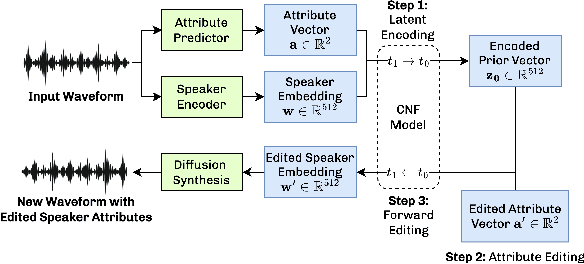
We present VoiceShop, a novel speech-to-speech framework that can modify multiple attributes of speech, such as age, gender, accent, and speech style, in a single forward pass while preserving the input speaker's timbre. Previous works have been constrained to specialized models that can only edit these attributes individually and suffer from the following pitfalls: the magnitude of the conversion effect is weak, there is no zero-shot capability for out-of-distribution speakers, or the synthesized outputs exhibit undesirable timbre leakage. Our work proposes solutions for each of these issues in a simple modular framework based on a conditional diffusion backbone model with optional normalizing flow-based and sequence-to-sequence speaker attribute-editing modules, whose components can be combined or removed during inference to meet a wide array of tasks without additional model finetuning. Audio samples are available at \url{https://voiceshopai.github.io}.